 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGWQ: Gradient-Aware Weight Quantization for Large Language Models
Oct 30, 2024
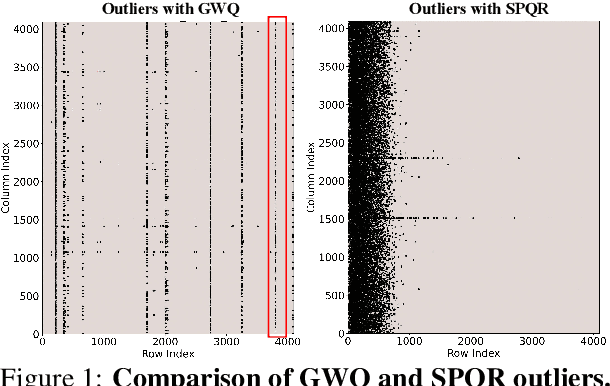
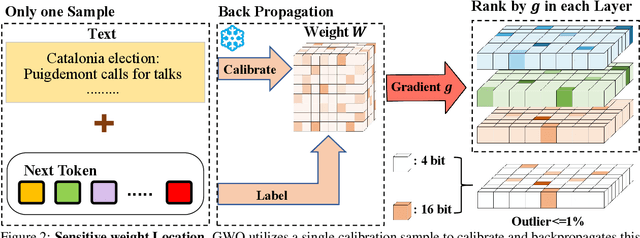
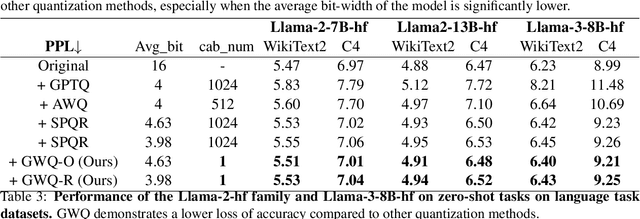
Large language models (LLMs) show impressive performance in solving complex languagetasks. However, its large number of parameterspresent significant challenges for the deployment and application of the model on edge devices. Compressing large language models to low bits can enable them to run on resource-constrained devices, often leading to performance degradation. To address this problem, we propose gradient-aware weight quantization (GWQ), the first quantization approach for low-bit weight quantization that leverages gradients to localize outliers, requiring only a minimal amount of calibration data for outlier detection. GWQ retains the weights corresponding to the top 1% outliers preferentially at FP16 precision, while the remaining non-outlier weights are stored in a low-bit format. GWQ found experimentally that utilizing the sensitive weights in the gradient localization model is more scientific compared to utilizing the sensitive weights in the Hessian matrix localization model. Compared to current quantization methods, GWQ can be applied to multiple language models and achieves lower PPL on the WikiText2 and C4 dataset. In the zero-shot task, GWQ quantized models have higher accuracy compared to other quantization methods.GWQ is also suitable for multimodal model quantization, and the quantized Qwen-VL family model is more accurate than other methods. zero-shot target detection task dataset RefCOCO outperforms the current stat-of-the-arts method SPQR. GWQ achieves 1.2x inference speedup in comparison to the original model, and effectively reduces the inference memory.
A Practice-Friendly Two-Stage LLM-Enhanced Paradigm in Sequential Recommendation
Jun 01, 2024The training paradigm integrating large language models (LLM) is gradually reshaping sequential recommender systems (SRS) and has shown promising results. However, most existing LLM-enhanced methods rely on rich textual information on the item side and instance-level supervised fine-tuning (SFT) to inject collaborative information into LLM, which is inefficient and limited in many applications. To alleviate these problems, this paper proposes a novel practice-friendly two-stage LLM-enhanced paradigm (TSLRec) for SRS. Specifically, in the information reconstruction stage, we design a new user-level SFT task for collaborative information injection with the assistance of a pre-trained SRS model, which is more efficient and compatible with limited text information. We aim to let LLM try to infer the latent category of each item and reconstruct the corresponding user's preference distribution for all categories from the user's interaction sequence. In the information augmentation stage, we feed each item into LLM to obtain a set of enhanced embeddings that combine collaborative information and LLM inference capabilities. These embeddings can then be used to help train various future SRS models. Finally, we verify the effectiveness and efficiency of our TSLRec on three SRS benchmark datasets.
HazardNet: Road Debris Detection by Augmentation of Synthetic Models
Mar 14, 2023



We present an algorithm to detect unseen road debris using a small set of synthetic models. Early detection of road debris is critical for safe autonomous or assisted driving, yet the development of a robust road debris detection model has not been widely discussed. There are two main challenges to building a road debris detector: first, data collection of road debris is challenging since hazardous objects on the road are rare to encounter in real driving scenarios; second, the variability of road debris is broad, ranging from a very small brick to a large fallen tree. To overcome these challenges, we propose a novel approach to few-shot learning of road debris that uses semantic augmentation and domain randomization to augment real road images with synthetic models. We constrain the problem domain to uncommon objects on the road and allow the deep neural network, HazardNet, to learn the semantic meaning of road debris to eventually detect unseen road debris. Our results demonstrate that HazardNet is able to accurately detect real road debris when only trained on synthetic objects in augmented images.