 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking community drug response prediction models: datasets, models, tools, and metrics for cross-dataset generalization analysis
Mar 18, 2025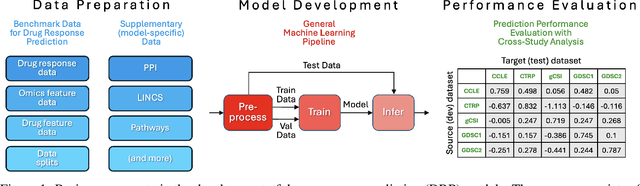
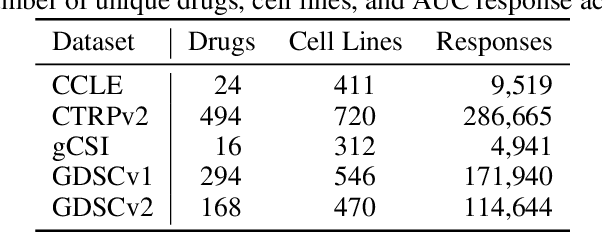
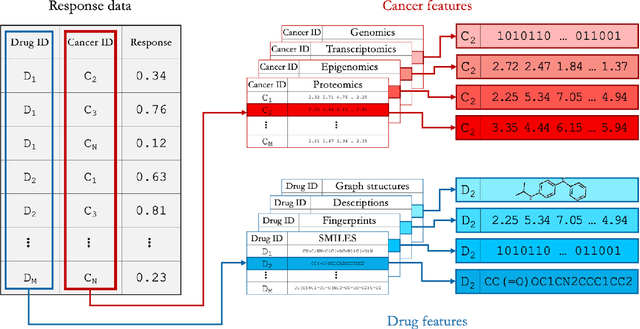

Deep learning (DL) and machine learning (ML) models have shown promise in drug response prediction (DRP), yet their ability to generalize across datasets remains an open question, raising concerns about their real-world applicability. Due to the lack of standardized benchmarking approaches, model evaluations and comparisons often rely on inconsistent datasets and evaluation criteria, making it difficult to assess true predictive capabilities. In this work, we introduce a benchmarking framework for evaluating cross-dataset prediction generalization in DRP models. Our framework incorporates five publicly available drug screening datasets, six standardized DRP models, and a scalable workflow for systematic evaluation. To assess model generalization, we introduce a set of evaluation metrics that quantify both absolute performance (e.g., predictive accuracy across datasets) and relative performance (e.g., performance drop compared to within-dataset results), enabling a more comprehensive assessment of model transferability. Our results reveal substantial performance drops when models are tested on unseen datasets, underscoring the importance of rigorous generalization assessments. While several models demonstrate relatively strong cross-dataset generalization, no single model consistently outperforms across all datasets. Furthermore, we identify CTRPv2 as the most effective source dataset for training, yielding higher generalization scores across target datasets. By sharing this standardized evaluation framework with the community, our study aims to establish a rigorous foundation for model comparison, and accelerate the development of robust DRP models for real-world applications.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Deep learning methods for drug response prediction in cancer: predominant and emerging trends
Nov 18, 2022Cancer claims millions of lives yearly worldwide. While many therapies have been made available in recent years, by in large cancer remains unsolved. Exploiting computational predictive models to study and treat cancer holds great promise in improving drug development and personalized design of treatment plans, ultimately suppressing tumors, alleviating suffering, and prolonging lives of patients. A wave of recent papers demonstrates promising results in predicting cancer response to drug treatments while utilizing deep learning methods. These papers investigate diverse data representations, neural network architectures, learning methodologies, and evaluations schemes. However, deciphering promising predominant and emerging trends is difficult due to the variety of explored methods and lack of standardized framework for comparing drug response prediction models. To obtain a comprehensive landscape of deep learning methods, we conducted an extensive search and analysis of deep learning models that predict the response to single drug treatments. A total of 60 deep learning-based models have been curated and summary plots were generated. Based on the analysis, observable patterns and prevalence of methods have been revealed. This review allows to better understand the current state of the field and identify major challenges and promising solution paths.