 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNüwa: Mending the Spatial Integrity Torn by VLM Token Pruning
Feb 03, 2026Vision token pruning has proven to be an effective acceleration technique for the efficient Vision Language Model (VLM). However, existing pruning methods demonstrate excellent performance preservation in visual question answering (VQA) and suffer substantial degradation on visual grounding (VG) tasks. Our analysis of the VLM's processing pipeline reveals that strategies utilizing global semantic similarity and attention scores lose the global spatial reference frame, which is derived from the interactions of tokens' positional information. Motivated by these findings, we propose $\text{Nüwa}$, a two-stage token pruning framework that enables efficient feature aggregation while maintaining spatial integrity. In the first stage, after the vision encoder, we apply three operations, namely separation, alignment, and aggregation, which are inspired by swarm intelligence algorithms to retain information-rich global spatial anchors. In the second stage, within the LLM, we perform text-guided pruning to retain task-relevant visual tokens. Extensive experiments demonstrate that $\text{Nüwa}$ achieves SOTA performance on multiple VQA benchmarks (from 94% to 95%) and yields substantial improvements on visual grounding tasks (from 7% to 47%).
Multimodal Visual Surrogate Compression for Alzheimer's Disease Classification
Jan 29, 2026High-dimensional structural MRI (sMRI) images are widely used for Alzheimer's Disease (AD) diagnosis. Most existing methods for sMRI representation learning rely on 3D architectures (e.g., 3D CNNs), slice-wise feature extraction with late aggregation, or apply training-free feature extractions using 2D foundation models (e.g., DINO). However, these three paradigms suffer from high computational cost, loss of cross-slice relations, and limited ability to extract discriminative features, respectively. To address these challenges, we propose Multimodal Visual Surrogate Compression (MVSC). It learns to compress and adapt large 3D sMRI volumes into compact 2D features, termed as visual surrogates, which are better aligned with frozen 2D foundation models to extract powerful representations for final AD classification. MVSC has two key components: a Volume Context Encoder that captures global cross-slice context under textual guidance, and an Adaptive Slice Fusion module that aggregates slice-level information in a text-enhanced, patch-wise manner. Extensive experiments on three large-scale Alzheimer's disease benchmarks demonstrate our MVSC performs favourably on both binary and multi-class classification tasks compared against state-of-the-art methods.
PMCE: Probabilistic Multi-Granularity Semantics with Caption-Guided Enhancement for Few-Shot Learning
Jan 20, 2026Few-shot learning aims to identify novel categories from only a handful of labeled samples, where prototypes estimated from scarce data are often biased and generalize poorly. Semantic-based methods alleviate this by introducing coarse class-level information, but they are mostly applied on the support side, leaving query representations unchanged. In this paper, we present PMCE, a Probabilistic few-shot framework that leverages Multi-granularity semantics with Caption-guided Enhancement. PMCE constructs a nonparametric knowledge bank that stores visual statistics for each category as well as CLIP-encoded class name embeddings of the base classes. At meta-test time, the most relevant base classes are retrieved based on the similarities of class name embeddings for each novel category. These statistics are then aggregated into category-specific prior information and fused with the support set prototypes via a simple MAP update. Simultaneously, a frozen BLIP captioner provides label-free instance-level image descriptions, and a lightweight enhancer trained on base classes optimizes both support prototypes and query features under an inductive protocol with a consistency regularization to stabilize noisy captions. Experiments on four benchmarks show that PMCE consistently improves over strong baselines, achieving up to 7.71% absolute gain over the strongest semantic competitor on MiniImageNet in the 1-shot setting. Our code is available at https://anonymous.4open.science/r/PMCE-275D
Fine-Grained Zero-Shot Learning with Attribute-Centric Representations
Dec 13, 2025Recognizing unseen fine-grained categories demands a model that can distinguish subtle visual differences. This is typically achieved by transferring visual-attribute relationships from seen classes to unseen classes. The core challenge is attribute entanglement, where conventional models collapse distinct attributes like color, shape, and texture into a single visual embedding. This causes interference that masks these critical distinctions. The post-hoc solutions of previous work are insufficient, as they operate on representations that are already mixed. We propose a zero-shot learning framework that learns AttributeCentric Representations (ACR) to tackle this problem by imposing attribute disentanglement during representation learning. ACR is achieved with two mixture-of-experts components, including Mixture of Patch Experts (MoPE) and Mixture of Attribute Experts (MoAE). First, MoPE is inserted into the transformer using a dual-level routing mechanism to conditionally dispatch image patches to specialized experts. This ensures coherent attribute families are processed by dedicated experts. Finally, the MoAE head projects these expert-refined features into sparse, partaware attribute maps for robust zero-shot classification. On zero-shot learning benchmark datasets CUB, AwA2, and SUN, our ACR achieves consistent state-of-the-art results.
Learning by Neighbor-Aware Semantics, Deciding by Open-form Flows: Towards Robust Zero-Shot Skeleton Action Recognition
Nov 12, 2025Recognizing unseen skeleton action categories remains highly challenging due to the absence of corresponding skeletal priors. Existing approaches generally follow an "align-then-classify" paradigm but face two fundamental issues, i.e., (i) fragile point-to-point alignment arising from imperfect semantics, and (ii) rigid classifiers restricted by static decision boundaries and coarse-grained anchors. To address these issues, we propose a novel method for zero-shot skeleton action recognition, termed $\texttt{$\textbf{Flora}$}$, which builds upon $\textbf{F}$lexib$\textbf{L}$e neighb$\textbf{O}$r-aware semantic attunement and open-form dist$\textbf{R}$ibution-aware flow cl$\textbf{A}$ssifier. Specifically, we flexibly attune textual semantics by incorporating neighboring inter-class contextual cues to form direction-aware regional semantics, coupled with a cross-modal geometric consistency objective that ensures stable and robust point-to-region alignment. Furthermore, we employ noise-free flow matching to bridge the modality distribution gap between semantic and skeleton latent embeddings, while a condition-free contrastive regularization enhances discriminability, leading to a distribution-aware classifier with fine-grained decision boundaries achieved through token-level velocity predictions. Extensive experiments on three benchmark datasets validate the effectiveness of our method, showing particularly impressive performance even when trained with only 10\% of the seen data. Code is available at https://github.com/cseeyangchen/Flora.
ICM-Fusion: In-Context Meta-Optimized LoRA Fusion for Multi-Task Adaptation
Aug 06, 2025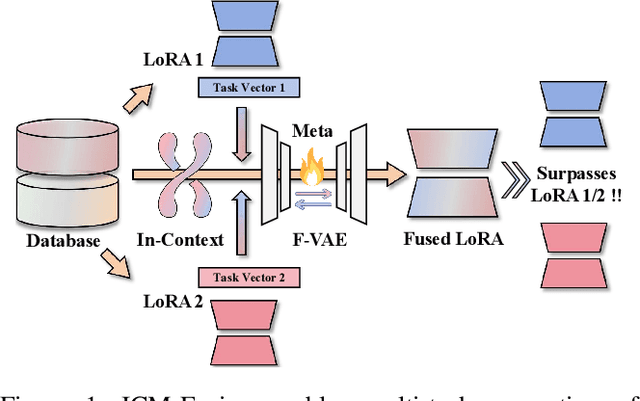
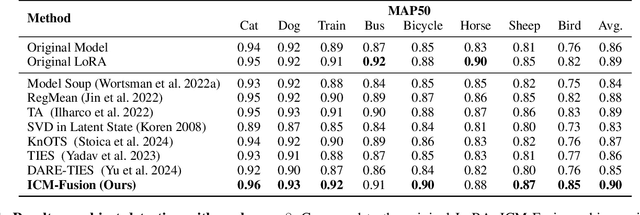
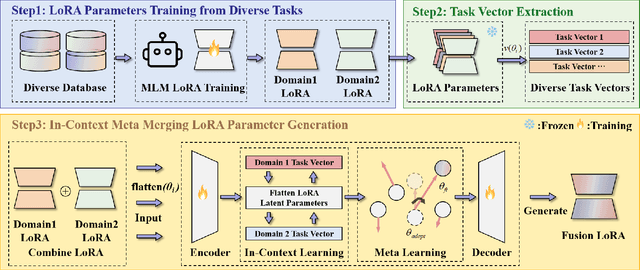
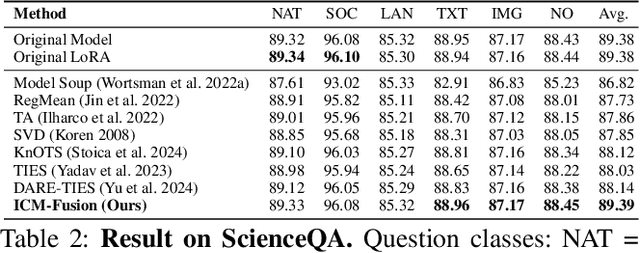
Enabling multi-task adaptation in pre-trained Low-Rank Adaptation (LoRA) models is crucial for enhancing their generalization capabilities. Most existing pre-trained LoRA fusion methods decompose weight matrices, sharing similar parameters while merging divergent ones. However, this paradigm inevitably induces inter-weight conflicts and leads to catastrophic domain forgetting. While incremental learning enables adaptation to multiple tasks, it struggles to achieve generalization in few-shot scenarios. Consequently, when the weight data follows a long-tailed distribution, it can lead to forgetting in the fused weights. To address this issue, we propose In-Context Meta LoRA Fusion (ICM-Fusion), a novel framework that synergizes meta-learning with in-context adaptation. The key innovation lies in our task vector arithmetic, which dynamically balances conflicting optimization directions across domains through learned manifold projections. ICM-Fusion obtains the optimal task vector orientation for the fused model in the latent space by adjusting the orientation of the task vectors. Subsequently, the fused LoRA is reconstructed by a self-designed Fusion VAE (F-VAE) to realize multi-task LoRA generation. We have conducted extensive experiments on visual and linguistic tasks, and the experimental results demonstrate that ICM-Fusion can be adapted to a wide range of architectural models and applied to various tasks. Compared to the current pre-trained LoRA fusion method, ICM-Fusion fused LoRA can significantly reduce the multi-tasking loss and can even achieve task enhancement in few-shot scenarios.
KG-Augmented Executable CoT for Mathematical Coding
Aug 06, 2025In recent years, large language models (LLMs) have excelled in natural language processing tasks but face significant challenges in complex reasoning tasks such as mathematical reasoning and code generation. To address these limitations, we propose KG-Augmented Executable Chain-of-Thought (KGA-ECoT), a novel framework that enhances code generation through knowledge graphs and improves mathematical reasoning via executable code. KGA-ECoT decomposes problems into a Structured Task Graph, leverages efficient GraphRAG for precise knowledge retrieval from mathematical libraries, and generates verifiable code to ensure computational accuracy. Evaluations on multiple mathematical reasoning benchmarks demonstrate that KGA-ECoT significantly outperforms existing prompting methods, achieving absolute accuracy improvements ranging from several to over ten percentage points. Further analysis confirms the critical roles of GraphRAG in enhancing code quality and external code execution in ensuring precision. These findings collectively establish KGA-ECoT as a robust and highly generalizable framework for complex mathematical reasoning tasks.
SVIP: Semantically Contextualized Visual Patches for Zero-Shot Learning
Mar 13, 2025



Zero-shot learning (ZSL) aims to recognize unseen classes without labeled training examples by leveraging class-level semantic descriptors such as attributes. A fundamental challenge in ZSL is semantic misalignment, where semantic-unrelated information involved in visual features introduce ambiguity to visual-semantic interaction. Unlike existing methods that suppress semantic-unrelated information post hoc either in the feature space or the model space, we propose addressing this issue at the input stage, preventing semantic-unrelated patches from propagating through the network. To this end, we introduce Semantically contextualized VIsual Patches (SVIP) for ZSL, a transformer-based framework designed to enhance visual-semantic alignment. Specifically, we propose a self-supervised patch selection mechanism that preemptively learns to identify semantic-unrelated patches in the input space. This is trained with the supervision from aggregated attention scores across all transformer layers, which estimate each patch's semantic score. As removing semantic-unrelated patches from the input sequence may disrupt object structure, we replace them with learnable patch embeddings. With initialization from word embeddings, we can ensure they remain semantically meaningful throughout feature extraction. Extensive experiments on ZSL benchmarks demonstrate that SVIP achieves state-of-the-art performance results while providing more interpretable and semantically rich feature representations.
TR-DQ: Time-Rotation Diffusion Quantization
Mar 09, 2025Diffusion models have been widely adopted in image and video generation. However, their complex network architecture leads to high inference overhead for its generation process. Existing diffusion quantization methods primarily focus on the quantization of the model structure while ignoring the impact of time-steps variation during sampling. At the same time, most current approaches fail to account for significant activations that cannot be eliminated, resulting in substantial performance degradation after quantization. To address these issues, we propose Time-Rotation Diffusion Quantization (TR-DQ), a novel quantization method incorporating time-step and rotation-based optimization. TR-DQ first divides the sampling process based on time-steps and applies a rotation matrix to smooth activations and weights dynamically. For different time-steps, a dedicated hyperparameter is introduced for adaptive timing modeling, which enables dynamic quantization across different time steps. Additionally, we also explore the compression potential of Classifier-Free Guidance (CFG-wise) to establish a foundation for subsequent work. TR-DQ achieves state-of-the-art (SOTA) performance on image generation and video generation tasks and a 1.38-1.89x speedup and 1.97-2.58x memory reduction in inference compared to existing quantization methods.
FedAPA: Server-side Gradient-Based Adaptive Personalized Aggregation for Federated Learning on Heterogeneous Data
Feb 11, 2025Personalized federated learning (PFL) tailors models to clients' unique data distributions while preserving privacy. However, existing aggregation-weight-based PFL methods often struggle with heterogeneous data, facing challenges in accuracy, computational efficiency, and communication overhead. We propose FedAPA, a novel PFL method featuring a server-side, gradient-based adaptive aggregation strategy to generate personalized models, by updating aggregation weights based on gradients of client-parameter changes with respect to the aggregation weights in a centralized manner. FedAPA guarantees theoretical convergence and achieves superior accuracy and computational efficiency compared to 10 PFL competitors across three datasets, with competitive communication overhead.