 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAANet: Multi-view Aware Attention Networks for Image Super-Resolution
Paper and Code
Apr 12, 2019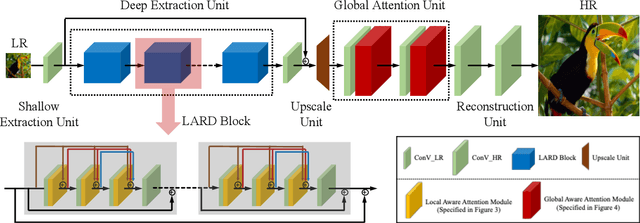
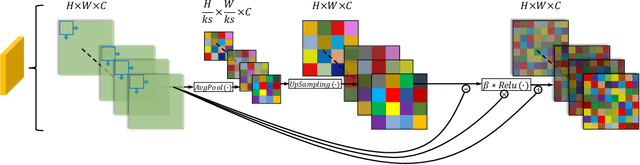
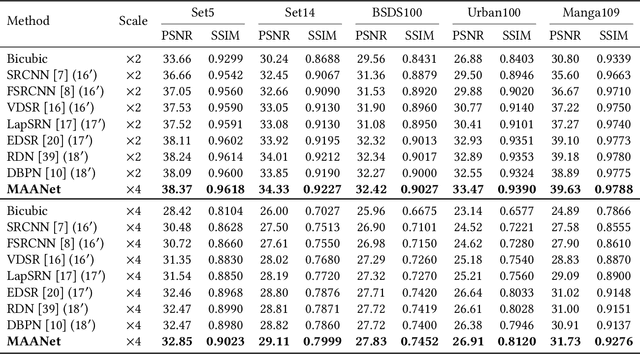
In most recent years, deep convolutional neural networks (DCNNs) based image super-resolution (SR) has gained increasing attention in multimedia and computer vision communities, focusing on restoring the high-resolution (HR) image from a low-resolution (LR) image. However, one nonnegligible flaw of DCNNs based methods is that most of them are not able to restore high-resolution images containing sufficient high-frequency information from low-resolution images with low-frequency information redundancy. Worse still, as the depth of DCNNs increases, the training easily encounters the problem of vanishing gradients, which makes the training more difficult. These problems hinder the effectiveness of DCNNs in image SR task. To solve these problems, we propose the Multi-view Aware Attention Networks (MAANet) for image SR task. Specifically, we propose the local aware (LA) and global aware (GA) attention to deal with LR features in unequal manners, which can highlight the high-frequency components and discriminate each feature from LR images in the local and the global views, respectively. Furthermore, we propose the local attentive residual-dense (LARD) block, which combines the LA attention with multiple residual and dense connections, to fit a deeper yet easy to train architecture. The experimental results show that our proposed approach can achieve remarkable performance compared with other state-of-the-art methods.