 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models
Jan 25, 2025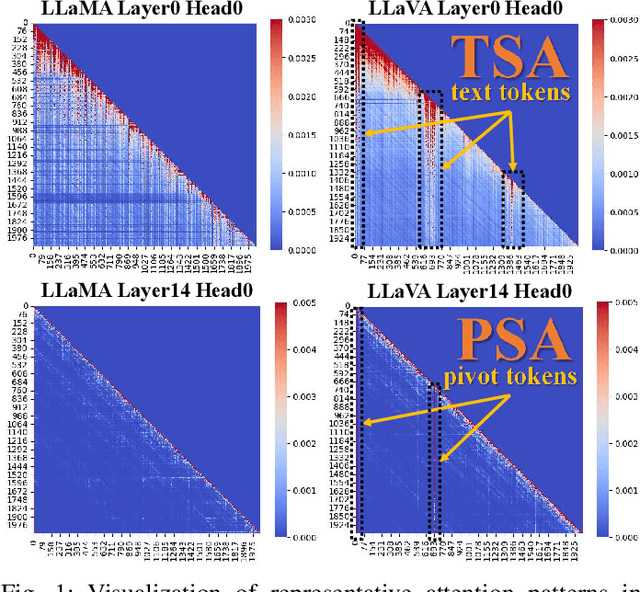
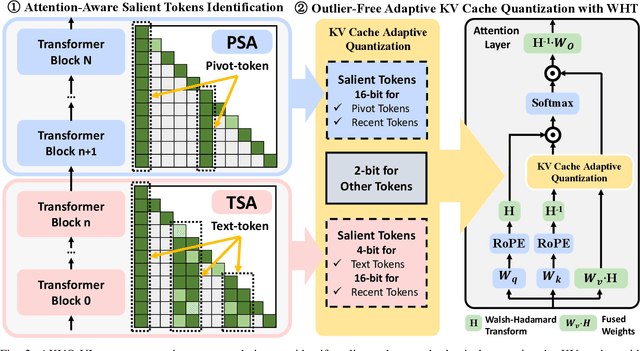
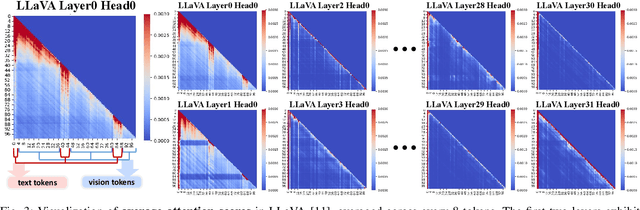
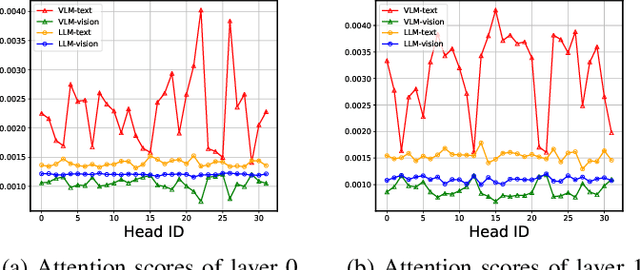
Vision-language models (VLMs) show remarkable performance in multimodal tasks. However, excessively long multimodal inputs lead to oversized Key-Value (KV) caches, resulting in significant memory consumption and I/O bottlenecks. Previous KV quantization methods for Large Language Models (LLMs) may alleviate these issues but overlook the attention saliency differences of multimodal tokens, resulting in suboptimal performance. In this paper, we investigate the attention-aware token saliency patterns in VLM and propose AKVQ-VL. AKVQ-VL leverages the proposed Text-Salient Attention (TSA) and Pivot-Token-Salient Attention (PSA) patterns to adaptively allocate bit budgets. Moreover, achieving extremely low-bit quantization requires effectively addressing outliers in KV tensors. AKVQ-VL utilizes the Walsh-Hadamard transform (WHT) to construct outlier-free KV caches, thereby reducing quantization difficulty. Evaluations of 2-bit quantization on 12 long-context and multimodal tasks demonstrate that AKVQ-VL maintains or even improves accuracy, outperforming LLM-oriented methods. AKVQ-VL can reduce peak memory usage by 2.13x, support up to 3.25x larger batch sizes and 2.46x throughput.
LDPM: Towards undersampled MRI reconstruction with MR-VAE and Latent Diffusion Prior
Nov 05, 2024



Diffusion model, as a powerful generative model, has found a wide range of applications including MRI reconstruction. However, most existing diffusion model-based MRI reconstruction methods operate directly in pixel space, which makes their optimization and inference computationally expensive. Latent diffusion models were introduced to address this problem in natural image processing, but directly applying them to MRI reconstruction still faces many challenges, including the lack of control over the generated results, the adaptability of Variational AutoEncoder (VAE) to MRI, and the exploration of applicable data consistency in latent space. To address these challenges, a Latent Diffusion Prior based undersampled MRI reconstruction (LDPM) method is proposed. A sketcher module is utilized to provide appropriate control and balance the quality and fidelity of the reconstructed MR images. A VAE adapted for MRI tasks (MR-VAE) is explored, which can serve as the backbone for future MR-related tasks. Furthermore, a variation of the DDIM sampler, called the Dual-Stage Sampler, is proposed to achieve high-fidelity reconstruction in the latent space. The proposed method achieves competitive results on fastMRI datasets, and the effectiveness of each module is demonstrated in ablation experiments.