 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Neighbor-Aware Semantics, Deciding by Open-form Flows: Towards Robust Zero-Shot Skeleton Action Recognition
Nov 12, 2025Recognizing unseen skeleton action categories remains highly challenging due to the absence of corresponding skeletal priors. Existing approaches generally follow an "align-then-classify" paradigm but face two fundamental issues, i.e., (i) fragile point-to-point alignment arising from imperfect semantics, and (ii) rigid classifiers restricted by static decision boundaries and coarse-grained anchors. To address these issues, we propose a novel method for zero-shot skeleton action recognition, termed $\texttt{$\textbf{Flora}$}$, which builds upon $\textbf{F}$lexib$\textbf{L}$e neighb$\textbf{O}$r-aware semantic attunement and open-form dist$\textbf{R}$ibution-aware flow cl$\textbf{A}$ssifier. Specifically, we flexibly attune textual semantics by incorporating neighboring inter-class contextual cues to form direction-aware regional semantics, coupled with a cross-modal geometric consistency objective that ensures stable and robust point-to-region alignment. Furthermore, we employ noise-free flow matching to bridge the modality distribution gap between semantic and skeleton latent embeddings, while a condition-free contrastive regularization enhances discriminability, leading to a distribution-aware classifier with fine-grained decision boundaries achieved through token-level velocity predictions. Extensive experiments on three benchmark datasets validate the effectiveness of our method, showing particularly impressive performance even when trained with only 10\% of the seen data. Code is available at https://github.com/cseeyangchen/Flora.
Exploring Transferable Homogeneous Groups for Compositional Zero-Shot Learning
Jan 18, 2025



Conditional dependency present one of the trickiest problems in Compositional Zero-Shot Learning, leading to significant property variations of the same state (object) across different objects (states). To address this problem, existing approaches often adopt either all-to-one or one-to-one representation paradigms. However, these extremes create an imbalance in the seesaw between transferability and discriminability, favoring one at the expense of the other. Comparatively, humans are adept at analogizing and reasoning in a hierarchical clustering manner, intuitively grouping categories with similar properties to form cohesive concepts. Motivated by this, we propose Homogeneous Group Representation Learning (HGRL), a new perspective formulates state (object) representation learning as multiple homogeneous sub-group representation learning. HGRL seeks to achieve a balance between semantic transferability and discriminability by adaptively discovering and aggregating categories with shared properties, learning distributed group centers that retain group-specific discriminative features. Our method integrates three core components designed to simultaneously enhance both the visual and prompt representation capabilities of the model. Extensive experiments on three benchmark datasets validate the effectiveness of our method.
TsCA: On the Semantic Consistency Alignment via Conditional Transport for Compositional Zero-Shot Learning
Aug 16, 2024



Compositional Zero-Shot Learning (CZSL) aims to recognize novel \textit{state-object} compositions by leveraging the shared knowledge of their primitive components. Despite considerable progress, effectively calibrating the bias between semantically similar multimodal representations, as well as generalizing pre-trained knowledge to novel compositional contexts, remains an enduring challenge. In this paper, our interest is to revisit the conditional transport (CT) theory and its homology to the visual-semantics interaction in CZSL and further, propose a novel Trisets Consistency Alignment framework (dubbed TsCA) that well-addresses these issues. Concretely, we utilize three distinct yet semantically homologous sets, i.e., patches, primitives, and compositions, to construct pairwise CT costs to minimize their semantic discrepancies. To further ensure the consistency transfer within these sets, we implement a cycle-consistency constraint that refines the learning by guaranteeing the feature consistency of the self-mapping during transport flow, regardless of modality. Moreover, we extend the CT plans to an open-world setting, which enables the model to effectively filter out unfeasible pairs, thereby speeding up the inference as well as increasing the accuracy. Extensive experiments are conducted to verify the effectiveness of the proposed method.
Instruction Tuning-free Visual Token Complement for Multimodal LLMs
Aug 09, 2024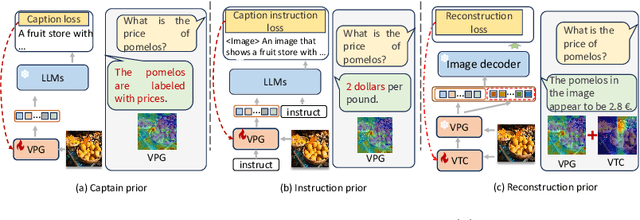
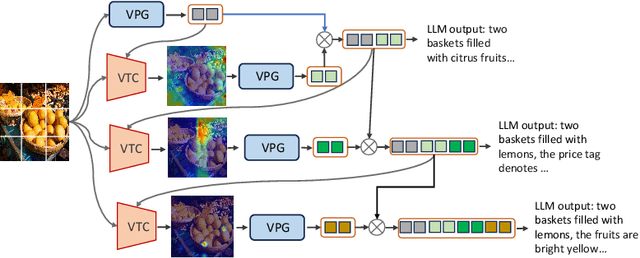
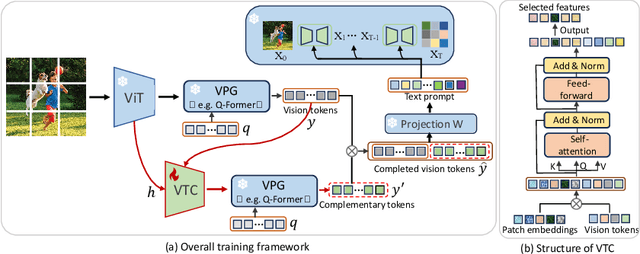
As the open community of large language models (LLMs) matures, multimodal LLMs (MLLMs) have promised an elegant bridge between vision and language. However, current research is inherently constrained by challenges such as the need for high-quality instruction pairs and the loss of visual information in image-to-text training objectives. To this end, we propose a Visual Token Complement framework (VTC) that helps MLLMs regain the missing visual features and thus improve response accuracy. Specifically, our VTC integrates text-to-image generation as a guide to identifying the text-irrelevant features, and a visual selector is then developed to generate complementary visual tokens to enrich the original visual input. Moreover, an iterative strategy is further designed to extract more visual information by iteratively using the visual selector without any additional training. Notably, the training pipeline requires no additional image-text pairs, resulting in a desired instruction tuning-free property. Both qualitative and quantitative experiments demonstrate the superiority and efficiency of our VTC.
Tuning Multi-mode Token-level Prompt Alignment across Modalities
Sep 25, 2023



Prompt tuning pre-trained vision-language models have demonstrated significant potential in improving open-world visual concept understanding. However, prior works only primarily focus on single-mode (only one prompt for each modality) and holistic level (image or sentence) semantic alignment, which fails to capture the sample diversity, leading to sub-optimal prompt discovery. To address the limitation, we propose a multi-mode token-level tuning framework that leverages the optimal transportation to learn and align a set of prompt tokens across modalities. Specifically, we rely on two essential factors: 1) multi-mode prompts discovery, which guarantees diverse semantic representations, and 2) token-level alignment, which helps explore fine-grained similarity. Thus, the similarity can be calculated as a hierarchical transportation problem between the modality-specific sets. Extensive experiments on popular image recognition benchmarks show the superior generalization and few-shot abilities of our approach. The qualitative analysis demonstrates that the learned prompt tokens have the ability to capture diverse visual concepts.
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image Classification
Jul 18, 2023



Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods. Our code is available at https://github.com/keepgoingjkg/PatchCT.
Patch-Token Aligned Bayesian Prompt Learning for Vision-Language Models
Mar 16, 2023For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt learning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize prompt learning with the visual knowledge and view images and the corresponding prompts as patch and token sets under optimal transport, which pushes the prompt tokens to faithfully capture the label-specific visual concepts, instead of overfitting the training categories. Moreover, the proposed model can also be straightforwardly extended to the conditional case where the instance-conditional prompts are generated to improve the generalizability. Extensive experiments on 15 datasets show promising transferability and generalization performance of our proposed model.
Knowledge-Aware Bayesian Deep Topic Model
Sep 20, 2022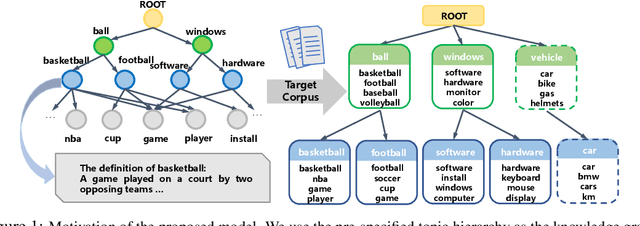
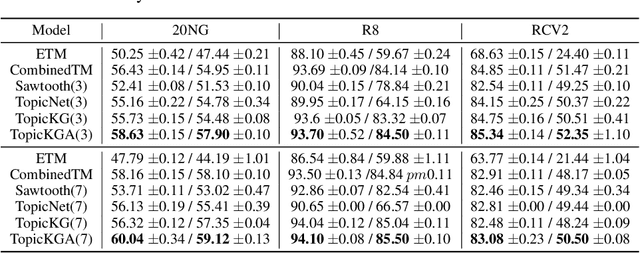
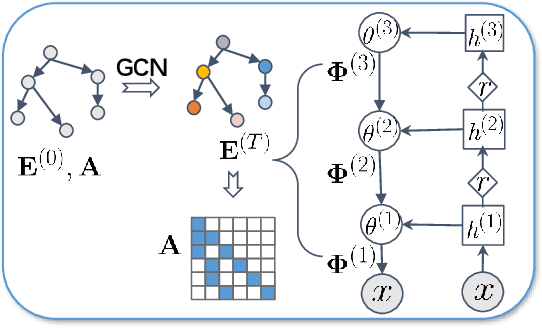

We propose a Bayesian generative model for incorporating prior domain knowledge into hierarchical topic modeling. Although embedded topic models (ETMs) and its variants have gained promising performance in text analysis, they mainly focus on mining word co-occurrence patterns, ignoring potentially easy-to-obtain prior topic hierarchies that could help enhance topic coherence. While several knowledge-based topic models have recently been proposed, they are either only applicable to shallow hierarchies or sensitive to the quality of the provided prior knowledge. To this end, we develop a novel deep ETM that jointly models the documents and the given prior knowledge by embedding the words and topics into the same space. Guided by the provided knowledge, the proposed model tends to discover topic hierarchies that are organized into interpretable taxonomies. Besides, with a technique for adapting a given graph, our extended version allows the provided prior topic structure to be finetuned to match the target corpus. Extensive experiments show that our proposed model efficiently integrates the prior knowledge and improves both hierarchical topic discovery and document representation.