 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024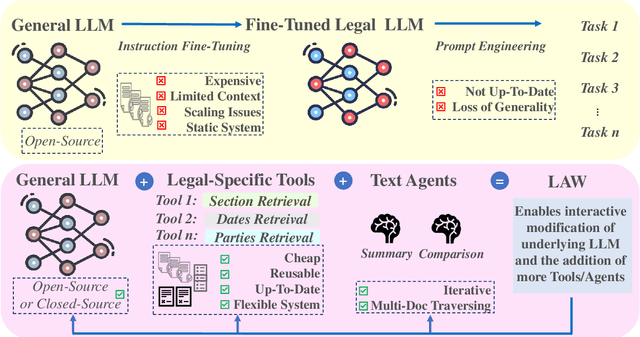
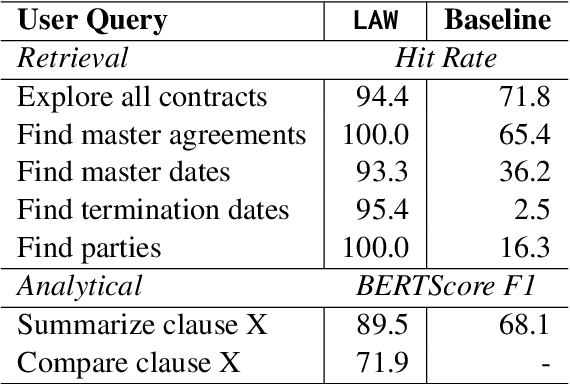
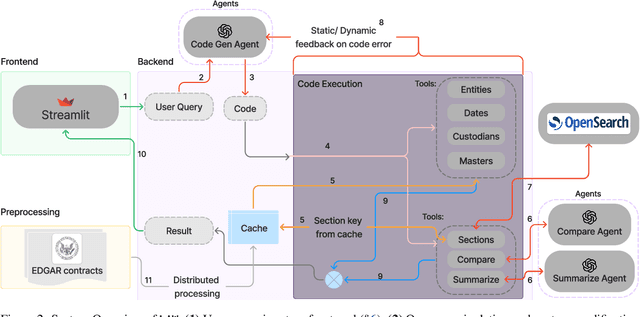

Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
Mitigating Partial Observability in Sequential Decision Processes via the Lambda Discrepancy
Jul 10, 2024



Reinforcement learning algorithms typically rely on the assumption that the environment dynamics and value function can be expressed in terms of a Markovian state representation. However, when state information is only partially observable, how can an agent learn such a state representation, and how can it detect when it has found one? We introduce a metric that can accomplish both objectives, without requiring access to--or knowledge of--an underlying, unobservable state space. Our metric, the $\lambda$-discrepancy, is the difference between two distinct temporal difference (TD) value estimates, each computed using TD($\lambda$) with a different value of $\lambda$. Since TD($\lambda$=0) makes an implicit Markov assumption and TD($\lambda$=1) does not, a discrepancy between these estimates is a potential indicator of a non-Markovian state representation. Indeed, we prove that the $\lambda$-discrepancy is exactly zero for all Markov decision processes and almost always non-zero for a broad class of partially observable environments. We also demonstrate empirically that, once detected, minimizing the $\lambda$-discrepancy can help with learning a memory function to mitigate the corresponding partial observability. We then train a reinforcement learning agent that simultaneously constructs two recurrent value networks with different $\lambda$ parameters and minimizes the difference between them as an auxiliary loss. The approach scales to challenging partially observable domains, where the resulting agent frequently performs significantly better (and never performs worse) than a baseline recurrent agent with only a single value network.
Neural MMO 2.0: A Massively Multi-task Addition to Massively Multi-agent Learning
Nov 07, 2023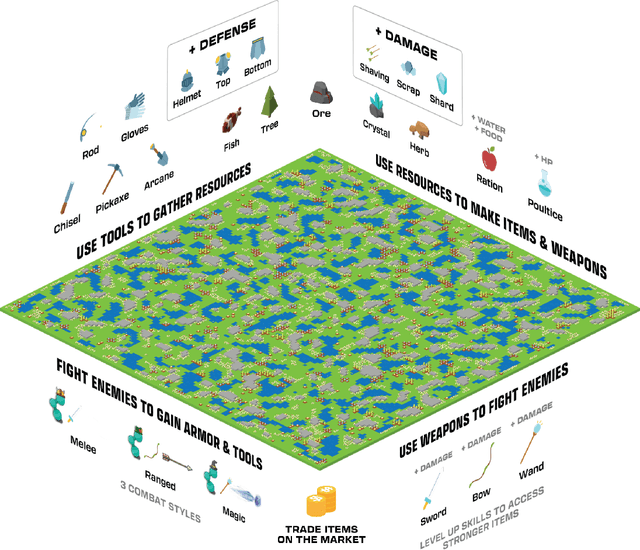

Neural MMO 2.0 is a massively multi-agent environment for reinforcement learning research. The key feature of this new version is a flexible task system that allows users to define a broad range of objectives and reward signals. We challenge researchers to train agents capable of generalizing to tasks, maps, and opponents never seen during training. Neural MMO features procedurally generated maps with 128 agents in the standard setting and support for up to. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance and compatibility with CleanRL. We release the platform as free and open-source software with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.