 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICM-Fusion: In-Context Meta-Optimized LoRA Fusion for Multi-Task Adaptation
Aug 06, 2025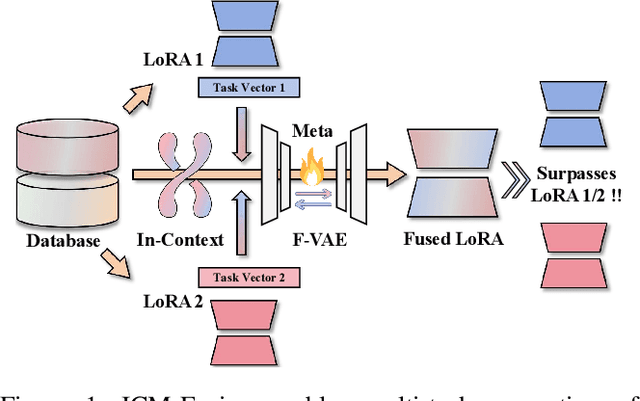
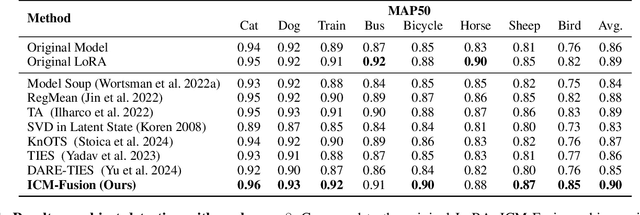
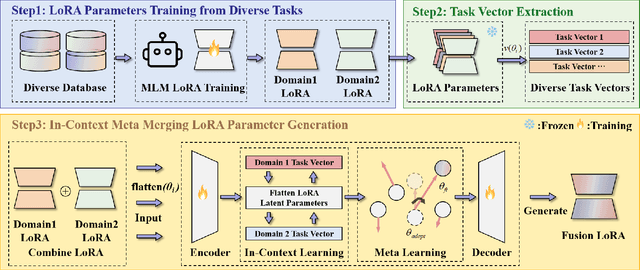
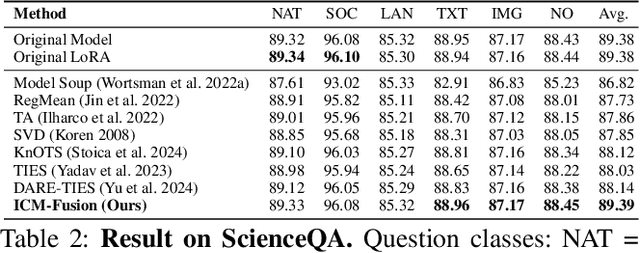
Enabling multi-task adaptation in pre-trained Low-Rank Adaptation (LoRA) models is crucial for enhancing their generalization capabilities. Most existing pre-trained LoRA fusion methods decompose weight matrices, sharing similar parameters while merging divergent ones. However, this paradigm inevitably induces inter-weight conflicts and leads to catastrophic domain forgetting. While incremental learning enables adaptation to multiple tasks, it struggles to achieve generalization in few-shot scenarios. Consequently, when the weight data follows a long-tailed distribution, it can lead to forgetting in the fused weights. To address this issue, we propose In-Context Meta LoRA Fusion (ICM-Fusion), a novel framework that synergizes meta-learning with in-context adaptation. The key innovation lies in our task vector arithmetic, which dynamically balances conflicting optimization directions across domains through learned manifold projections. ICM-Fusion obtains the optimal task vector orientation for the fused model in the latent space by adjusting the orientation of the task vectors. Subsequently, the fused LoRA is reconstructed by a self-designed Fusion VAE (F-VAE) to realize multi-task LoRA generation. We have conducted extensive experiments on visual and linguistic tasks, and the experimental results demonstrate that ICM-Fusion can be adapted to a wide range of architectural models and applied to various tasks. Compared to the current pre-trained LoRA fusion method, ICM-Fusion fused LoRA can significantly reduce the multi-tasking loss and can even achieve task enhancement in few-shot scenarios.
TR-DQ: Time-Rotation Diffusion Quantization
Mar 09, 2025Diffusion models have been widely adopted in image and video generation. However, their complex network architecture leads to high inference overhead for its generation process. Existing diffusion quantization methods primarily focus on the quantization of the model structure while ignoring the impact of time-steps variation during sampling. At the same time, most current approaches fail to account for significant activations that cannot be eliminated, resulting in substantial performance degradation after quantization. To address these issues, we propose Time-Rotation Diffusion Quantization (TR-DQ), a novel quantization method incorporating time-step and rotation-based optimization. TR-DQ first divides the sampling process based on time-steps and applies a rotation matrix to smooth activations and weights dynamically. For different time-steps, a dedicated hyperparameter is introduced for adaptive timing modeling, which enables dynamic quantization across different time steps. Additionally, we also explore the compression potential of Classifier-Free Guidance (CFG-wise) to establish a foundation for subsequent work. TR-DQ achieves state-of-the-art (SOTA) performance on image generation and video generation tasks and a 1.38-1.89x speedup and 1.97-2.58x memory reduction in inference compared to existing quantization methods.
In-Context Meta LoRA Generation
Jan 30, 2025



Low-rank Adaptation (LoRA) has demonstrated remarkable capabilities for task specific fine-tuning. However, in scenarios that involve multiple tasks, training a separate LoRA model for each one results in considerable inefficiency in terms of storage and inference. Moreover, existing parameter generation methods fail to capture the correlations among these tasks, making multi-task LoRA parameter generation challenging. To address these limitations, we propose In-Context Meta LoRA (ICM-LoRA), a novel approach that efficiently achieves task-specific customization of large language models (LLMs). Specifically, we use training data from all tasks to train a tailored generator, Conditional Variational Autoencoder (CVAE). CVAE takes task descriptions as inputs and produces task-aware LoRA weights as outputs. These LoRA weights are then merged with LLMs to create task-specialized models without the need for additional fine-tuning. Furthermore, we utilize in-context meta-learning for knowledge enhancement and task mapping, to capture the relationship between tasks and parameter distributions. As a result, our method achieves more accurate LoRA parameter generation for diverse tasks using CVAE. ICM-LoRA enables more accurate LoRA parameter reconstruction than current parameter reconstruction methods and is useful for implementing task-specific enhancements of LoRA parameters. At the same time, our method occupies 283MB, only 1\% storage compared with the original LoRA.
GWQ: Gradient-Aware Weight Quantization for Large Language Models
Oct 30, 2024
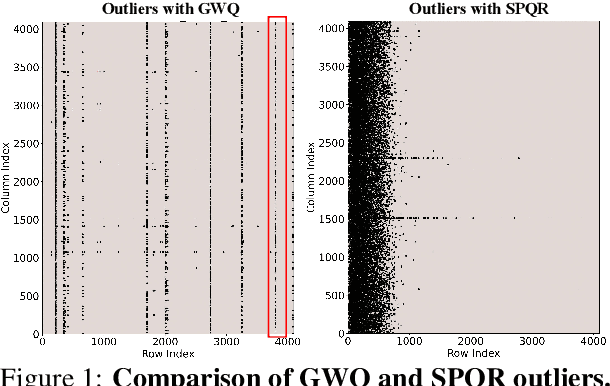
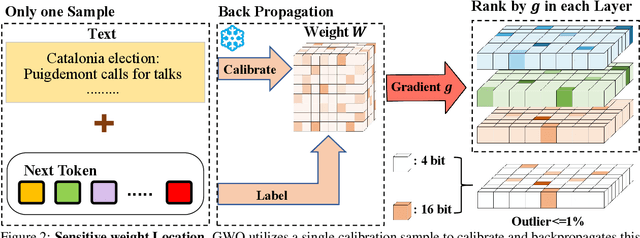
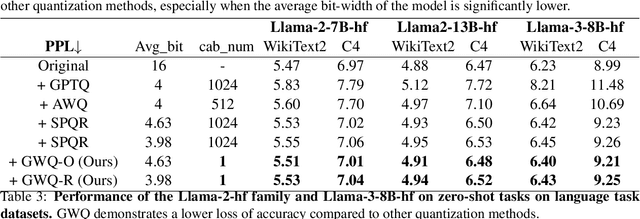
Large language models (LLMs) show impressive performance in solving complex languagetasks. However, its large number of parameterspresent significant challenges for the deployment and application of the model on edge devices. Compressing large language models to low bits can enable them to run on resource-constrained devices, often leading to performance degradation. To address this problem, we propose gradient-aware weight quantization (GWQ), the first quantization approach for low-bit weight quantization that leverages gradients to localize outliers, requiring only a minimal amount of calibration data for outlier detection. GWQ retains the weights corresponding to the top 1% outliers preferentially at FP16 precision, while the remaining non-outlier weights are stored in a low-bit format. GWQ found experimentally that utilizing the sensitive weights in the gradient localization model is more scientific compared to utilizing the sensitive weights in the Hessian matrix localization model. Compared to current quantization methods, GWQ can be applied to multiple language models and achieves lower PPL on the WikiText2 and C4 dataset. In the zero-shot task, GWQ quantized models have higher accuracy compared to other quantization methods.GWQ is also suitable for multimodal model quantization, and the quantized Qwen-VL family model is more accurate than other methods. zero-shot target detection task dataset RefCOCO outperforms the current stat-of-the-arts method SPQR. GWQ achieves 1.2x inference speedup in comparison to the original model, and effectively reduces the inference memory.