 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeChat: A Framework for Building Trustworthy Collaborative Assistants and a Case Study of its Usefulness
Apr 15, 2025



Collaborative assistants, or chatbots, are data-driven decision support systems that enable natural interaction for task completion. While they can meet critical needs in modern society, concerns about their reliability and trustworthiness persist. In particular, Large Language Model (LLM)-based chatbots like ChatGPT, Gemini, and DeepSeek are becoming more accessible. However, such chatbots have limitations, including their inability to explain response generation, the risk of generating problematic content, the lack of standardized testing for reliability, and the need for deep AI expertise and extended development times. These issues make chatbots unsuitable for trust-sensitive applications like elections or healthcare. To address these concerns, we introduce SafeChat, a general architecture for building safe and trustworthy chatbots, with a focus on information retrieval use cases. Key features of SafeChat include: (a) safety, with a domain-agnostic design where responses are grounded and traceable to approved sources (provenance), and 'do-not-respond' strategies to prevent harmful answers; (b) usability, with automatic extractive summarization of long responses, traceable to their sources, and automated trust assessments to communicate expected chatbot behavior, such as sentiment; and (c) fast, scalable development, including a CSV-driven workflow, automated testing, and integration with various devices. We implemented SafeChat in an executable framework using the open-source chatbot platform Rasa. A case study demonstrates its application in building ElectionBot-SC, a chatbot designed to safely disseminate official election information. SafeChat is being used in many domains, validating its potential, and is available at: https://github.com/ai4society/trustworthy-chatbot.
Benchmarking community drug response prediction models: datasets, models, tools, and metrics for cross-dataset generalization analysis
Mar 18, 2025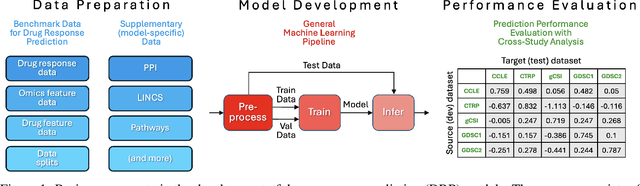
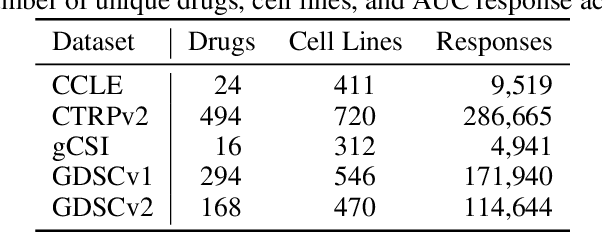
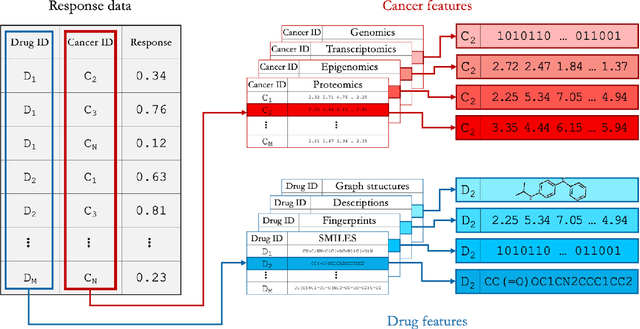

Deep learning (DL) and machine learning (ML) models have shown promise in drug response prediction (DRP), yet their ability to generalize across datasets remains an open question, raising concerns about their real-world applicability. Due to the lack of standardized benchmarking approaches, model evaluations and comparisons often rely on inconsistent datasets and evaluation criteria, making it difficult to assess true predictive capabilities. In this work, we introduce a benchmarking framework for evaluating cross-dataset prediction generalization in DRP models. Our framework incorporates five publicly available drug screening datasets, six standardized DRP models, and a scalable workflow for systematic evaluation. To assess model generalization, we introduce a set of evaluation metrics that quantify both absolute performance (e.g., predictive accuracy across datasets) and relative performance (e.g., performance drop compared to within-dataset results), enabling a more comprehensive assessment of model transferability. Our results reveal substantial performance drops when models are tested on unseen datasets, underscoring the importance of rigorous generalization assessments. While several models demonstrate relatively strong cross-dataset generalization, no single model consistently outperforms across all datasets. Furthermore, we identify CTRPv2 as the most effective source dataset for training, yielding higher generalization scores across target datasets. By sharing this standardized evaluation framework with the community, our study aims to establish a rigorous foundation for model comparison, and accelerate the development of robust DRP models for real-world applications.