 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking community drug response prediction models: datasets, models, tools, and metrics for cross-dataset generalization analysis
Mar 18, 2025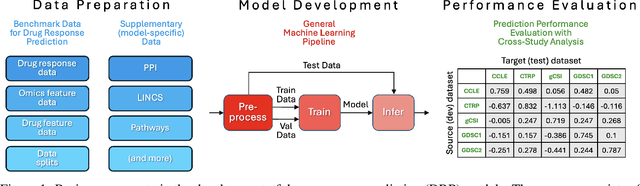
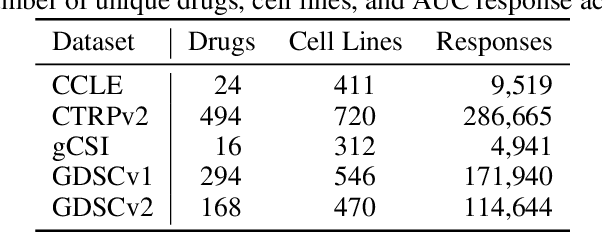
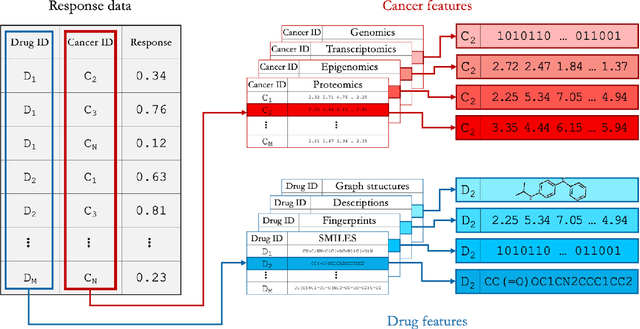

Deep learning (DL) and machine learning (ML) models have shown promise in drug response prediction (DRP), yet their ability to generalize across datasets remains an open question, raising concerns about their real-world applicability. Due to the lack of standardized benchmarking approaches, model evaluations and comparisons often rely on inconsistent datasets and evaluation criteria, making it difficult to assess true predictive capabilities. In this work, we introduce a benchmarking framework for evaluating cross-dataset prediction generalization in DRP models. Our framework incorporates five publicly available drug screening datasets, six standardized DRP models, and a scalable workflow for systematic evaluation. To assess model generalization, we introduce a set of evaluation metrics that quantify both absolute performance (e.g., predictive accuracy across datasets) and relative performance (e.g., performance drop compared to within-dataset results), enabling a more comprehensive assessment of model transferability. Our results reveal substantial performance drops when models are tested on unseen datasets, underscoring the importance of rigorous generalization assessments. While several models demonstrate relatively strong cross-dataset generalization, no single model consistently outperforms across all datasets. Furthermore, we identify CTRPv2 as the most effective source dataset for training, yielding higher generalization scores across target datasets. By sharing this standardized evaluation framework with the community, our study aims to establish a rigorous foundation for model comparison, and accelerate the development of robust DRP models for real-world applications.