 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
Building reliable sim driving agents by scaling self-play
Feb 20, 2025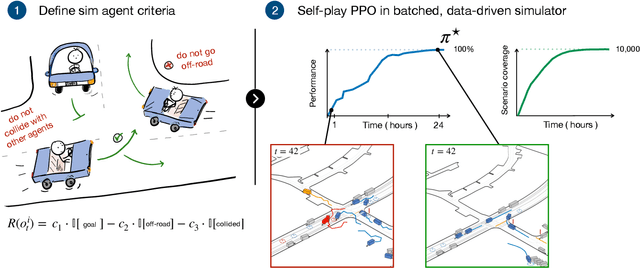

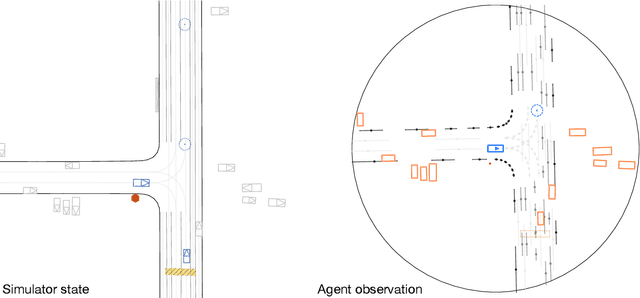

Simulation agents are essential for designing and testing systems that interact with humans, such as autonomous vehicles (AVs). These agents serve various purposes, from benchmarking AV performance to stress-testing the system's limits, but all use cases share a key requirement: reliability. A simulation agent should behave as intended by the designer, minimizing unintended actions like collisions that can compromise the signal-to-noise ratio of analyses. As a foundation for reliable sim agents, we propose scaling self-play to thousands of scenarios on the Waymo Open Motion Dataset under semi-realistic limits on human perception and control. Training from scratch on a single GPU, our agents nearly solve the full training set within a day. They generalize effectively to unseen test scenes, achieving a 99.8% goal completion rate with less than 0.8% combined collision and off-road incidents across 10,000 held-out scenarios. Beyond in-distribution generalization, our agents show partial robustness to out-of-distribution scenes and can be fine-tuned in minutes to reach near-perfect performance in those cases. Demonstrations of agent behaviors can be found at this link. We open-source both the pre-trained agents and the complete code base. Demonstrations of agent behaviors can be found at \url{https://sites.google.com/view/reliable-sim-agents}.
Massively Multiagent Minigames for Training Generalist Agents
Jun 07, 2024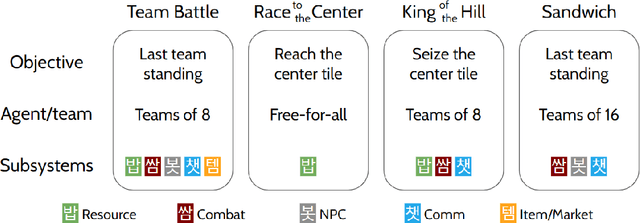
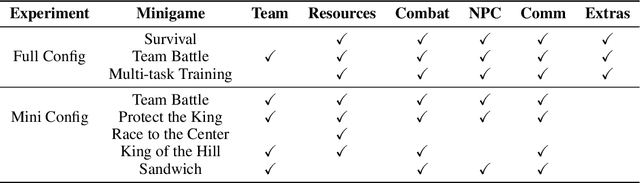
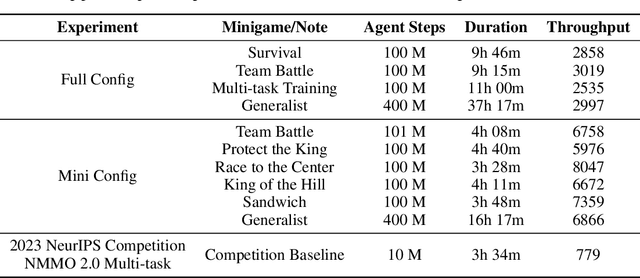
We present Meta MMO, a collection of many-agent minigames for use as a reinforcement learning benchmark. Meta MMO is built on top of Neural MMO, a massively multiagent environment that has been the subject of two previous NeurIPS competitions. Our work expands Neural MMO with several computationally efficient minigames. We explore generalization across Meta MMO by learning to play several minigames with a single set of weights. We release the environment, baselines, and training code under the MIT license. We hope that Meta MMO will spur additional progress on Neural MMO and, more generally, will serve as a useful benchmark for many-agent generalization.
Neural MMO 2.0: A Massively Multi-task Addition to Massively Multi-agent Learning
Nov 07, 2023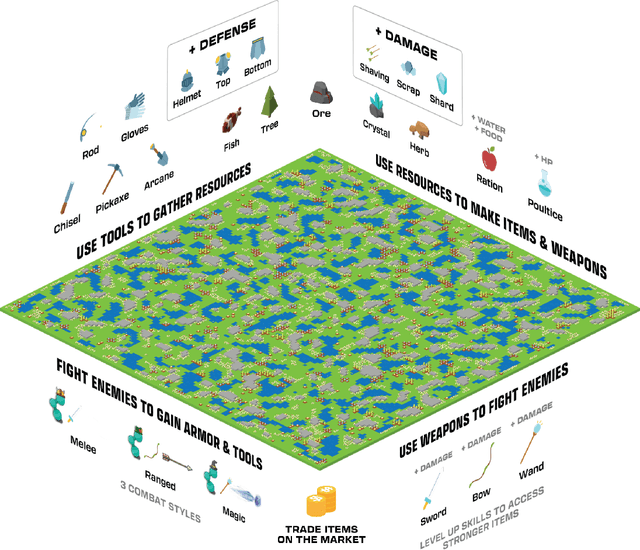

Neural MMO 2.0 is a massively multi-agent environment for reinforcement learning research. The key feature of this new version is a flexible task system that allows users to define a broad range of objectives and reward signals. We challenge researchers to train agents capable of generalizing to tasks, maps, and opponents never seen during training. Neural MMO features procedurally generated maps with 128 agents in the standard setting and support for up to. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance and compatibility with CleanRL. We release the platform as free and open-source software with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.