 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical SAM3: A Foundation Model for Universal Prompt-Driven Medical Image Segmentation
Jan 15, 2026Promptable segmentation foundation models such as SAM3 have demonstrated strong generalization capabilities through interactive and concept-based prompting. However, their direct applicability to medical image segmentation remains limited by severe domain shifts, the absence of privileged spatial prompts, and the need to reason over complex anatomical and volumetric structures. Here we present Medical SAM3, a foundation model for universal prompt-driven medical image segmentation, obtained by fully fine-tuning SAM3 on large-scale, heterogeneous 2D and 3D medical imaging datasets with paired segmentation masks and text prompts. Through a systematic analysis of vanilla SAM3, we observe that its performance degrades substantially on medical data, with its apparent competitiveness largely relying on strong geometric priors such as ground-truth-derived bounding boxes. These findings motivate full model adaptation beyond prompt engineering alone. By fine-tuning SAM3's model parameters on 33 datasets spanning 10 medical imaging modalities, Medical SAM3 acquires robust domain-specific representations while preserving prompt-driven flexibility. Extensive experiments across organs, imaging modalities, and dimensionalities demonstrate consistent and significant performance gains, particularly in challenging scenarios characterized by semantic ambiguity, complex morphology, and long-range 3D context. Our results establish Medical SAM3 as a universal, text-guided segmentation foundation model for medical imaging and highlight the importance of holistic model adaptation for achieving robust prompt-driven segmentation under severe domain shift. Code and model will be made available at https://github.com/AIM-Research-Lab/Medical-SAM3.
ICM-Fusion: In-Context Meta-Optimized LoRA Fusion for Multi-Task Adaptation
Aug 06, 2025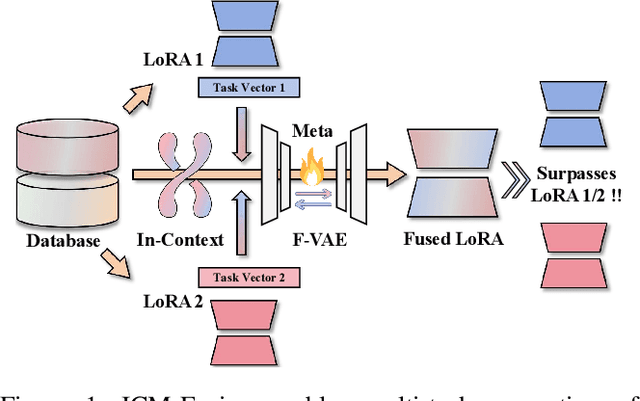
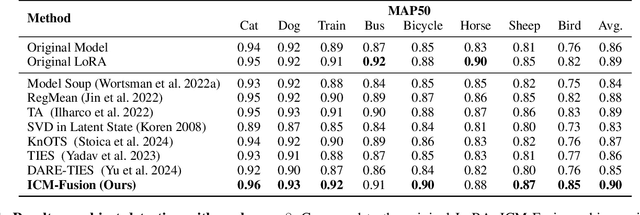
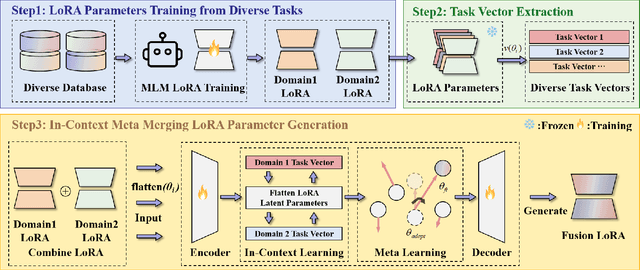
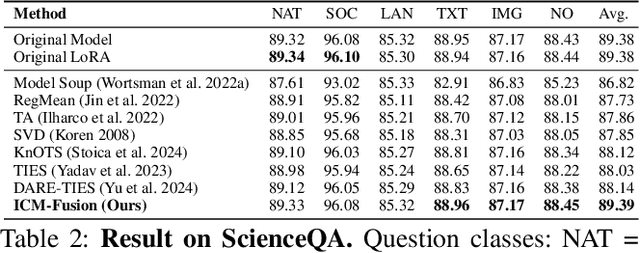
Enabling multi-task adaptation in pre-trained Low-Rank Adaptation (LoRA) models is crucial for enhancing their generalization capabilities. Most existing pre-trained LoRA fusion methods decompose weight matrices, sharing similar parameters while merging divergent ones. However, this paradigm inevitably induces inter-weight conflicts and leads to catastrophic domain forgetting. While incremental learning enables adaptation to multiple tasks, it struggles to achieve generalization in few-shot scenarios. Consequently, when the weight data follows a long-tailed distribution, it can lead to forgetting in the fused weights. To address this issue, we propose In-Context Meta LoRA Fusion (ICM-Fusion), a novel framework that synergizes meta-learning with in-context adaptation. The key innovation lies in our task vector arithmetic, which dynamically balances conflicting optimization directions across domains through learned manifold projections. ICM-Fusion obtains the optimal task vector orientation for the fused model in the latent space by adjusting the orientation of the task vectors. Subsequently, the fused LoRA is reconstructed by a self-designed Fusion VAE (F-VAE) to realize multi-task LoRA generation. We have conducted extensive experiments on visual and linguistic tasks, and the experimental results demonstrate that ICM-Fusion can be adapted to a wide range of architectural models and applied to various tasks. Compared to the current pre-trained LoRA fusion method, ICM-Fusion fused LoRA can significantly reduce the multi-tasking loss and can even achieve task enhancement in few-shot scenarios.
Unifying Appearance Codes and Bilateral Grids for Driving Scene Gaussian Splatting
Jun 06, 2025Neural rendering techniques, including NeRF and Gaussian Splatting (GS), rely on photometric consistency to produce high-quality reconstructions. However, in real-world scenarios, it is challenging to guarantee perfect photometric consistency in acquired images. Appearance codes have been widely used to address this issue, but their modeling capability is limited, as a single code is applied to the entire image. Recently, the bilateral grid was introduced to perform pixel-wise color mapping, but it is difficult to optimize and constrain effectively. In this paper, we propose a novel multi-scale bilateral grid that unifies appearance codes and bilateral grids. We demonstrate that this approach significantly improves geometric accuracy in dynamic, decoupled autonomous driving scene reconstruction, outperforming both appearance codes and bilateral grids. This is crucial for autonomous driving, where accurate geometry is important for obstacle avoidance and control. Our method shows strong results across four datasets: Waymo, NuScenes, Argoverse, and PandaSet. We further demonstrate that the improvement in geometry is driven by the multi-scale bilateral grid, which effectively reduces floaters caused by photometric inconsistency.
EventVAD: Training-Free Event-Aware Video Anomaly Detection
Apr 17, 2025Video Anomaly Detection~(VAD) focuses on identifying anomalies within videos. Supervised methods require an amount of in-domain training data and often struggle to generalize to unseen anomalies. In contrast, training-free methods leverage the intrinsic world knowledge of large language models (LLMs) to detect anomalies but face challenges in localizing fine-grained visual transitions and diverse events. Therefore, we propose EventVAD, an event-aware video anomaly detection framework that combines tailored dynamic graph architectures and multimodal LLMs through temporal-event reasoning. Specifically, EventVAD first employs dynamic spatiotemporal graph modeling with time-decay constraints to capture event-aware video features. Then, it performs adaptive noise filtering and uses signal ratio thresholding to detect event boundaries via unsupervised statistical features. The statistical boundary detection module reduces the complexity of processing long videos for MLLMs and improves their temporal reasoning through event consistency. Finally, it utilizes a hierarchical prompting strategy to guide MLLMs in performing reasoning before determining final decisions. We conducted extensive experiments on the UCF-Crime and XD-Violence datasets. The results demonstrate that EventVAD with a 7B MLLM achieves state-of-the-art (SOTA) in training-free settings, outperforming strong baselines that use 7B or larger MLLMs.
GM-MoE: Low-Light Enhancement with Gated-Mechanism Mixture-of-Experts
Mar 10, 2025Low-light enhancement has wide applications in autonomous driving, 3D reconstruction, remote sensing, surveillance, and so on, which can significantly improve information utilization. However, most existing methods lack generalization and are limited to specific tasks such as image recovery. To address these issues, we propose \textbf{Gated-Mechanism Mixture-of-Experts (GM-MoE)}, the first framework to introduce a mixture-of-experts network for low-light image enhancement. GM-MoE comprises a dynamic gated weight conditioning network and three sub-expert networks, each specializing in a distinct enhancement task. Combining a self-designed gated mechanism that dynamically adjusts the weights of the sub-expert networks for different data domains. Additionally, we integrate local and global feature fusion within sub-expert networks to enhance image quality by capturing multi-scale features. Experimental results demonstrate that the GM-MoE achieves superior generalization with respect to 25 compared approaches, reaching state-of-the-art performance on PSNR on 5 benchmarks and SSIM on 4 benchmarks, respectively.
TR-DQ: Time-Rotation Diffusion Quantization
Mar 09, 2025Diffusion models have been widely adopted in image and video generation. However, their complex network architecture leads to high inference overhead for its generation process. Existing diffusion quantization methods primarily focus on the quantization of the model structure while ignoring the impact of time-steps variation during sampling. At the same time, most current approaches fail to account for significant activations that cannot be eliminated, resulting in substantial performance degradation after quantization. To address these issues, we propose Time-Rotation Diffusion Quantization (TR-DQ), a novel quantization method incorporating time-step and rotation-based optimization. TR-DQ first divides the sampling process based on time-steps and applies a rotation matrix to smooth activations and weights dynamically. For different time-steps, a dedicated hyperparameter is introduced for adaptive timing modeling, which enables dynamic quantization across different time steps. Additionally, we also explore the compression potential of Classifier-Free Guidance (CFG-wise) to establish a foundation for subsequent work. TR-DQ achieves state-of-the-art (SOTA) performance on image generation and video generation tasks and a 1.38-1.89x speedup and 1.97-2.58x memory reduction in inference compared to existing quantization methods.
In-Context Meta LoRA Generation
Jan 30, 2025



Low-rank Adaptation (LoRA) has demonstrated remarkable capabilities for task specific fine-tuning. However, in scenarios that involve multiple tasks, training a separate LoRA model for each one results in considerable inefficiency in terms of storage and inference. Moreover, existing parameter generation methods fail to capture the correlations among these tasks, making multi-task LoRA parameter generation challenging. To address these limitations, we propose In-Context Meta LoRA (ICM-LoRA), a novel approach that efficiently achieves task-specific customization of large language models (LLMs). Specifically, we use training data from all tasks to train a tailored generator, Conditional Variational Autoencoder (CVAE). CVAE takes task descriptions as inputs and produces task-aware LoRA weights as outputs. These LoRA weights are then merged with LLMs to create task-specialized models without the need for additional fine-tuning. Furthermore, we utilize in-context meta-learning for knowledge enhancement and task mapping, to capture the relationship between tasks and parameter distributions. As a result, our method achieves more accurate LoRA parameter generation for diverse tasks using CVAE. ICM-LoRA enables more accurate LoRA parameter reconstruction than current parameter reconstruction methods and is useful for implementing task-specific enhancements of LoRA parameters. At the same time, our method occupies 283MB, only 1\% storage compared with the original LoRA.
3DSceneEditor: Controllable 3D Scene Editing with Gaussian Splatting
Dec 02, 2024
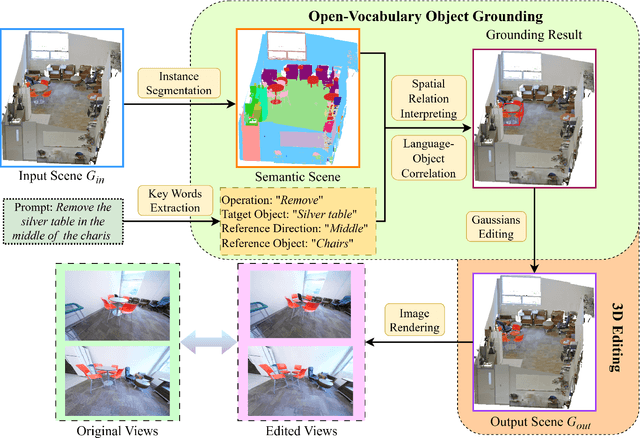


The creation of 3D scenes has traditionally been both labor-intensive and costly, requiring designers to meticulously configure 3D assets and environments. Recent advancements in generative AI, including text-to-3D and image-to-3D methods, have dramatically reduced the complexity and cost of this process. However, current techniques for editing complex 3D scenes continue to rely on generally interactive multi-step, 2D-to-3D projection methods and diffusion-based techniques, which often lack precision in control and hamper real-time performance. In this work, we propose 3DSceneEditor, a fully 3D-based paradigm for real-time, precise editing of intricate 3D scenes using Gaussian Splatting. Unlike conventional methods, 3DSceneEditor operates through a streamlined 3D pipeline, enabling direct manipulation of Gaussians for efficient, high-quality edits based on input prompts.The proposed framework (i) integrates a pre-trained instance segmentation model for semantic labeling; (ii) employs a zero-shot grounding approach with CLIP to align target objects with user prompts; and (iii) applies scene modifications, such as object addition, repositioning, recoloring, replacing, and deletion directly on Gaussians. Extensive experimental results show that 3DSceneEditor achieves superior editing precision and speed with respect to current SOTA 3D scene editing approaches, establishing a new benchmark for efficient and interactive 3D scene customization.
GWQ: Gradient-Aware Weight Quantization for Large Language Models
Oct 30, 2024
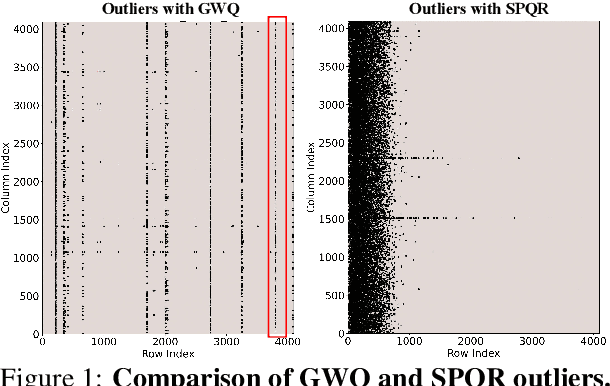
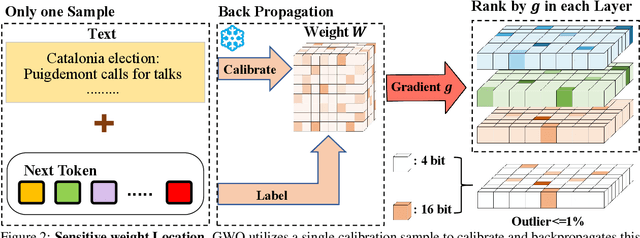
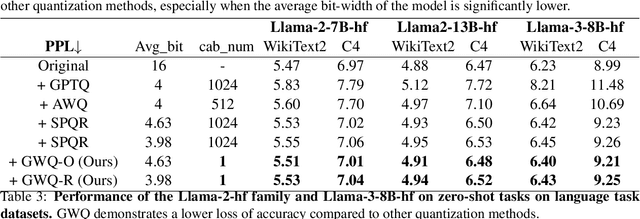
Large language models (LLMs) show impressive performance in solving complex languagetasks. However, its large number of parameterspresent significant challenges for the deployment and application of the model on edge devices. Compressing large language models to low bits can enable them to run on resource-constrained devices, often leading to performance degradation. To address this problem, we propose gradient-aware weight quantization (GWQ), the first quantization approach for low-bit weight quantization that leverages gradients to localize outliers, requiring only a minimal amount of calibration data for outlier detection. GWQ retains the weights corresponding to the top 1% outliers preferentially at FP16 precision, while the remaining non-outlier weights are stored in a low-bit format. GWQ found experimentally that utilizing the sensitive weights in the gradient localization model is more scientific compared to utilizing the sensitive weights in the Hessian matrix localization model. Compared to current quantization methods, GWQ can be applied to multiple language models and achieves lower PPL on the WikiText2 and C4 dataset. In the zero-shot task, GWQ quantized models have higher accuracy compared to other quantization methods.GWQ is also suitable for multimodal model quantization, and the quantized Qwen-VL family model is more accurate than other methods. zero-shot target detection task dataset RefCOCO outperforms the current stat-of-the-arts method SPQR. GWQ achieves 1.2x inference speedup in comparison to the original model, and effectively reduces the inference memory.
RenderWorld: World Model with Self-Supervised 3D Label
Sep 17, 2024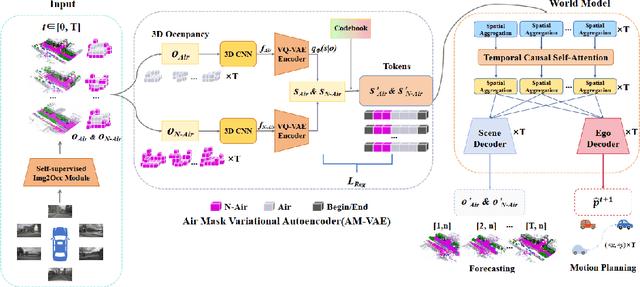
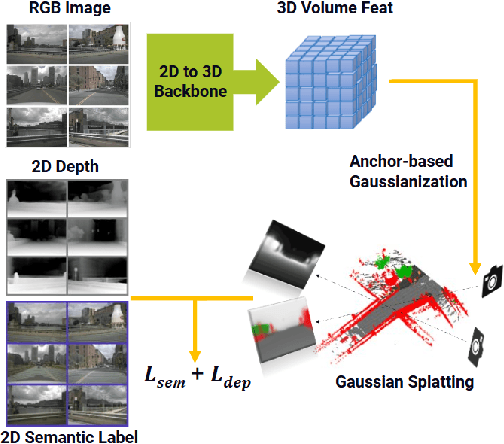
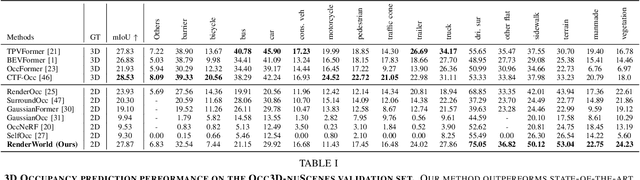

End-to-end autonomous driving with vision-only is not only more cost-effective compared to LiDAR-vision fusion but also more reliable than traditional methods. To achieve a economical and robust purely visual autonomous driving system, we propose RenderWorld, a vision-only end-to-end autonomous driving framework, which generates 3D occupancy labels using a self-supervised gaussian-based Img2Occ Module, then encodes the labels by AM-VAE, and uses world model for forecasting and planning. RenderWorld employs Gaussian Splatting to represent 3D scenes and render 2D images greatly improves segmentation accuracy and reduces GPU memory consumption compared with NeRF-based methods. By applying AM-VAE to encode air and non-air separately, RenderWorld achieves more fine-grained scene element representation, leading to state-of-the-art performance in both 4D occupancy forecasting and motion planning from autoregressive world model.