 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Modeling in Ultrasound Image Segmentation for Precise Fetal Biometric Measurements
Jan 17, 2024


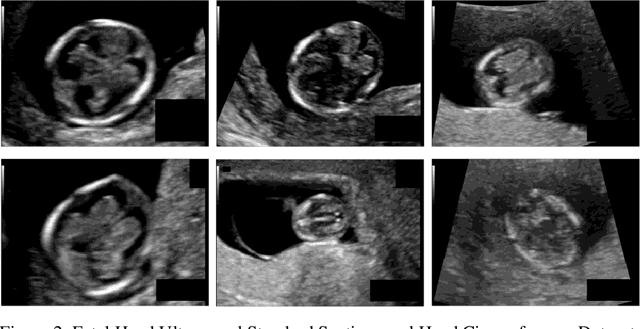
Medical image segmentation, particularly in the context of ultrasound data, is a crucial aspect of computer vision and medical imaging. This paper delves into the complexities of uncertainty in the segmentation process, focusing on fetal head and femur ultrasound images. The proposed methodology involves extracting target contours and exploring techniques for precise parameter measurement. Uncertainty modeling methods are employed to enhance the training and testing processes of the segmentation network. The study reveals that the average absolute error in fetal head circumference measurement is 8.0833mm, with a relative error of 4.7347%. Similarly, the average absolute error in fetal femur measurement is 2.6163mm, with a relative error of 6.3336%. Uncertainty modeling experiments employing Test-Time Augmentation (TTA) demonstrate effective interpretability of data uncertainty on both datasets. This suggests that incorporating data uncertainty based on the TTA method can support clinical practitioners in making informed decisions and obtaining more reliable measurement results in practical clinical applications. The paper contributes to the advancement of ultrasound image segmentation, addressing critical challenges and improving the reliability of biometric measurements.
Dual-Channel Reliable Breast Ultrasound Image Classification Based on Explainable Attribution and Uncertainty Quantification
Jan 08, 2024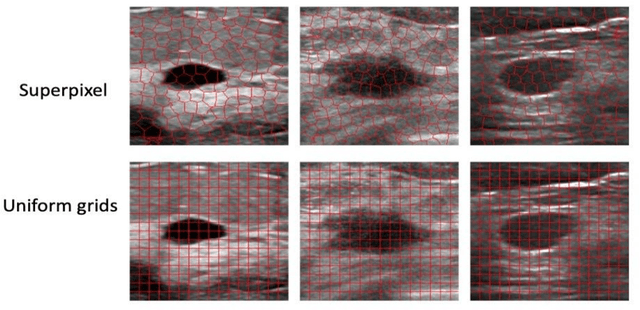

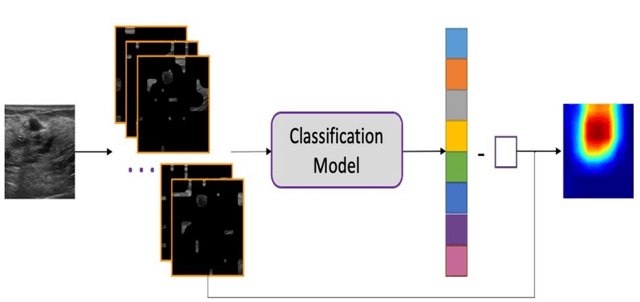

This paper focuses on the classification task of breast ultrasound images and researches on the reliability measurement of classification results. We proposed a dual-channel evaluation framework based on the proposed inference reliability and predictive reliability scores. For the inference reliability evaluation, human-aligned and doctor-agreed inference rationales based on the improved feature attribution algorithm SP-RISA are gracefully applied. Uncertainty quantification is used to evaluate the predictive reliability via the Test Time Enhancement. The effectiveness of this reliability evaluation framework has been verified on our breast ultrasound clinical dataset YBUS, and its robustness is verified on the public dataset BUSI. The expected calibration errors on both datasets are significantly lower than traditional evaluation methods, which proves the effectiveness of our proposed reliability measurement.
On Safe and Usable Chatbots for Promoting Voter Participation
Dec 28, 2022



Chatbots, or bots for short, are multi-modal collaborative assistants that can help people complete useful tasks. Usually, when chatbots are referenced in connection with elections, they often draw negative reactions due to the fear of mis-information and hacking. Instead, in this paper, we explore how chatbots may be used to promote voter participation in vulnerable segments of society like senior citizens and first-time voters. In particular, we build a system that amplifies official information while personalizing it to users' unique needs transparently. We discuss its design, build prototypes with frequently asked questions (FAQ) election information for two US states that are low on an ease-of-voting scale, and report on its initial evaluation in a focus group. Our approach can be a win-win for voters, election agencies trying to fulfill their mandate and democracy at large.
Knowledge AI: New Medical AI Solution for Medical image Diagnosis
Jan 08, 2021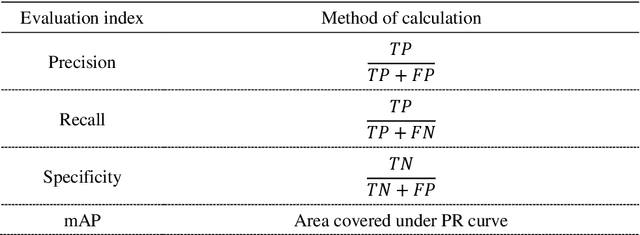

The implementation of medical AI has always been a problem. The effect of traditional perceptual AI algorithm in medical image processing needs to be improved. Here we propose a method of knowledge AI, which is a combination of perceptual AI and clinical knowledge and experience. Based on this method, the geometric information mining of medical images can represent the experience and information and evaluate the quality of medical images.
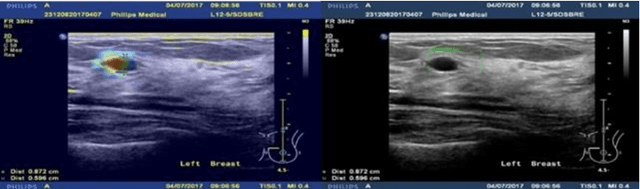
More Reliable AI Solution: Breast Ultrasound Diagnosis Using Multi-AI Combination
Jan 07, 2021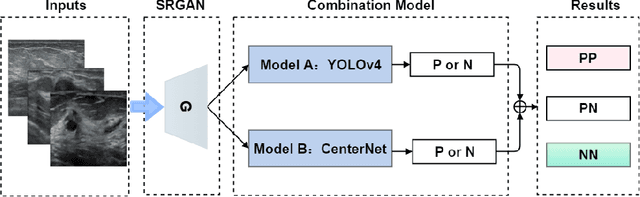
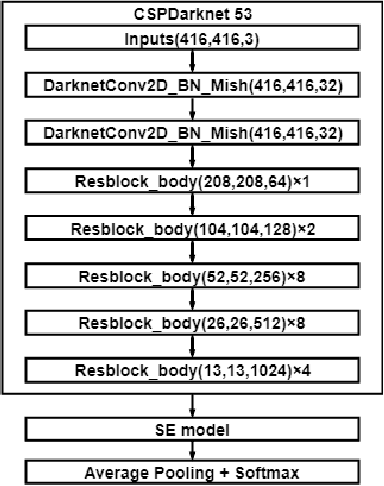

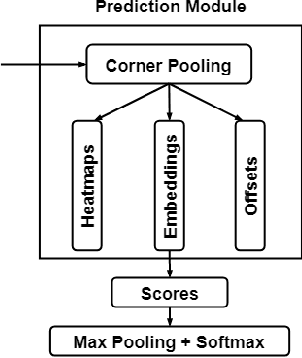
Objective: Breast cancer screening is of great significance in contemporary women's health prevention. The existing machines embedded in the AI system do not reach the accuracy that clinicians hope. How to make intelligent systems more reliable is a common problem. Methods: 1) Ultrasound image super-resolution: the SRGAN super-resolution network reduces the unclearness of ultrasound images caused by the device itself and improves the accuracy and generalization of the detection model. 2) In response to the needs of medical images, we have improved the YOLOv4 and the CenterNet models. 3) Multi-AI model: based on the respective advantages of different AI models, we employ two AI models to determine clinical resuls cross validation. And we accept the same results and refuses others. Results: 1) With the help of the super-resolution model, the YOLOv4 model and the CenterNet model both increased the mAP score by 9.6% and 13.8%. 2) Two methods for transforming the target model into a classification model are proposed. And the unified output is in a specified format to facilitate the call of the molti-AI model. 3) In the classification evaluation experiment, concatenated by the YOLOv4 model (sensitivity 57.73%, specificity 90.08%) and the CenterNet model (sensitivity 62.64%, specificity 92.54%), the multi-AI model will refuse to make judgments on 23.55% of the input data. Correspondingly, the performance has been greatly improved to 95.91% for the sensitivity and 96.02% for the specificity. Conclusion: Our work makes the AI model more reliable in medical image diagnosis. Significance: 1) The proposed method makes the target detection model more suitable for diagnosing breast ultrasound images. 2) It provides a new idea for artificial intelligence in medical diagnosis, which can more conveniently introduce target detection models from other fields to serve medical lesion screening.