 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
Oct 30, 2025
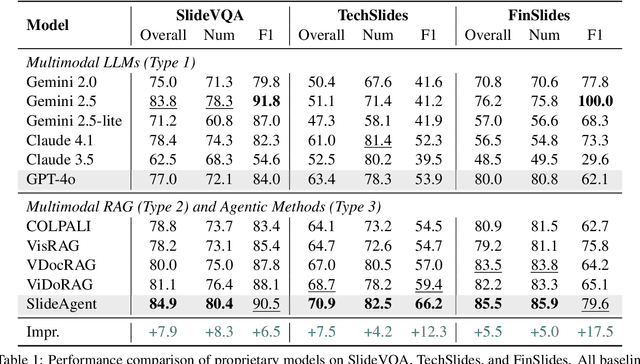


Multi-page visual documents such as manuals, brochures, presentations, and posters convey key information through layout, colors, icons, and cross-slide references. While large language models (LLMs) offer opportunities in document understanding, current systems struggle with complex, multi-page visual documents, particularly in fine-grained reasoning over elements and pages. We introduce SlideAgent, a versatile agentic framework for understanding multi-modal, multi-page, and multi-layout documents, especially slide decks. SlideAgent employs specialized agents and decomposes reasoning into three specialized levels-global, page, and element-to construct a structured, query-agnostic representation that captures both overarching themes and detailed visual or textual cues. During inference, SlideAgent selectively activates specialized agents for multi-level reasoning and integrates their outputs into coherent, context-aware answers. Extensive experiments show that SlideAgent achieves significant improvement over both proprietary (+7.9 overall) and open-source models (+9.8 overall).
ChartAgent: A Multimodal Agent for Visually Grounded Reasoning in Complex Chart Question Answering
Oct 06, 2025Recent multimodal LLMs have shown promise in chart-based visual question answering, but their performance declines sharply on unannotated charts, those requiring precise visual interpretation rather than relying on textual shortcuts. To address this, we introduce ChartAgent, a novel agentic framework that explicitly performs visual reasoning directly within the chart's spatial domain. Unlike textual chain-of-thought reasoning, ChartAgent iteratively decomposes queries into visual subtasks and actively manipulates and interacts with chart images through specialized actions such as drawing annotations, cropping regions (e.g., segmenting pie slices, isolating bars), and localizing axes, using a library of chart-specific vision tools to fulfill each subtask. This iterative reasoning process closely mirrors human cognitive strategies for chart comprehension. ChartAgent achieves state-of-the-art accuracy on the ChartBench and ChartX benchmarks, surpassing prior methods by up to 16.07% absolute gain overall and 17.31% on unannotated, numerically intensive queries. Furthermore, our analyses show that ChartAgent is (a) effective across diverse chart types, (b) achieve the highest scores across varying visual and reasoning complexity levels, and (c) serves as a plug-and-play framework that boosts performance across diverse underlying LLMs. Our work is among the first to demonstrate visually grounded reasoning for chart understanding using tool-augmented multimodal agents.
TADACap: Time-series Adaptive Domain-Aware Captioning
Apr 15, 2025While image captioning has gained significant attention, the potential of captioning time-series images, prevalent in areas like finance and healthcare, remains largely untapped. Existing time-series captioning methods typically offer generic, domain-agnostic descriptions of time-series shapes and struggle to adapt to new domains without substantial retraining. To address these limitations, we introduce TADACap, a retrieval-based framework to generate domain-aware captions for time-series images, capable of adapting to new domains without retraining. Building on TADACap, we propose a novel retrieval strategy that retrieves diverse image-caption pairs from a target domain database, namely TADACap-diverse. We benchmarked TADACap-diverse against state-of-the-art methods and ablation variants. TADACap-diverse demonstrates comparable semantic accuracy while requiring significantly less annotation effort.
On Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024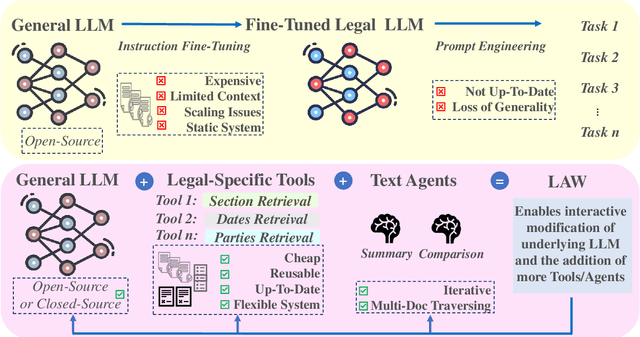
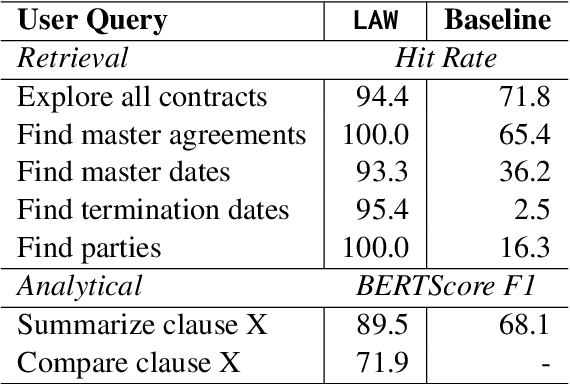
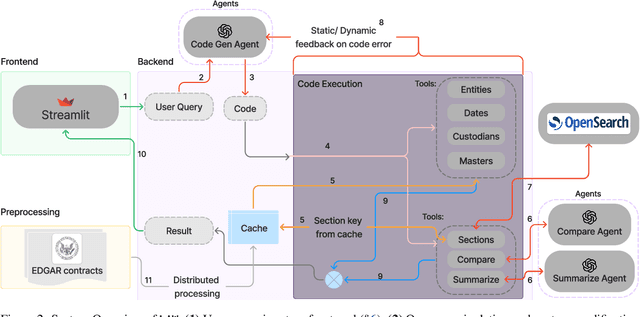

Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
AdaptAgent: Adapting Multimodal Web Agents with Few-Shot Learning from Human Demonstrations
Nov 20, 2024



State-of-the-art multimodal web agents, powered by Multimodal Large Language Models (MLLMs), can autonomously execute many web tasks by processing user instructions and interacting with graphical user interfaces (GUIs). Current strategies for building web agents rely on (i) the generalizability of underlying MLLMs and their steerability via prompting, and (ii) large-scale fine-tuning of MLLMs on web-related tasks. However, web agents still struggle to automate tasks on unseen websites and domains, limiting their applicability to enterprise-specific and proprietary platforms. Beyond generalization from large-scale pre-training and fine-tuning, we propose building agents for few-shot adaptability using human demonstrations. We introduce the AdaptAgent framework that enables both proprietary and open-weights multimodal web agents to adapt to new websites and domains using few human demonstrations (up to 2). Our experiments on two popular benchmarks -- Mind2Web & VisualWebArena -- show that using in-context demonstrations (for proprietary models) or meta-adaptation demonstrations (for meta-learned open-weights models) boosts task success rate by 3.36% to 7.21% over non-adapted state-of-the-art models, corresponding to a relative increase of 21.03% to 65.75%. Furthermore, our additional analyses (a) show the effectiveness of multimodal demonstrations over text-only ones, (b) shed light on the influence of different data selection strategies during meta-learning on the generalization of the agent, and (c) demonstrate the effect of number of few-shot examples on the web agent's success rate. Overall, our results unlock a complementary axis for developing widely applicable multimodal web agents beyond large-scale pre-training and fine-tuning, emphasizing few-shot adaptability.
LETS-C: Leveraging Language Embedding for Time Series Classification
Jul 09, 2024



Recent advancements in language modeling have shown promising results when applied to time series data. In particular, fine-tuning pre-trained large language models (LLMs) for time series classification tasks has achieved state-of-the-art (SOTA) performance on standard benchmarks. However, these LLM-based models have a significant drawback due to the large model size, with the number of trainable parameters in the millions. In this paper, we propose an alternative approach to leveraging the success of language modeling in the time series domain. Instead of fine-tuning LLMs, we utilize a language embedding model to embed time series and then pair the embeddings with a simple classification head composed of convolutional neural networks (CNN) and multilayer perceptron (MLP). We conducted extensive experiments on well-established time series classification benchmark datasets. We demonstrated LETS-C not only outperforms the current SOTA in classification accuracy but also offers a lightweight solution, using only 14.5% of the trainable parameters on average compared to the SOTA model. Our findings suggest that leveraging language encoders to embed time series data, combined with a simple yet effective classification head, offers a promising direction for achieving high-performance time series classification while maintaining a lightweight model architecture.
Rating Multi-Modal Time-Series Forecasting Models (MM-TSFM) for Robustness Through a Causal Lens
Jun 12, 2024



AI systems are notorious for their fragility; minor input changes can potentially cause major output swings. When such systems are deployed in critical areas like finance, the consequences of their uncertain behavior could be severe. In this paper, we focus on multi-modal time-series forecasting, where imprecision due to noisy or incorrect data can lead to erroneous predictions, impacting stakeholders such as analysts, investors, and traders. Recently, it has been shown that beyond numeric data, graphical transformations can be used with advanced visual models to achieve better performance. In this context, we introduce a rating methodology to assess the robustness of Multi-Modal Time-Series Forecasting Models (MM-TSFM) through causal analysis, which helps us understand and quantify the isolated impact of various attributes on the forecasting accuracy of MM-TSFM. We apply our novel rating method on a variety of numeric and multi-modal forecasting models in a large experimental setup (six input settings of control and perturbations, ten data distributions, time series from six leading stocks in three industries over a year of data, and five time-series forecasters) to draw insights on robust forecasting models and the context of their strengths. Within the scope of our study, our main result is that multi-modal (numeric + visual) forecasting, which was found to be more accurate than numeric forecasting in previous studies, can also be more robust in diverse settings. Our work will help different stakeholders of time-series forecasting understand the models` behaviors along trust (robustness) and accuracy dimensions to select an appropriate model for forecasting using our rating method, leading to improved decision-making.
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Apr 25, 2024Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
From Pixels to Predictions: Spectrogram and Vision Transformer for Better Time Series Forecasting
Mar 17, 2024Time series forecasting plays a crucial role in decision-making across various domains, but it presents significant challenges. Recent studies have explored image-driven approaches using computer vision models to address these challenges, often employing lineplots as the visual representation of time series data. In this paper, we propose a novel approach that uses time-frequency spectrograms as the visual representation of time series data. We introduce the use of a vision transformer for multimodal learning, showcasing the advantages of our approach across diverse datasets from different domains. To evaluate its effectiveness, we compare our method against statistical baselines (EMA and ARIMA), a state-of-the-art deep learning-based approach (DeepAR), other visual representations of time series data (lineplot images), and an ablation study on using only the time series as input. Our experiments demonstrate the benefits of utilizing spectrograms as a visual representation for time series data, along with the advantages of employing a vision transformer for simultaneous learning in both the time and frequency domains.