 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
May 28, 2025Leveraging multimodal large models for image segmentation has become a prominent research direction. However, existing approaches typically rely heavily on manually annotated datasets that include explicit reasoning processes, which are costly and time-consuming to produce. Recent advances suggest that reinforcement learning (RL) can endow large models with reasoning capabilities without requiring such reasoning-annotated data. In this paper, we propose SAM-R1, a novel framework that enables multimodal large models to perform fine-grained reasoning in image understanding tasks. Our approach is the first to incorporate fine-grained segmentation settings during the training of multimodal reasoning models. By integrating task-specific, fine-grained rewards with a tailored optimization objective, we further enhance the model's reasoning and segmentation alignment. We also leverage the Segment Anything Model (SAM) as a strong and flexible reward provider to guide the learning process. With only 3k training samples, SAM-R1 achieves strong performance across multiple benchmarks, demonstrating the effectiveness of reinforcement learning in equipping multimodal models with segmentation-oriented reasoning capabilities.
AKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models
Jan 25, 2025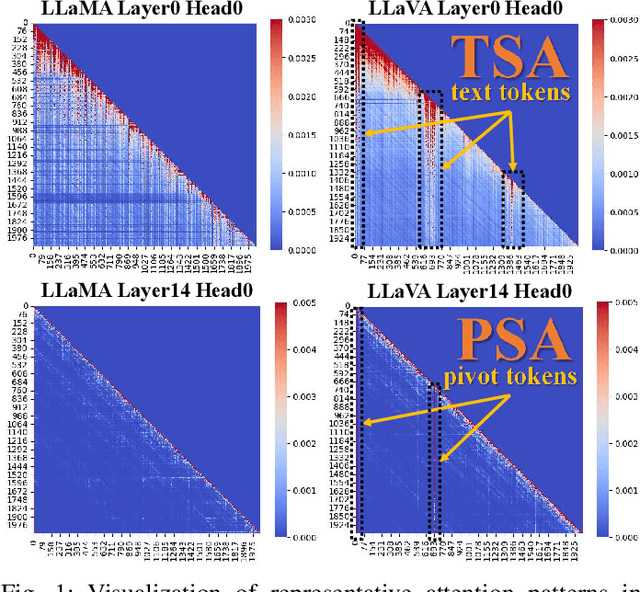
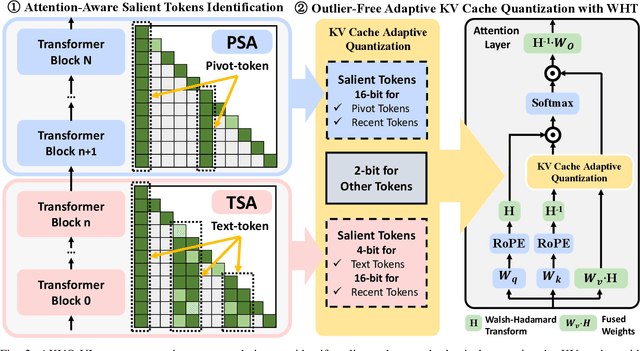
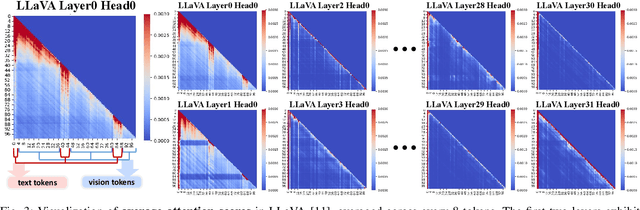
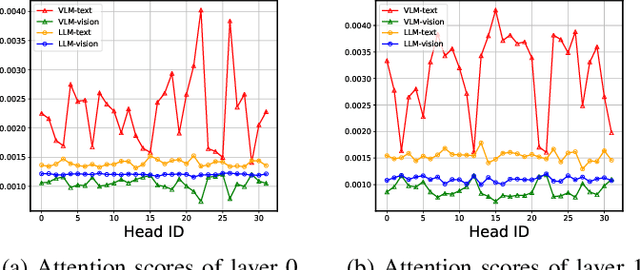
Vision-language models (VLMs) show remarkable performance in multimodal tasks. However, excessively long multimodal inputs lead to oversized Key-Value (KV) caches, resulting in significant memory consumption and I/O bottlenecks. Previous KV quantization methods for Large Language Models (LLMs) may alleviate these issues but overlook the attention saliency differences of multimodal tokens, resulting in suboptimal performance. In this paper, we investigate the attention-aware token saliency patterns in VLM and propose AKVQ-VL. AKVQ-VL leverages the proposed Text-Salient Attention (TSA) and Pivot-Token-Salient Attention (PSA) patterns to adaptively allocate bit budgets. Moreover, achieving extremely low-bit quantization requires effectively addressing outliers in KV tensors. AKVQ-VL utilizes the Walsh-Hadamard transform (WHT) to construct outlier-free KV caches, thereby reducing quantization difficulty. Evaluations of 2-bit quantization on 12 long-context and multimodal tasks demonstrate that AKVQ-VL maintains or even improves accuracy, outperforming LLM-oriented methods. AKVQ-VL can reduce peak memory usage by 2.13x, support up to 3.25x larger batch sizes and 2.46x throughput.
Densely Connected Parameter-Efficient Tuning for Referring Image Segmentation
Jan 15, 2025In the domain of computer vision, Parameter-Efficient Tuning (PET) is increasingly replacing the traditional paradigm of pre-training followed by full fine-tuning. PET is particularly favored for its effectiveness in large foundation models, as it streamlines transfer learning costs and optimizes hardware utilization. However, the current PET methods are mainly designed for single-modal optimization. While some pioneering studies have undertaken preliminary explorations, they still remain at the level of aligned encoders (e.g., CLIP) and lack exploration of misaligned encoders. These methods show sub-optimal performance with misaligned encoders, as they fail to effectively align the multimodal features during fine-tuning. In this paper, we introduce DETRIS, a parameter-efficient tuning framework designed to enhance low-rank visual feature propagation by establishing dense interconnections between each layer and all preceding layers, which enables effective cross-modal feature interaction and adaptation to misaligned encoders. We also suggest using text adapters to improve textual features. Our simple yet efficient approach greatly surpasses state-of-the-art methods with 0.9% to 1.8% backbone parameter updates, evaluated on challenging benchmarks. Our project is available at \url{https://github.com/jiaqihuang01/DETRIS}.
Sharingan: Extract User Action Sequence from Desktop Recordings
Nov 13, 2024Video recordings of user activities, particularly desktop recordings, offer a rich source of data for understanding user behaviors and automating processes. However, despite advancements in Vision-Language Models (VLMs) and their increasing use in video analysis, extracting user actions from desktop recordings remains an underexplored area. This paper addresses this gap by proposing two novel VLM-based methods for user action extraction: the Direct Frame-Based Approach (DF), which inputs sampled frames directly into VLMs, and the Differential Frame-Based Approach (DiffF), which incorporates explicit frame differences detected via computer vision techniques. We evaluate these methods using a basic self-curated dataset and an advanced benchmark adapted from prior work. Our results show that the DF approach achieves an accuracy of 70% to 80% in identifying user actions, with the extracted action sequences being re-playable though Robotic Process Automation. We find that while VLMs show potential, incorporating explicit UI changes can degrade performance, making the DF approach more reliable. This work represents the first application of VLMs for extracting user action sequences from desktop recordings, contributing new methods, benchmarks, and insights for future research.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
Dual-Channel Reliable Breast Ultrasound Image Classification Based on Explainable Attribution and Uncertainty Quantification
Jan 08, 2024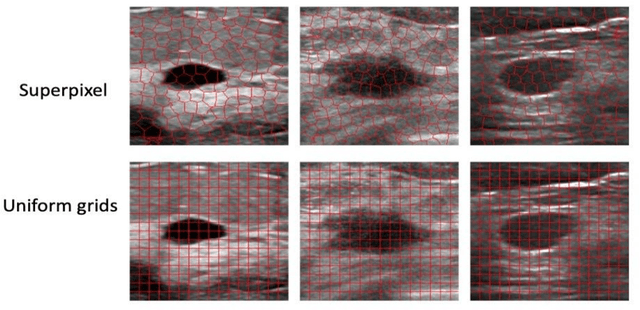

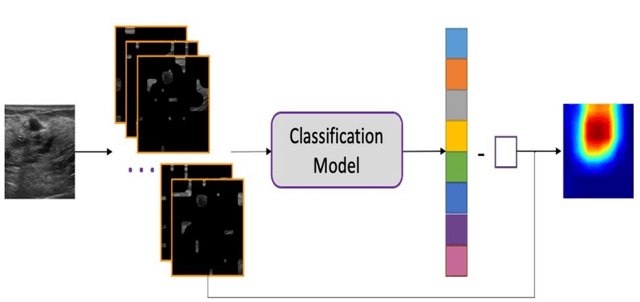

This paper focuses on the classification task of breast ultrasound images and researches on the reliability measurement of classification results. We proposed a dual-channel evaluation framework based on the proposed inference reliability and predictive reliability scores. For the inference reliability evaluation, human-aligned and doctor-agreed inference rationales based on the improved feature attribution algorithm SP-RISA are gracefully applied. Uncertainty quantification is used to evaluate the predictive reliability via the Test Time Enhancement. The effectiveness of this reliability evaluation framework has been verified on our breast ultrasound clinical dataset YBUS, and its robustness is verified on the public dataset BUSI. The expected calibration errors on both datasets are significantly lower than traditional evaluation methods, which proves the effectiveness of our proposed reliability measurement.
BSM loss: A superior way in modeling aleatory uncertainty of fine_grained classification
Jun 09, 2022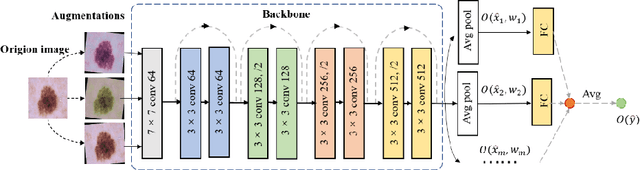
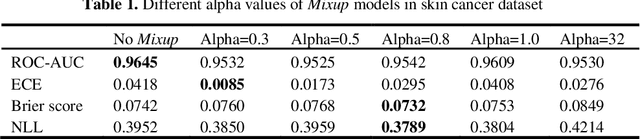
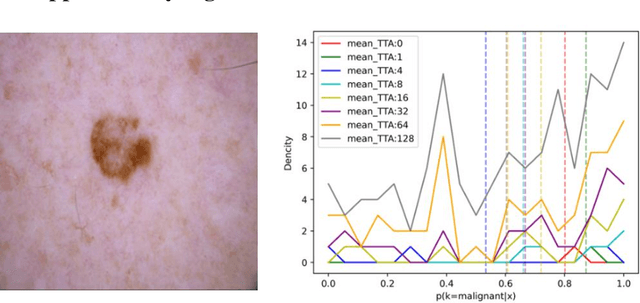
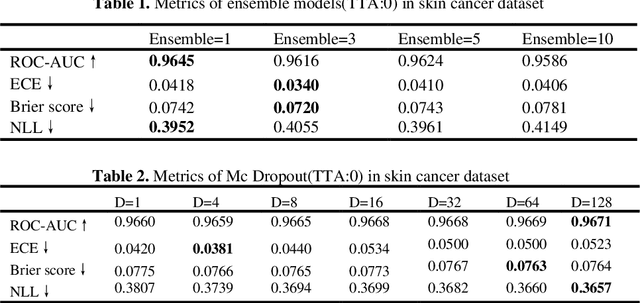
Artificial intelligence(AI)-assisted method had received much attention in the risk field such as disease diagnosis. Different from the classification of disease types, it is a fine-grained task to classify the medical images as benign or malignant. However, most research only focuses on improving the diagnostic accuracy and ignores the evaluation of model reliability, which limits its clinical application. For clinical practice, calibration presents major challenges in the low-data regime extremely for over-parametrized models and inherent noises. In particular, we discovered that modeling data-dependent uncertainty is more conducive to confidence calibrations. Compared with test-time augmentation(TTA), we proposed a modified Bootstrapping loss(BS loss) function with Mixup data augmentation strategy that can better calibrate predictive uncertainty and capture data distribution transformation without additional inference time. Our experiments indicated that BS loss with Mixup(BSM) model can halve the Expected Calibration Error(ECE) compared to standard data augmentation, deep ensemble and MC dropout. The correlation between uncertainty and similarity of in-domain data is up to -0.4428 under the BSM model. Additionally, the BSM model is able to perceive the semantic distance of out-of-domain data, demonstrating high potential in real-world clinical practice.
MIPR:Automatic Annotation of Medical Images with Pixel Rearrangement
Apr 22, 2022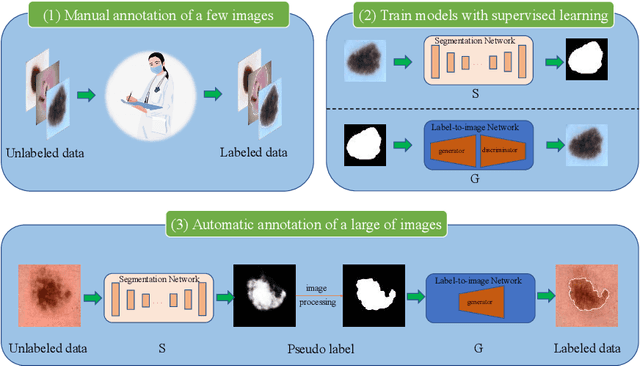
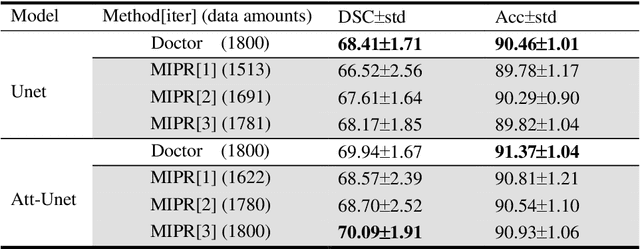

Most of the state-of-the-art semantic segmentation reported in recent years is based on fully supervised deep learning in the medical domain. How?ever, the high-quality annotated datasets require intense labor and domain knowledge, consuming enormous time and cost. Previous works that adopt semi?supervised and unsupervised learning are proposed to address the lack of anno?tated data through assisted training with unlabeled data and achieve good perfor?mance. Still, these methods can not directly get the image annotation as doctors do. In this paper, inspired by self-training of semi-supervised learning, we pro?pose a novel approach to solve the lack of annotated data from another angle, called medical image pixel rearrangement (short in MIPR). The MIPR combines image-editing and pseudo-label technology to obtain labeled data. As the number of iterations increases, the edited image is similar to the original image, and the labeled result is similar to the doctor annotation. Therefore, the MIPR is to get labeled pairs of data directly from amounts of unlabled data with pixel rearrange?ment, which is implemented with a designed conditional Generative Adversarial Networks and a segmentation network. Experiments on the ISIC18 show that the effect of the data annotated by our method for segmentation task is is equal to or even better than that of doctors annotations
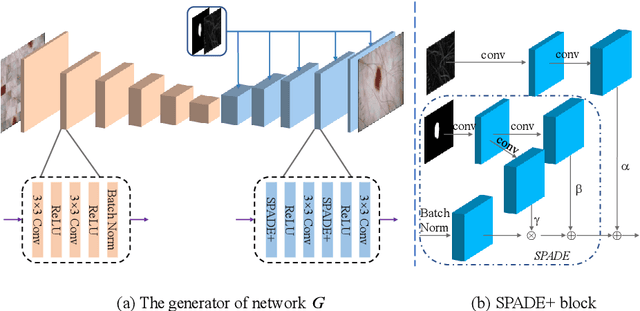
Soft-CP: A Credible and Effective Data Augmentation for Semantic Segmentation of Medical Lesions
Mar 20, 2022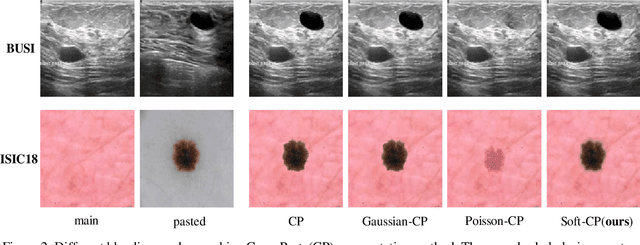

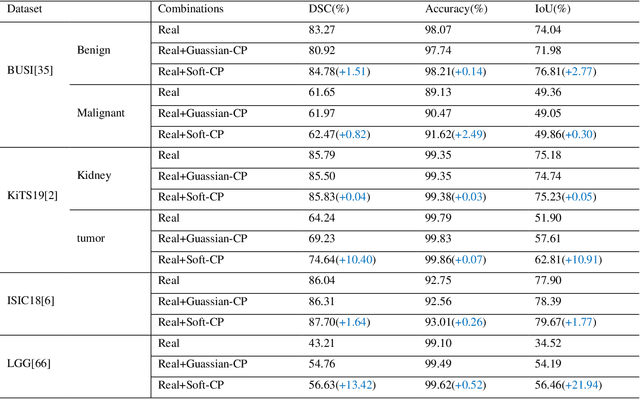
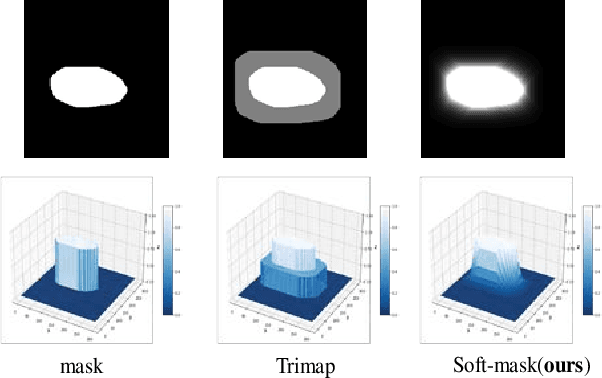
The medical datasets are usually faced with the problem of scarcity and data imbalance. Moreover, annotating large datasets for semantic segmentation of medical lesions is domain-knowledge and time-consuming. In this paper, we propose a new object-blend method(short in soft-CP) that combines the Copy-Paste augmentation method for semantic segmentation of medical lesions offline, ensuring the correct edge information around the lession to solve the issue above-mentioned. We proved the method's validity with several datasets in different imaging modalities. In our experiments on the KiTS19[2] dataset, Soft-CP outperforms existing medical lesions synthesis approaches. The Soft-CP augementation provides gains of +26.5% DSC in the low data regime(10% of data) and +10.2% DSC in the high data regime(all of data), In offline training data, the ratio of real images to synthetic images is 3:1.
Cognitive Explainers of Graph Neural Networks Based on Medical Concepts
Jan 19, 2022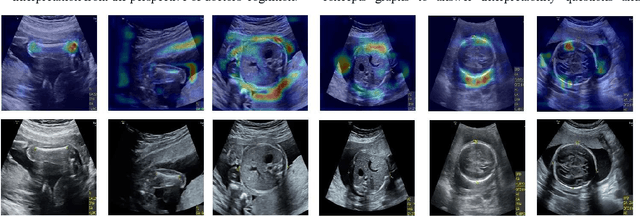

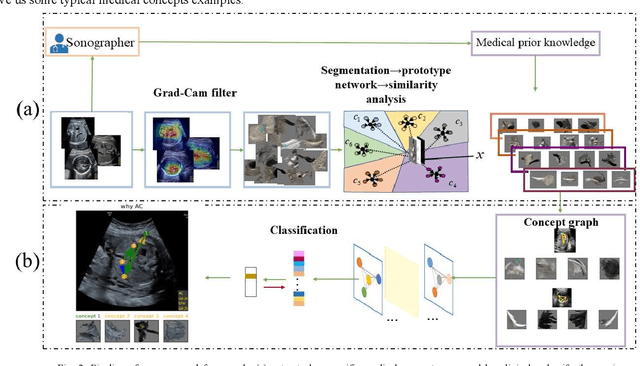
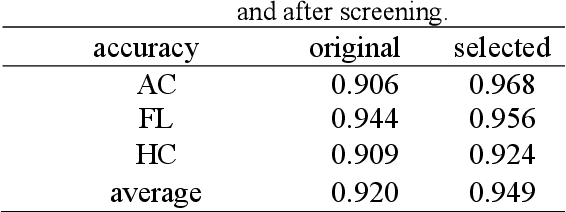
Although deep neural networks (DNN) have achieved state-of-the-art performance in various fields, some unexpected errors are often found in the neural network, which is very dangerous for some tasks requiring high reliability and high security.The non-transparency and unexplainably of CNN still limit its application in many fields, such as medical care and finance. Despite current studies that have been committed to visualizing the decision process of DNN, most of these methods focus on the low level and do not take into account the prior knowledge of medicine.In this work, we propose an interpretable framework based on key medical concepts, enabling CNN to explain from the perspective of doctors' cognition.We propose an interpretable automatic recognition framework for the ultrasonic standard plane, which uses a concept-based graph convolutional neural network to construct the relationships between key medical concepts, to obtain an interpretation consistent with a doctor's cognition.