 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCI-Work: Benchmarking Contextual Integrity in Enterprise LLM Agents
Apr 23, 2026Enterprise LLM agents can dramatically improve workplace productivity, but their core capability, retrieving and using internal context to act on a user's behalf, also creates new risks for sensitive information leakage. We introduce CI-Work, a Contextual Integrity (CI)-grounded benchmark that simulates enterprise workflows across five information-flow directions and evaluates whether agents can convey essential content while withholding sensitive context in dense retrieval settings. Our evaluation of frontier models reveals that privacy failures are prevalent (violation rates range from 15.8%-50.9%, with leakage reaching up to 26.7%) and uncovers a counterintuitive trade-off critical for industrial deployment: higher task utility often correlates with increased privacy violations. Moreover, the massive scale of enterprise data and potential user behavior further amplify this vulnerability. Simply increasing model size or reasoning depth fails to address the problem. We conclude that safeguarding enterprise workflows requires a paradigm shift, moving beyond model-centric scaling toward context-centric architectures.
Contrastive Attribution in the Wild: An Interpretability Analysis of LLM Failures on Realistic Benchmarks
Apr 20, 2026Interpretability tools are increasingly used to analyze failures of Large Language Models (LLMs), yet prior work largely focuses on short prompts or toy settings, leaving their behavior on commonly used benchmarks underexplored. To address this gap, we study contrastive, LRP-based attribution as a practical tool for analyzing LLM failures in realistic settings. We formulate failure analysis as \textit{contrastive attribution}, attributing the logit difference between an incorrect output token and a correct alternative to input tokens and internal model states, and introduce an efficient extension that enables construction of cross-layer attribution graphs for long-context inputs. Using this framework, we conduct a systematic empirical study across benchmarks, comparing attribution patterns across datasets, model sizes, and training checkpoints. Our results show that this token-level contrastive attribution can yield informative signals in some failure cases, but is not universally applicable, highlighting both its utility and its limitations for realistic LLM failure analysis. Our code is available at: https://aka.ms/Debug-XAI.
A Tale of Two Graphs: Separating Knowledge Exploration from Outline Structure for Open-Ended Deep Research
Feb 14, 2026Open-Ended Deep Research (OEDR) pushes LLM agents beyond short-form QA toward long-horizon workflows that iteratively search, connect, and synthesize evidence into structured reports. However, existing OEDR agents largely follow either linear ``search-then-generate'' accumulation or outline-centric planning. The former suffers from lost-in-the-middle failures as evidence grows, while the latter relies on the LLM to implicitly infer knowledge gaps from the outline alone, providing weak supervision for identifying missing relations and triggering targeted exploration. We present DualGraph memory, an architecture that separates what the agent knows from how it writes. DualGraph maintains two co-evolving graphs: an Outline Graph (OG), and a Knowledge Graph (KG), a semantic memory that stores fine-grained knowledge units, including core entities, concepts, and their relations. By analyzing the KG topology together with structural signals from the OG, DualGraph generates targeted search queries, enabling more efficient and comprehensive iterative knowledge-driven exploration and refinement. Across DeepResearch Bench, DeepResearchGym, and DeepConsult, DualGraph consistently outperforms state-of-the-art baselines in report depth, breadth, and factual grounding; for example, it reaches a 53.08 RACE score on DeepResearch Bench with GPT-5. Moreover, ablation studies confirm the central role of the dual-graph design.
MEETING DELEGATE: Benchmarking LLMs on Attending Meetings on Our Behalf
Feb 05, 2025In contemporary workplaces, meetings are essential for exchanging ideas and ensuring team alignment but often face challenges such as time consumption, scheduling conflicts, and inefficient participation. Recent advancements in Large Language Models (LLMs) have demonstrated their strong capabilities in natural language generation and reasoning, prompting the question: can LLMs effectively delegate participants in meetings? To explore this, we develop a prototype LLM-powered meeting delegate system and create a comprehensive benchmark using real meeting transcripts. Our evaluation reveals that GPT-4/4o maintain balanced performance between active and cautious engagement strategies. In contrast, Gemini 1.5 Pro tends to be more cautious, while Gemini 1.5 Flash and Llama3-8B/70B display more active tendencies. Overall, about 60\% of responses address at least one key point from the ground-truth. However, improvements are needed to reduce irrelevant or repetitive content and enhance tolerance for transcription errors commonly found in real-world settings. Additionally, we implement the system in practical settings and collect real-world feedback from demos. Our findings underscore the potential and challenges of utilizing LLMs as meeting delegates, offering valuable insights into their practical application for alleviating the burden of meetings.
Enabling Autonomic Microservice Management through Self-Learning Agents
Jan 31, 2025



The increasing complexity of modern software systems necessitates robust autonomic self-management capabilities. While Large Language Models (LLMs) demonstrate potential in this domain, they often face challenges in adapting their general knowledge to specific service contexts. To address this limitation, we propose ServiceOdyssey, a self-learning agent system that autonomously manages microservices without requiring prior knowledge of service-specific configurations. By leveraging curriculum learning principles and iterative exploration, ServiceOdyssey progressively develops a deep understanding of operational environments, reducing dependence on human input or static documentation. A prototype built with the Sock Shop microservice demonstrates the potential of this approach for autonomic microservice management.
Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval
Dec 15, 2024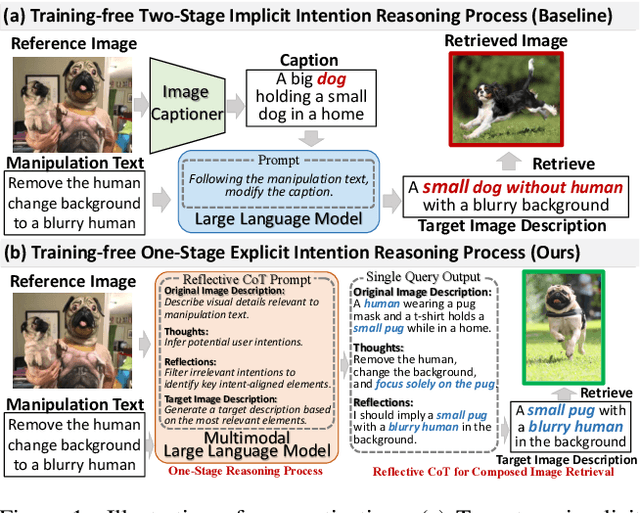
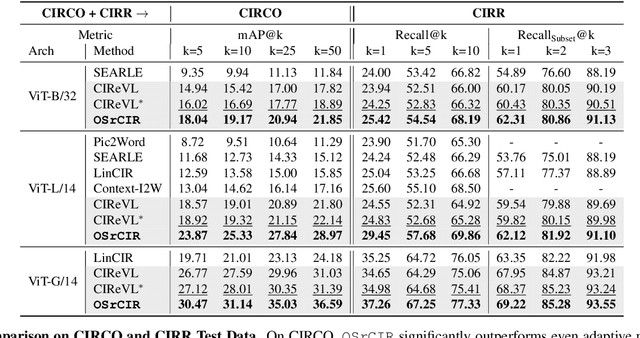
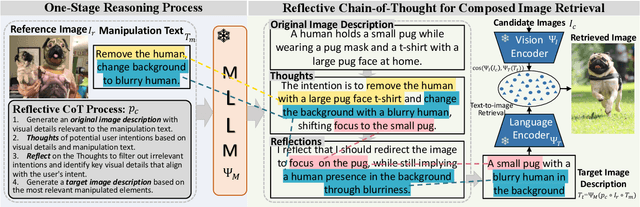
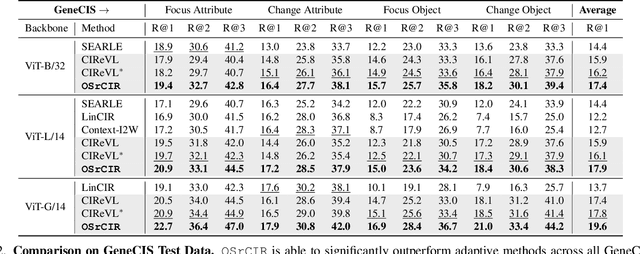
Composed Image Retrieval (CIR) aims to retrieve target images that closely resemble a reference image while integrating user-specified textual modifications, thereby capturing user intent more precisely. Existing training-free zero-shot CIR (ZS-CIR) methods often employ a two-stage process: they first generate a caption for the reference image and then use Large Language Models for reasoning to obtain a target description. However, these methods suffer from missing critical visual details and limited reasoning capabilities, leading to suboptimal retrieval performance. To address these challenges, we propose a novel, training-free one-stage method, One-Stage Reflective Chain-of-Thought Reasoning for ZS-CIR (OSrCIR), which employs Multimodal Large Language Models to retain essential visual information in a single-stage reasoning process, eliminating the information loss seen in two-stage methods. Our Reflective Chain-of-Thought framework further improves interpretative accuracy by aligning manipulation intent with contextual cues from reference images. OSrCIR achieves performance gains of 1.80% to 6.44% over existing training-free methods across multiple tasks, setting new state-of-the-art results in ZS-CIR and enhancing its utility in vision-language applications. Our code will be available at https://github.com/Pter61/osrcir2024/.
Sharingan: Extract User Action Sequence from Desktop Recordings
Nov 13, 2024Video recordings of user activities, particularly desktop recordings, offer a rich source of data for understanding user behaviors and automating processes. However, despite advancements in Vision-Language Models (VLMs) and their increasing use in video analysis, extracting user actions from desktop recordings remains an underexplored area. This paper addresses this gap by proposing two novel VLM-based methods for user action extraction: the Direct Frame-Based Approach (DF), which inputs sampled frames directly into VLMs, and the Differential Frame-Based Approach (DiffF), which incorporates explicit frame differences detected via computer vision techniques. We evaluate these methods using a basic self-curated dataset and an advanced benchmark adapted from prior work. Our results show that the DF approach achieves an accuracy of 70% to 80% in identifying user actions, with the extracted action sequences being re-playable though Robotic Process Automation. We find that while VLMs show potential, incorporating explicit UI changes can degrade performance, making the DF approach more reliable. This work represents the first application of VLMs for extracting user action sequences from desktop recordings, contributing new methods, benchmarks, and insights for future research.
Navigating the Unknown: A Chat-Based Collaborative Interface for Personalized Exploratory Tasks
Oct 31, 2024



The rise of large language models (LLMs) has revolutionized user interactions with knowledge-based systems, enabling chatbots to synthesize vast amounts of information and assist with complex, exploratory tasks. However, LLM-based chatbots often struggle to provide personalized support, particularly when users start with vague queries or lack sufficient contextual information. This paper introduces the Collaborative Assistant for Personalized Exploration (CARE), a system designed to enhance personalization in exploratory tasks by combining a multi-agent LLM framework with a structured user interface. CARE's interface consists of a Chat Panel, Solution Panel, and Needs Panel, enabling iterative query refinement and dynamic solution generation. The multi-agent framework collaborates to identify both explicit and implicit user needs, delivering tailored, actionable solutions. In a within-subject user study with 22 participants, CARE was consistently preferred over a baseline LLM chatbot, with users praising its ability to reduce cognitive load, inspire creativity, and provide more tailored solutions. Our findings highlight CARE's potential to transform LLM-based systems from passive information retrievers to proactive partners in personalized problem-solving and exploration.
Turn Every Application into an Agent: Towards Efficient Human-Agent-Computer Interaction with API-First LLM-Based Agents
Sep 25, 2024Multimodal large language models (MLLMs) have enabled LLM-based agents to directly interact with application user interfaces (UIs), enhancing agents' performance in complex tasks. However, these agents often suffer from high latency and low reliability due to the extensive sequential UI interactions. To address this issue, we propose AXIS, a novel LLM-based agents framework prioritize actions through application programming interfaces (APIs) over UI actions. This framework also facilitates the creation and expansion of APIs through automated exploration of applications. Our experiments on Office Word demonstrate that AXIS reduces task completion time by 65%-70% and cognitive workload by 38%-53%, while maintaining accuracy of 97%-98% compare to humans. Our work contributes to a new human-agent-computer interaction (HACI) framework and a fresh UI design principle for application providers in the era of LLMs. It also explores the possibility of turning every applications into agents, paving the way towards an agent-centric operating system (Agent OS).
The Vision of Autonomic Computing: Can LLMs Make It a Reality?
Jul 19, 2024



The Vision of Autonomic Computing (ACV), proposed over two decades ago, envisions computing systems that self-manage akin to biological organisms, adapting seamlessly to changing environments. Despite decades of research, achieving ACV remains challenging due to the dynamic and complex nature of modern computing systems. Recent advancements in Large Language Models (LLMs) offer promising solutions to these challenges by leveraging their extensive knowledge, language understanding, and task automation capabilities. This paper explores the feasibility of realizing ACV through an LLM-based multi-agent framework for microservice management. We introduce a five-level taxonomy for autonomous service maintenance and present an online evaluation benchmark based on the Sock Shop microservice demo project to assess our framework's performance. Our findings demonstrate significant progress towards achieving Level 3 autonomy, highlighting the effectiveness of LLMs in detecting and resolving issues within microservice architectures. This study contributes to advancing autonomic computing by pioneering the integration of LLMs into microservice management frameworks, paving the way for more adaptive and self-managing computing systems. The code will be made available at https://aka.ms/ACV-LLM.