 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024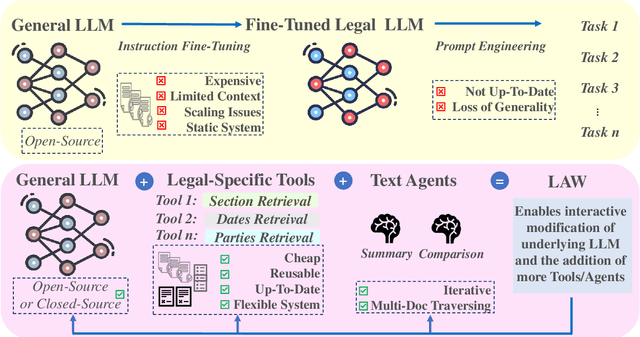
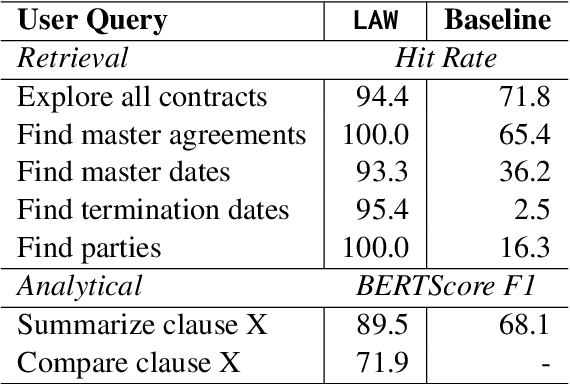
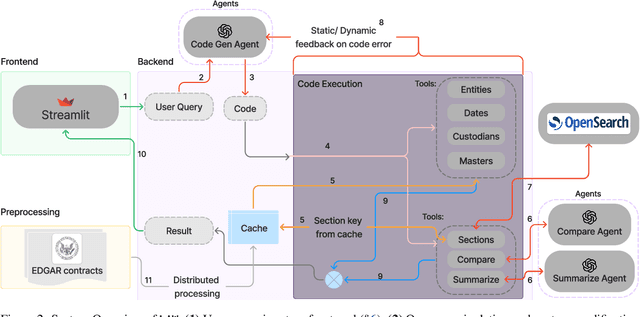

Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
Large Language Models as Financial Data Annotators: A Study on Effectiveness and Efficiency
Mar 26, 2024Collecting labeled datasets in finance is challenging due to scarcity of domain experts and higher cost of employing them. While Large Language Models (LLMs) have demonstrated remarkable performance in data annotation tasks on general domain datasets, their effectiveness on domain specific datasets remains underexplored. To address this gap, we investigate the potential of LLMs as efficient data annotators for extracting relations in financial documents. We compare the annotations produced by three LLMs (GPT-4, PaLM 2, and MPT Instruct) against expert annotators and crowdworkers. We demonstrate that the current state-of-the-art LLMs can be sufficient alternatives to non-expert crowdworkers. We analyze models using various prompts and parameter settings and find that customizing the prompts for each relation group by providing specific examples belonging to those groups is paramount. Furthermore, we introduce a reliability index (LLM-RelIndex) used to identify outputs that may require expert attention. Finally, we perform an extensive time, cost and error analysis and provide recommendations for the collection and usage of automated annotations in domain-specific settings.
From Pixels to Predictions: Spectrogram and Vision Transformer for Better Time Series Forecasting
Mar 17, 2024Time series forecasting plays a crucial role in decision-making across various domains, but it presents significant challenges. Recent studies have explored image-driven approaches using computer vision models to address these challenges, often employing lineplots as the visual representation of time series data. In this paper, we propose a novel approach that uses time-frequency spectrograms as the visual representation of time series data. We introduce the use of a vision transformer for multimodal learning, showcasing the advantages of our approach across diverse datasets from different domains. To evaluate its effectiveness, we compare our method against statistical baselines (EMA and ARIMA), a state-of-the-art deep learning-based approach (DeepAR), other visual representations of time series data (lineplot images), and an ablation study on using only the time series as input. Our experiments demonstrate the benefits of utilizing spectrograms as a visual representation for time series data, along with the advantages of employing a vision transformer for simultaneous learning in both the time and frequency domains.
Financial Time Series Forecasting using CNN and Transformer
Apr 11, 2023

Time series forecasting is important across various domains for decision-making. In particular, financial time series such as stock prices can be hard to predict as it is difficult to model short-term and long-term temporal dependencies between data points. Convolutional Neural Networks (CNN) are good at capturing local patterns for modeling short-term dependencies. However, CNNs cannot learn long-term dependencies due to the limited receptive field. Transformers on the other hand are capable of learning global context and long-term dependencies. In this paper, we propose to harness the power of CNNs and Transformers to model both short-term and long-term dependencies within a time series, and forecast if the price would go up, down or remain the same (flat) in the future. In our experiments, we demonstrated the success of the proposed method in comparison to commonly adopted statistical and deep learning methods on forecasting intraday stock price change of S&P 500 constituents.