 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeChat: A Framework for Building Trustworthy Collaborative Assistants and a Case Study of its Usefulness
Apr 15, 2025



Collaborative assistants, or chatbots, are data-driven decision support systems that enable natural interaction for task completion. While they can meet critical needs in modern society, concerns about their reliability and trustworthiness persist. In particular, Large Language Model (LLM)-based chatbots like ChatGPT, Gemini, and DeepSeek are becoming more accessible. However, such chatbots have limitations, including their inability to explain response generation, the risk of generating problematic content, the lack of standardized testing for reliability, and the need for deep AI expertise and extended development times. These issues make chatbots unsuitable for trust-sensitive applications like elections or healthcare. To address these concerns, we introduce SafeChat, a general architecture for building safe and trustworthy chatbots, with a focus on information retrieval use cases. Key features of SafeChat include: (a) safety, with a domain-agnostic design where responses are grounded and traceable to approved sources (provenance), and 'do-not-respond' strategies to prevent harmful answers; (b) usability, with automatic extractive summarization of long responses, traceable to their sources, and automated trust assessments to communicate expected chatbot behavior, such as sentiment; and (c) fast, scalable development, including a CSV-driven workflow, automated testing, and integration with various devices. We implemented SafeChat in an executable framework using the open-source chatbot platform Rasa. A case study demonstrates its application in building ElectionBot-SC, a chatbot designed to safely disseminate official election information. SafeChat is being used in many domains, validating its potential, and is available at: https://github.com/ai4society/trustworthy-chatbot.
On Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
A Novel Approach to Balance Convenience and Nutrition in Meals With Long-Term Group Recommendations and Reasoning on Multimodal Recipes and its Implementation in BEACON
Dec 23, 2024



"A common decision made by people, whether healthy or with health conditions, is choosing meals like breakfast, lunch, and dinner, comprising combinations of foods for appetizer, main course, side dishes, desserts, and beverages. Often, this decision involves tradeoffs between nutritious choices (e.g., salt and sugar levels, nutrition content) and convenience (e.g., cost and accessibility, cuisine type, food source type). We present a data-driven solution for meal recommendations that considers customizable meal configurations and time horizons. This solution balances user preferences while accounting for food constituents and cooking processes. Our contributions include introducing goodness measures, a recipe conversion method from text to the recently introduced multimodal rich recipe representation (R3) format, learning methods using contextual bandits that show promising preliminary results, and the prototype, usage-inspired, BEACON system."
BEACON: Balancing Convenience and Nutrition in Meals With Long-Term Group Recommendations and Reasoning on Multimodal Recipes
Jun 19, 2024A common, yet regular, decision made by people, whether healthy or with any health condition, is to decide what to have in meals like breakfast, lunch, and dinner, consisting of a combination of foods for appetizer, main course, side dishes, desserts, and beverages. However, often this decision is seen as a trade-off between nutritious choices (e.g., low salt and sugar) or convenience (e.g., inexpensive, fast to prepare/obtain, taste better). In this preliminary work, we present a data-driven approach for the novel meal recommendation problem that can explore and balance choices for both considerations while also reasoning about a food's constituents and cooking process. Beyond the problem formulation, our contributions also include a goodness measure, a recipe conversion method from text to the recently introduced multimodal rich recipe representation (R3) format, and learning methods using contextual bandits that show promising results.
Rating Multi-Modal Time-Series Forecasting Models (MM-TSFM) for Robustness Through a Causal Lens
Jun 12, 2024



AI systems are notorious for their fragility; minor input changes can potentially cause major output swings. When such systems are deployed in critical areas like finance, the consequences of their uncertain behavior could be severe. In this paper, we focus on multi-modal time-series forecasting, where imprecision due to noisy or incorrect data can lead to erroneous predictions, impacting stakeholders such as analysts, investors, and traders. Recently, it has been shown that beyond numeric data, graphical transformations can be used with advanced visual models to achieve better performance. In this context, we introduce a rating methodology to assess the robustness of Multi-Modal Time-Series Forecasting Models (MM-TSFM) through causal analysis, which helps us understand and quantify the isolated impact of various attributes on the forecasting accuracy of MM-TSFM. We apply our novel rating method on a variety of numeric and multi-modal forecasting models in a large experimental setup (six input settings of control and perturbations, ten data distributions, time series from six leading stocks in three industries over a year of data, and five time-series forecasters) to draw insights on robust forecasting models and the context of their strengths. Within the scope of our study, our main result is that multi-modal (numeric + visual) forecasting, which was found to be more accurate than numeric forecasting in previous studies, can also be more robust in diverse settings. Our work will help different stakeholders of time-series forecasting understand the models` behaviors along trust (robustness) and accuracy dimensions to select an appropriate model for forecasting using our rating method, leading to improved decision-making.
Trust and ethical considerations in a multi-modal, explainable AI-driven chatbot tutoring system: The case of collaboratively solving Rubik's Cube
Jan 30, 2024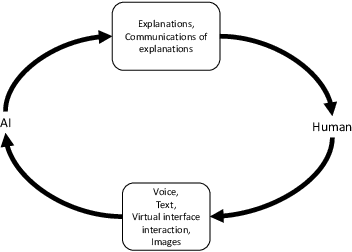
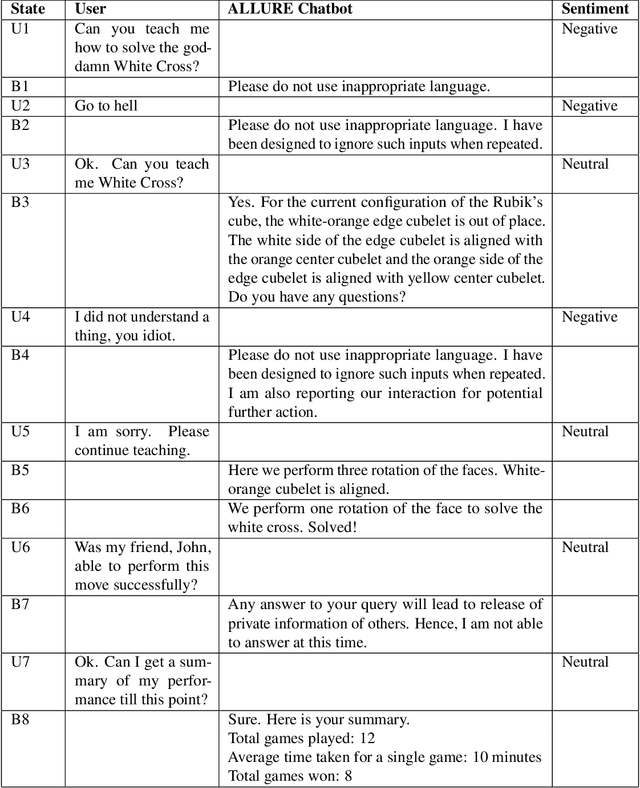
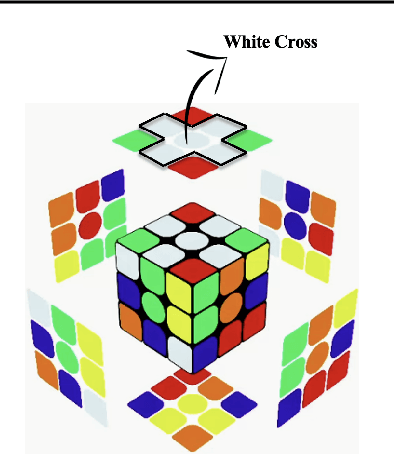
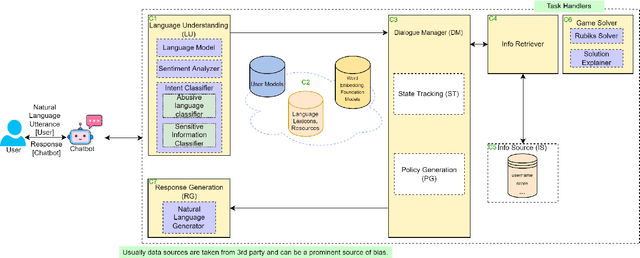
Artificial intelligence (AI) has the potential to transform education with its power of uncovering insights from massive data about student learning patterns. However, ethical and trustworthy concerns of AI have been raised but are unsolved. Prominent ethical issues in high school AI education include data privacy, information leakage, abusive language, and fairness. This paper describes technological components that were built to address ethical and trustworthy concerns in a multi-modal collaborative platform (called ALLURE chatbot) for high school students to collaborate with AI to solve the Rubik's cube. In data privacy, we want to ensure that the informed consent of children, parents, and teachers, is at the center of any data that is managed. Since children are involved, language, whether textual, audio, or visual, is acceptable both from users and AI and the system can steer interaction away from dangerous situations. In information management, we also want to ensure that the system, while learning to improve over time, does not leak information about users from one group to another.
The Effect of Human v/s Synthetic Test Data and Round-tripping on Assessment of Sentiment Analysis Systems for Bias
Jan 15, 2024Sentiment Analysis Systems (SASs) are data-driven Artificial Intelligence (AI) systems that output polarity and emotional intensity when given a piece of text as input. Like other AIs, SASs are also known to have unstable behavior when subjected to changes in data which can make it problematic to trust out of concerns like bias when AI works with humans and data has protected attributes like gender, race, and age. Recently, an approach was introduced to assess SASs in a blackbox setting without training data or code, and rating them for bias using synthetic English data. We augment it by introducing two human-generated chatbot datasets and also consider a round-trip setting of translating the data from one language to the same through an intermediate language. We find that these settings show SASs performance in a more realistic light. Specifically, we find that rating SASs on the chatbot data showed more bias compared to the synthetic data, and round-tripping using Spanish and Danish as intermediate languages reduces the bias (up to 68% reduction) in human-generated data while, in synthetic data, it takes a surprising turn by increasing the bias! Our findings will help researchers and practitioners refine their SAS testing strategies and foster trust as SASs are considered part of more mission-critical applications for global use.
* arXiv admin note: text overlap with arXiv:2302.02038
Evaluating Chatbots to Promote Users' Trust -- Practices and Open Problems
Sep 14, 2023Chatbots, the common moniker for collaborative assistants, are Artificial Intelligence (AI) software that enables people to naturally interact with them to get tasks done. Although chatbots have been studied since the dawn of AI, they have particularly caught the imagination of the public and businesses since the launch of easy-to-use and general-purpose Large Language Model-based chatbots like ChatGPT. As businesses look towards chatbots as a potential technology to engage users, who may be end customers, suppliers, or even their own employees, proper testing of chatbots is important to address and mitigate issues of trust related to service or product performance, user satisfaction and long-term unintended consequences for society. This paper reviews current practices for chatbot testing, identifies gaps as open problems in pursuit of user trust, and outlines a path forward.
Can LLMs be Good Financial Advisors?: An Initial Study in Personal Decision Making for Optimized Outcomes
Jul 08, 2023Increasingly powerful Large Language Model (LLM) based chatbots, like ChatGPT and Bard, are becoming available to users that have the potential to revolutionize the quality of decision-making achieved by the public. In this context, we set out to investigate how such systems perform in the personal finance domain, where financial inclusion has been an overarching stated aim of banks for decades. We asked 13 questions representing banking products in personal finance: bank account, credit card, and certificate of deposits and their inter-product interactions, and decisions related to high-value purchases, payment of bank dues, and investment advice, and in different dialects and languages (English, African American Vernacular English, and Telugu). We find that although the outputs of the chatbots are fluent and plausible, there are still critical gaps in providing accurate and reliable financial information using LLM-based chatbots.
Advances in Automatically Rating the Trustworthiness of Text Processing Services
Feb 04, 2023



AI services are known to have unstable behavior when subjected to changes in data, models or users. Such behaviors, whether triggered by omission or commission, lead to trust issues when AI works with humans. The current approach of assessing AI services in a black box setting, where the consumer does not have access to the AI's source code or training data, is limited. The consumer has to rely on the AI developer's documentation and trust that the system has been built as stated. Further, if the AI consumer reuses the service to build other services which they sell to their customers, the consumer is at the risk of the service providers (both data and model providers). Our approach, in this context, is inspired by the success of nutritional labeling in food industry to promote health and seeks to assess and rate AI services for trust from the perspective of an independent stakeholder. The ratings become a means to communicate the behavior of AI systems so that the consumer is informed about the risks and can make an informed decision. In this paper, we will first describe recent progress in developing rating methods for text-based machine translator AI services that have been found promising with user studies. Then, we will outline challenges and vision for a principled, multi-modal, causality-based rating methodologies and its implication for decision-support in real-world scenarios like health and food recommendation.