 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOOL4POI: A Tool-Augmented LLM Framework for Next POI Recommendation
Nov 09, 2025Next Point-of-Interest (POI) recommendation is a fundamental task in location-based services. While recent advances leverage Large Language Model (LLM) for sequential modeling, existing LLM-based approaches face two key limitations: (i) strong reliance on the contextual completeness of user histories, resulting in poor performance on out-of-history (OOH) scenarios; (ii) limited scalability, due to the restricted context window of LLMs, which limits their ability to access and process a large number of candidate POIs. To address these challenges, we propose Tool4POI, a novel tool-augmented framework that enables LLMs to perform open-set POI recommendation through external retrieval and reasoning. Tool4POI consists of three key modules: preference extraction module, multi-turn candidate retrieval module, and reranking module, which together summarize long-term user interests, interact with external tools to retrieve relevant POIs, and refine final recommendations based on recent behaviors. Unlike existing methods, Tool4POI requires no task-specific fine-tuning and is compatible with off-the-shelf LLMs in a plug-and-play manner. Extensive experiments on three real-world datasets show that Tool4POI substantially outperforms state-of-the-art baselines, achieving up to 40% accuracy on challenging OOH scenarios where existing methods fail, and delivering average improvements of 20% and 30% on Acc@5 and Acc@10, respectively.
CoCoLex: Confidence-guided Copy-based Decoding for Grounded Legal Text Generation
Aug 07, 2025Due to their ability to process long and complex contexts, LLMs can offer key benefits to the Legal domain, but their adoption has been hindered by their tendency to generate unfaithful, ungrounded, or hallucinatory outputs. While Retrieval-Augmented Generation offers a promising solution by grounding generations in external knowledge, it offers no guarantee that the provided context will be effectively integrated. To address this, context-aware decoding strategies have been proposed to amplify the influence of relevant context, but they usually do not explicitly enforce faithfulness to the context. In this work, we introduce Confidence-guided Copy-based Decoding for Legal Text Generation (CoCoLex)-a decoding strategy that dynamically interpolates the model produced vocabulary distribution with a distribution derived based on copying from the context. CoCoLex encourages direct copying based on the model's confidence, ensuring greater fidelity to the source. Experimental results on five legal benchmarks demonstrate that CoCoLex outperforms existing context-aware decoding methods, particularly in long-form generation tasks.
MMWiLoc: A Multi-Sensor Dataset and Robust Device-Free Localization Method Using Commercial Off-The-Shelf Millimeter Wave Wi-Fi Devices
Jun 13, 2025Device-free Wi-Fi sensing has numerous benefits in practical settings, as it eliminates the requirement for dedicated sensing devices and can be accomplished using current low-cost Wi-Fi devices. With the development of Wi-Fi standards, millimeter wave Wi-Fi devices with 60GHz operating frequency and up to 4GHz bandwidth have become commercially available. Although millimeter wave Wi-Fi presents great promise for Device-Free Wi-Fi sensing with increased bandwidth and beam-forming ability, there still lacks a method for localization using millimeter wave Wi-Fi. Here, we present two major contributions: First, we provide a comprehensive multi-sensor dataset that synchronously captures human movement data from millimeter wave Wi-Fi, 2.4GHz Wi-Fi, and millimeter wave radar sensors. This dataset enables direct performance comparisons across different sensing modalities and facilitates reproducible researches in indoor localization. Second, we introduce MMWiLoc, a novel localization method that achieves centimeter-level precision with low computational cost. MMWiLoc incorporates two components: beam pattern calibration using Expectation Maximization and target localization through Multi-Scale Compression Sensing. The system processes beam Signal-to-Noise Ratio (beamSNR) information from the beam-forming process to determine target Angle of Arrival (AoA), which is then fused across devices for localization. Our extensive evaluation demonstrates that MMWiLoc achieves centimeter-level precision, outperforming 2.4GHz Wi-Fi systems while maintaining competitive performance with high-precision radar systems. The dataset and examples processing code will be released after this paper is accepted at https://github.com/wowoyoho/MMWiLoc.
Merging Smarter, Generalizing Better: Enhancing Model Merging on OOD Data
Jun 10, 2025Multi-task learning (MTL) concurrently trains a model on diverse task datasets to exploit common features, thereby improving overall performance across the tasks. Recent studies have dedicated efforts to merging multiple independent model parameters into a unified model for MTL, thus circumventing the need for training data and expanding the scope of applicable scenarios of MTL. However, current approaches to model merging predominantly concentrate on enhancing performance within in-domain (ID) datasets, often overlooking their efficacy on out-of-domain (OOD) datasets. In this work, we proposed LwPTV (Layer-wise Pruning Task Vector) by building a saliency score, measuring the redundancy of parameters in task vectors. Designed in this way ours can achieve mask vector for each task and thus perform layer-wise pruning on the task vectors, only keeping the pre-trained model parameters at the corresponding layer in merged model. Owing to its flexibility, our method can be seamlessly integrated with most of existing model merging methods to improve their performance on OOD tasks. Extensive experiments demonstrate that the application of our method results in substantial enhancements in OOD performance while preserving the ability on ID tasks.
TTPA: Token-level Tool-use Preference Alignment Training Framework with Fine-grained Evaluation
May 26, 2025Existing tool-learning methods usually rely on supervised fine-tuning, they often overlook fine-grained optimization of internal tool call details, leading to limitations in preference alignment and error discrimination. To overcome these challenges, we propose Token-level Tool-use Preference Alignment Training Framework (TTPA), a training paradigm for constructing token-level tool-use preference datasets that align LLMs with fine-grained preferences using a novel error-oriented scoring mechanism. TTPA first introduces reversed dataset construction, a method for creating high-quality, multi-turn tool-use datasets by reversing the generation flow. Additionally, we propose Token-level Preference Sampling (TPS) to capture fine-grained preferences by modeling token-level differences during generation. To address biases in scoring, we introduce the Error-oriented Scoring Mechanism (ESM), which quantifies tool-call errors and can be used as a training signal. Extensive experiments on three diverse benchmark datasets demonstrate that TTPA significantly improves tool-using performance while showing strong generalization ability across models and datasets.
Scalable Weibull Graph Attention Autoencoder for Modeling Document Networks
Oct 13, 2024



Although existing variational graph autoencoders (VGAEs) have been widely used for modeling and generating graph-structured data, most of them are still not flexible enough to approximate the sparse and skewed latent node representations, especially those of document relational networks (DRNs) with discrete observations. To analyze a collection of interconnected documents, a typical branch of Bayesian models, specifically relational topic models (RTMs), has proven their efficacy in describing both link structures and document contents of DRNs, which motives us to incorporate RTMs with existing VGAEs to alleviate their potential issues when modeling the generation of DRNs. In this paper, moving beyond the sophisticated approximate assumptions of traditional RTMs, we develop a graph Poisson factor analysis (GPFA), which provides analytic conditional posteriors to improve the inference accuracy, and extend GPFA to a multi-stochastic-layer version named graph Poisson gamma belief network (GPGBN) to capture the hierarchical document relationships at multiple semantic levels. Then, taking GPGBN as the decoder, we combine it with various Weibull-based graph inference networks, resulting in two variants of Weibull graph auto-encoder (WGAE), equipped with model inference algorithms. Experimental results demonstrate that our models can extract high-quality hierarchical latent document representations and achieve promising performance on various graph analytic tasks.
TsCA: On the Semantic Consistency Alignment via Conditional Transport for Compositional Zero-Shot Learning
Aug 16, 2024



Compositional Zero-Shot Learning (CZSL) aims to recognize novel \textit{state-object} compositions by leveraging the shared knowledge of their primitive components. Despite considerable progress, effectively calibrating the bias between semantically similar multimodal representations, as well as generalizing pre-trained knowledge to novel compositional contexts, remains an enduring challenge. In this paper, our interest is to revisit the conditional transport (CT) theory and its homology to the visual-semantics interaction in CZSL and further, propose a novel Trisets Consistency Alignment framework (dubbed TsCA) that well-addresses these issues. Concretely, we utilize three distinct yet semantically homologous sets, i.e., patches, primitives, and compositions, to construct pairwise CT costs to minimize their semantic discrepancies. To further ensure the consistency transfer within these sets, we implement a cycle-consistency constraint that refines the learning by guaranteeing the feature consistency of the self-mapping during transport flow, regardless of modality. Moreover, we extend the CT plans to an open-world setting, which enables the model to effectively filter out unfeasible pairs, thereby speeding up the inference as well as increasing the accuracy. Extensive experiments are conducted to verify the effectiveness of the proposed method.
Instruction Tuning-free Visual Token Complement for Multimodal LLMs
Aug 09, 2024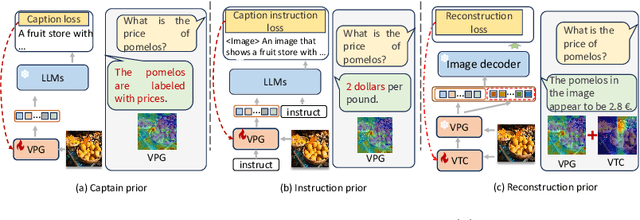
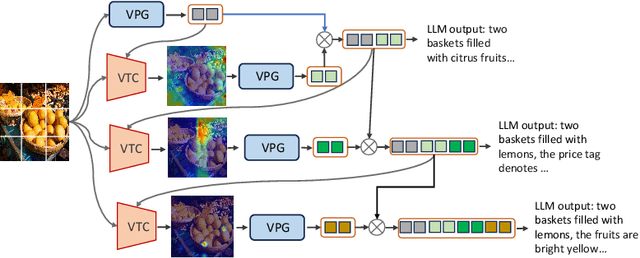
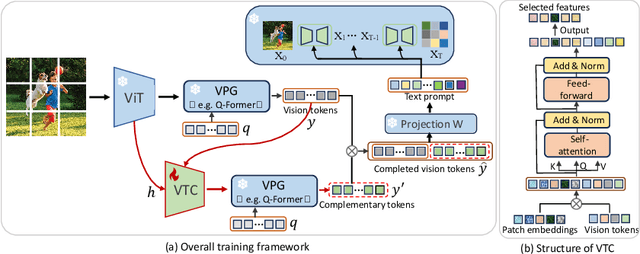
As the open community of large language models (LLMs) matures, multimodal LLMs (MLLMs) have promised an elegant bridge between vision and language. However, current research is inherently constrained by challenges such as the need for high-quality instruction pairs and the loss of visual information in image-to-text training objectives. To this end, we propose a Visual Token Complement framework (VTC) that helps MLLMs regain the missing visual features and thus improve response accuracy. Specifically, our VTC integrates text-to-image generation as a guide to identifying the text-irrelevant features, and a visual selector is then developed to generate complementary visual tokens to enrich the original visual input. Moreover, an iterative strategy is further designed to extract more visual information by iteratively using the visual selector without any additional training. Notably, the training pipeline requires no additional image-text pairs, resulting in a desired instruction tuning-free property. Both qualitative and quantitative experiments demonstrate the superiority and efficiency of our VTC.
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Apr 26, 2024Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.