 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNS-Net: Conservative Novelty Synthesizing Network for Malware Recognition in an Open-set Scenario
May 02, 2023We study the challenging task of malware recognition on both known and novel unknown malware families, called malware open-set recognition (MOSR). Previous works usually assume the malware families are known to the classifier in a close-set scenario, i.e., testing families are the subset or at most identical to training families. However, novel unknown malware families frequently emerge in real-world applications, and as such, require to recognize malware instances in an open-set scenario, i.e., some unknown families are also included in the test-set, which has been rarely and non-thoroughly investigated in the cyber-security domain. One practical solution for MOSR may consider jointly classifying known and detecting unknown malware families by a single classifier (e.g., neural network) from the variance of the predicted probability distribution on known families. However, conventional well-trained classifiers usually tend to obtain overly high recognition probabilities in the outputs, especially when the instance feature distributions are similar to each other, e.g., unknown v.s. known malware families, and thus dramatically degrades the recognition on novel unknown malware families. In this paper, we propose a novel model that can conservatively synthesize malware instances to mimic unknown malware families and support a more robust training of the classifier. Moreover, we also build a new large-scale malware dataset, named MAL-100, to fill the gap of lacking large open-set malware benchmark dataset. Experimental results on two widely used malware datasets and our MAL-100 demonstrate the effectiveness of our model compared with other representative methods.
MAANet: Multi-view Aware Attention Networks for Image Super-Resolution
Apr 12, 2019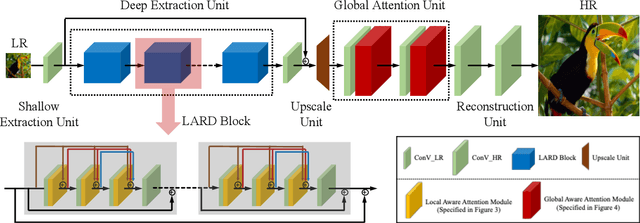
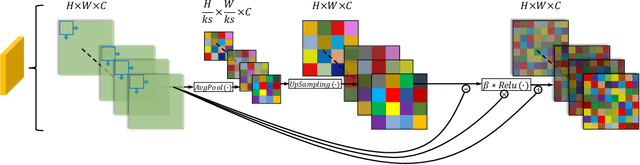
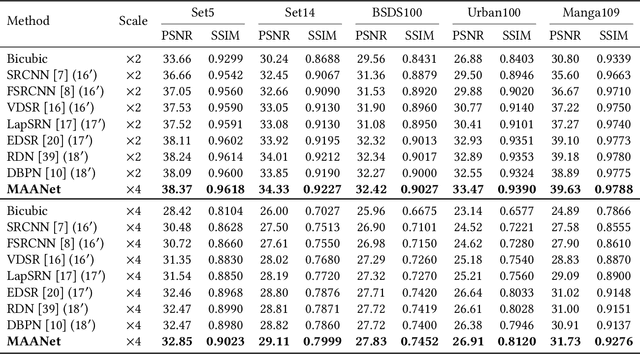
In most recent years, deep convolutional neural networks (DCNNs) based image super-resolution (SR) has gained increasing attention in multimedia and computer vision communities, focusing on restoring the high-resolution (HR) image from a low-resolution (LR) image. However, one nonnegligible flaw of DCNNs based methods is that most of them are not able to restore high-resolution images containing sufficient high-frequency information from low-resolution images with low-frequency information redundancy. Worse still, as the depth of DCNNs increases, the training easily encounters the problem of vanishing gradients, which makes the training more difficult. These problems hinder the effectiveness of DCNNs in image SR task. To solve these problems, we propose the Multi-view Aware Attention Networks (MAANet) for image SR task. Specifically, we propose the local aware (LA) and global aware (GA) attention to deal with LR features in unequal manners, which can highlight the high-frequency components and discriminate each feature from LR images in the local and the global views, respectively. Furthermore, we propose the local attentive residual-dense (LARD) block, which combines the LA attention with multiple residual and dense connections, to fit a deeper yet easy to train architecture. The experimental results show that our proposed approach can achieve remarkable performance compared with other state-of-the-art methods.
Position-Aware Convolutional Networks for Traffic Prediction
Apr 12, 2019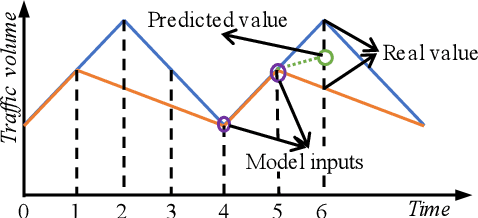
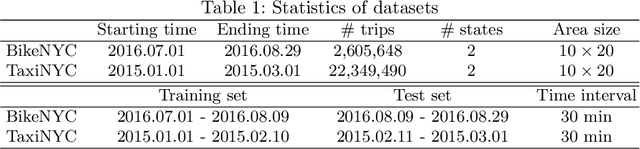
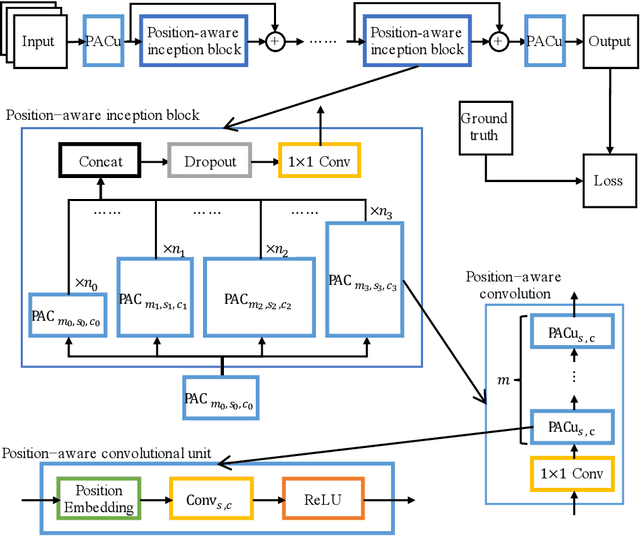
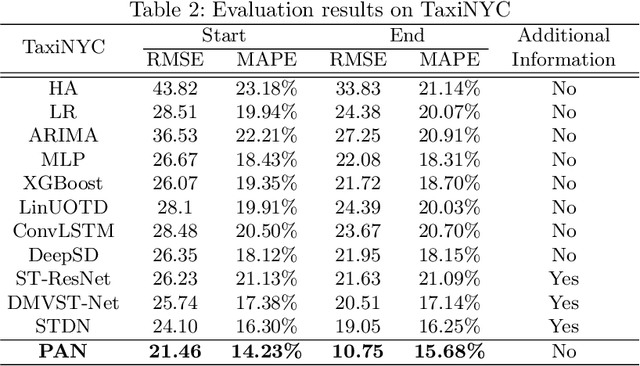
Forecasting the future traffic flow distribution in an area is an important issue for traffic management in an intelligent transportation system. The key challenge of traffic prediction is to capture spatial and temporal relations between future traffic flows and historical traffic due to highly dynamical patterns of human activities. Most existing methods explore such relations by fusing spatial and temporal features extracted from multi-source data. However, they neglect position information which helps distinguish patterns on different positions. In this paper, we propose a position-aware neural network that integrates data features and position information. Our approach employs the inception backbone network to capture rich features of traffic distribution on the whole area. The novelty lies in that under the backbone network, we apply position embedding technique used in neural language processing to represent position information as embedding vectors which are learned during the training. With these embedding vectors, we design position-aware convolution which allows different kernels to process features of different positions. Extensive experiments on two real-world datasets show that our approach outperforms previous methods even with fewer data sources.