 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAPA: Server-side Gradient-Based Adaptive Personalized Aggregation for Federated Learning on Heterogeneous Data
Feb 11, 2025Personalized federated learning (PFL) tailors models to clients' unique data distributions while preserving privacy. However, existing aggregation-weight-based PFL methods often struggle with heterogeneous data, facing challenges in accuracy, computational efficiency, and communication overhead. We propose FedAPA, a novel PFL method featuring a server-side, gradient-based adaptive aggregation strategy to generate personalized models, by updating aggregation weights based on gradients of client-parameter changes with respect to the aggregation weights in a centralized manner. FedAPA guarantees theoretical convergence and achieves superior accuracy and computational efficiency compared to 10 PFL competitors across three datasets, with competitive communication overhead.
RoMA: Robust Malware Attribution via Byte-level Adversarial Training with Global Perturbations and Adversarial Consistency Regularization
Feb 11, 2025Attributing APT (Advanced Persistent Threat) malware to their respective groups is crucial for threat intelligence and cybersecurity. However, APT adversaries often conceal their identities, rendering attribution inherently adversarial. Existing machine learning-based attribution models, while effective, remain highly vulnerable to adversarial attacks. For example, the state-of-the-art byte-level model MalConv sees its accuracy drop from over 90% to below 2% under PGD (projected gradient descent) attacks. Existing gradient-based adversarial training techniques for malware detection or image processing were applied to malware attribution in this study, revealing that both robustness and training efficiency require significant improvement. To address this, we propose RoMA, a novel single-step adversarial training approach that integrates global perturbations to generate enhanced adversarial samples and employs adversarial consistency regularization to improve representation quality and resilience. A novel APT malware dataset named AMG18, with diverse samples and realistic class imbalances, is introduced for evaluation. Extensive experiments show that RoMA significantly outperforms seven competing methods in both adversarial robustness (e.g., achieving over 80% robust accuracy-more than twice that of the next-best method under PGD attacks) and training efficiency (e.g., more than twice as fast as the second-best method in terms of accuracy), while maintaining superior standard accuracy in non-adversarial scenarios.
MDENet: Multi-modal Dual-embedding Networks for Malware Open-set Recognition
May 02, 2023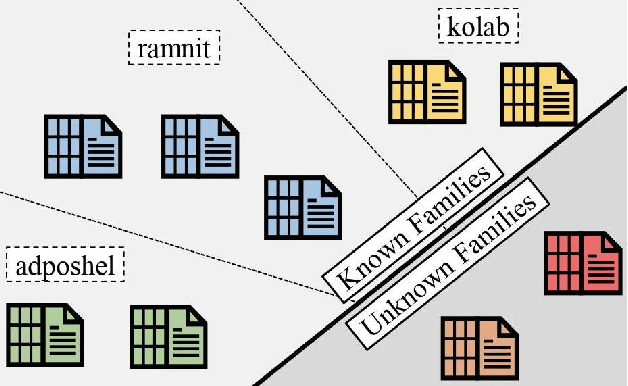
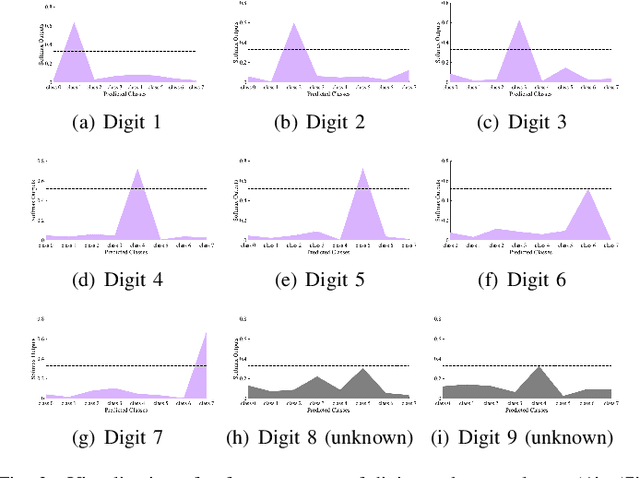
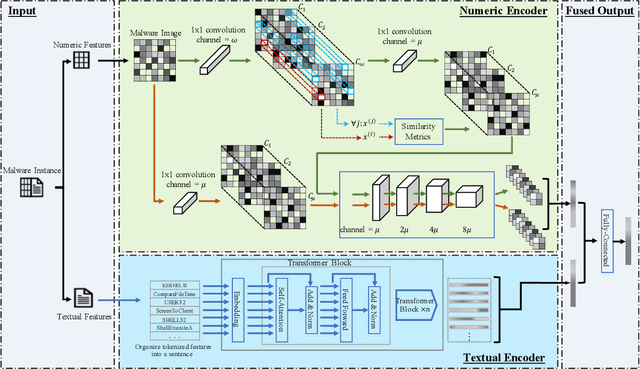
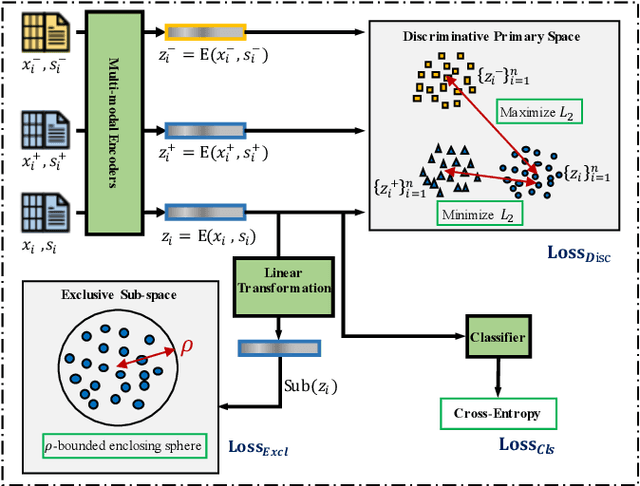
Malware open-set recognition (MOSR) aims at jointly classifying malware samples from known families and detect the ones from novel unknown families, respectively. Existing works mostly rely on a well-trained classifier considering the predicted probabilities of each known family with a threshold-based detection to achieve the MOSR. However, our observation reveals that the feature distributions of malware samples are extremely similar to each other even between known and unknown families. Thus the obtained classifier may produce overly high probabilities of testing unknown samples toward known families and degrade the model performance. In this paper, we propose the Multi-modal Dual-Embedding Networks, dubbed MDENet, to take advantage of comprehensive malware features (i.e., malware images and malware sentences) from different modalities to enhance the diversity of malware feature space, which is more representative and discriminative for down-stream recognition. Last, to further guarantee the open-set recognition, we dually embed the fused multi-modal representation into one primary space and an associated sub-space, i.e., discriminative and exclusive spaces, with contrastive sampling and rho-bounded enclosing sphere regularizations, which resort to classification and detection, respectively. Moreover, we also enrich our previously proposed large-scaled malware dataset MAL-100 with multi-modal characteristics and contribute an improved version dubbed MAL-100+. Experimental results on the widely used malware dataset Mailing and the proposed MAL-100+ demonstrate the effectiveness of our method.
CNS-Net: Conservative Novelty Synthesizing Network for Malware Recognition in an Open-set Scenario
May 02, 2023We study the challenging task of malware recognition on both known and novel unknown malware families, called malware open-set recognition (MOSR). Previous works usually assume the malware families are known to the classifier in a close-set scenario, i.e., testing families are the subset or at most identical to training families. However, novel unknown malware families frequently emerge in real-world applications, and as such, require to recognize malware instances in an open-set scenario, i.e., some unknown families are also included in the test-set, which has been rarely and non-thoroughly investigated in the cyber-security domain. One practical solution for MOSR may consider jointly classifying known and detecting unknown malware families by a single classifier (e.g., neural network) from the variance of the predicted probability distribution on known families. However, conventional well-trained classifiers usually tend to obtain overly high recognition probabilities in the outputs, especially when the instance feature distributions are similar to each other, e.g., unknown v.s. known malware families, and thus dramatically degrades the recognition on novel unknown malware families. In this paper, we propose a novel model that can conservatively synthesize malware instances to mimic unknown malware families and support a more robust training of the classifier. Moreover, we also build a new large-scale malware dataset, named MAL-100, to fill the gap of lacking large open-set malware benchmark dataset. Experimental results on two widely used malware datasets and our MAL-100 demonstrate the effectiveness of our model compared with other representative methods.