 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFP: Speculative Decoding with FIT-Pruned Models for Training-Free and Plug-and-Play LLM Acceleration
Feb 05, 2026Large language models (LLMs) underpin interactive multimedia applications such as captioning, retrieval, recommendation, and creative content generation, yet their autoregressive decoding incurs substantial latency. Speculative decoding reduces latency using a lightweight draft model, but deployment is often limited by the cost and complexity of acquiring, tuning, and maintaining an effective draft model. Recent approaches usually require auxiliary training or specialization, and even training-free methods incur costly search or optimization. We propose SDFP, a fully training-free and plug-and-play framework that builds the draft model via Fisher Information Trace (FIT)-based layer pruning of a given LLM. Using layer sensitivity as a proxy for output perturbation, SDFP removes low-impact layers to obtain a compact draft while preserving compatibility with the original model for standard speculative verification. SDFP needs no additional training, hyperparameter tuning, or separately maintained drafts, enabling rapid, deployment-friendly draft construction. Across benchmarks, SDFP delivers 1.32x-1.5x decoding speedup without altering the target model's output distribution, supporting low-latency multimedia applications.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Jan 03, 2026Learning-based 3D visual geometry models have benefited substantially from large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention for strong streaming reconstruction, but suffers from unbounded KV cache growth, leading to escalating memory consumption and inference latency as input frames accumulate. We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification, enabling a fixed memory budget. Leveraging the unique distribution of KV tensors, we incorporate KV quantization to further reduce memory consumption. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42$\times$ and accelerating inference by 5.48$\times$, enabling scalable and practical streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.
DoPE: Denoising Rotary Position Embedding
Nov 12, 2025Rotary Position Embedding (RoPE) in Transformer models has inherent limits that weaken length extrapolation. We reinterpret the attention map with positional encoding as a noisy feature map, and propose Denoising Positional Encoding (DoPE), a training-free method based on truncated matrix entropy to detect outlier frequency bands in the feature map. Leveraging the noise characteristics of the feature map, we further reparameterize it with a parameter-free Gaussian distribution to achieve robust extrapolation. Our method theoretically reveals the underlying cause of the attention sink phenomenon and its connection to truncated matrix entropy. Experiments on needle-in-a-haystack and many-shot in-context learning tasks demonstrate that DoPE significantly improves retrieval accuracy and reasoning stability across extended contexts (up to 64K tokens). The results show that the denoising strategy for positional embeddings effectively mitigates attention sinks and restores balanced attention patterns, providing a simple yet powerful solution for improving length generalization. Our project page is Project: https://The-physical-picture-of-LLMs.github.io
AKVQ-VL: Attention-Aware KV Cache Adaptive 2-Bit Quantization for Vision-Language Models
Jan 25, 2025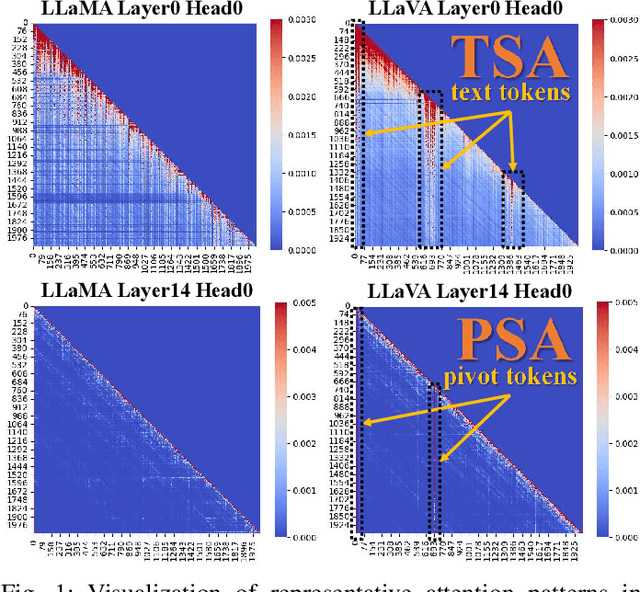
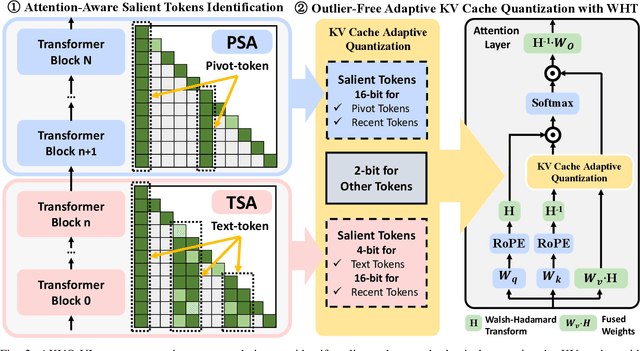
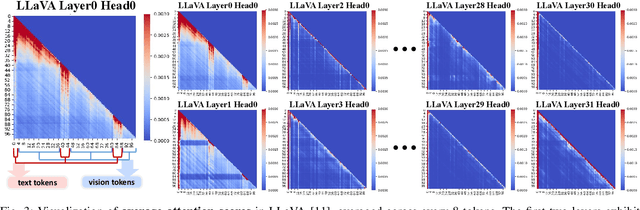
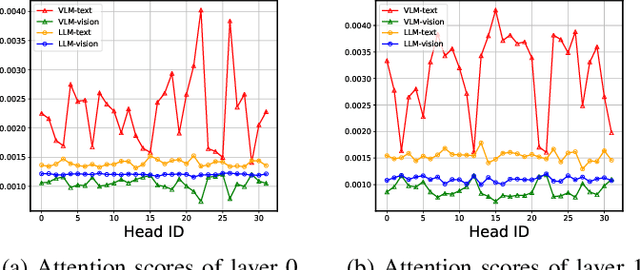
Vision-language models (VLMs) show remarkable performance in multimodal tasks. However, excessively long multimodal inputs lead to oversized Key-Value (KV) caches, resulting in significant memory consumption and I/O bottlenecks. Previous KV quantization methods for Large Language Models (LLMs) may alleviate these issues but overlook the attention saliency differences of multimodal tokens, resulting in suboptimal performance. In this paper, we investigate the attention-aware token saliency patterns in VLM and propose AKVQ-VL. AKVQ-VL leverages the proposed Text-Salient Attention (TSA) and Pivot-Token-Salient Attention (PSA) patterns to adaptively allocate bit budgets. Moreover, achieving extremely low-bit quantization requires effectively addressing outliers in KV tensors. AKVQ-VL utilizes the Walsh-Hadamard transform (WHT) to construct outlier-free KV caches, thereby reducing quantization difficulty. Evaluations of 2-bit quantization on 12 long-context and multimodal tasks demonstrate that AKVQ-VL maintains or even improves accuracy, outperforming LLM-oriented methods. AKVQ-VL can reduce peak memory usage by 2.13x, support up to 3.25x larger batch sizes and 2.46x throughput.