 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Evolutionary Optimization of Chance-Constrained Multiple-Choice Knapsack Problems with Implicit Probability Distributions
Mar 09, 2026The multiple-choice knapsack problem (MCKP) is a classic combinatorial optimization with wide practical applications. This paper investigates a significant yet underexplored extension of MCKP: the multi-objective chance-constrained MCKP (MO-CCMCKP) under implicit probability distributions. The goal of the problem is to simultaneously minimize the total cost and maximize the confidence level of satisfying the capacity constraint, capturing essential trade-offs in domains like 5G network configuration. To address the computational challenge of evaluating chance constraints under implicit distributions, we first propose an order-preserving efficient resource allocation Monte Carlo (OPERA-MC) method. This approach adaptively allocates sampling resources to preserve dominance relationships while reducing evaluation time significantly. Further, we develop NHILS, a hybrid evolutionary algorithm that integrates specialized initialization and local search into NSGA-II to navigate sparse feasible regions. Experiments on synthetic benchmarks and real-world 5G network configuration benchmarks demonstrate that NHILS consistently outperforms several state-of-the-art multi-objective optimizers in convergence, diversity, and feasibility. The benchmark instances and source code will be made publicly available to facilitate research in this area.
Personalized Treatment Outcome Prediction from Scarce Data via Dual-Channel Knowledge Distillation and Adaptive Fusion
Oct 30, 2025Personalized treatment outcome prediction based on trial data for small-sample and rare patient groups is critical in precision medicine. However, the costly trial data limit the prediction performance. To address this issue, we propose a cross-fidelity knowledge distillation and adaptive fusion network (CFKD-AFN), which leverages abundant but low-fidelity simulation data to enhance predictions on scarce but high-fidelity trial data. CFKD-AFN incorporates a dual-channel knowledge distillation module to extract complementary knowledge from the low-fidelity model, along with an attention-guided fusion module to dynamically integrate multi-source information. Experiments on treatment outcome prediction for the chronic obstructive pulmonary disease demonstrates significant improvements of CFKD-AFN over state-of-the-art methods in prediction accuracy, ranging from 6.67\% to 74.55\%, and strong robustness to varying high-fidelity dataset sizes. Furthermore, we extend CFKD-AFN to an interpretable variant, enabling the exploration of latent medical semantics to support clinical decision-making.
Memetic Search for Green Vehicle Routing Problem with Private Capacitated Refueling Stations
Apr 06, 2025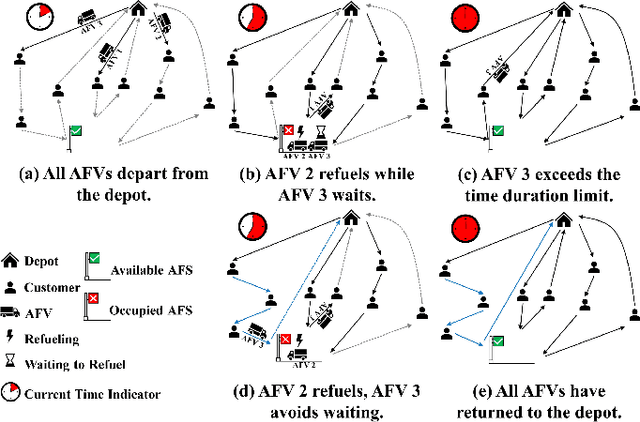
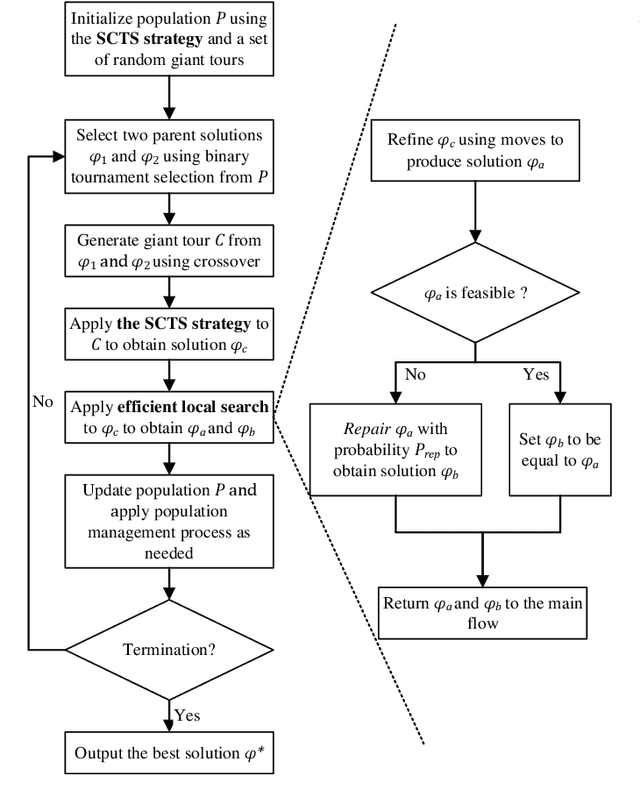
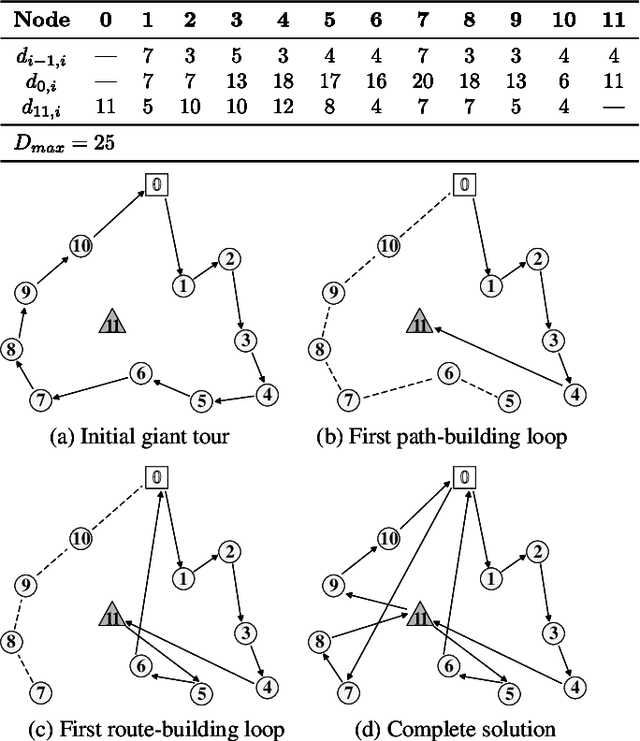
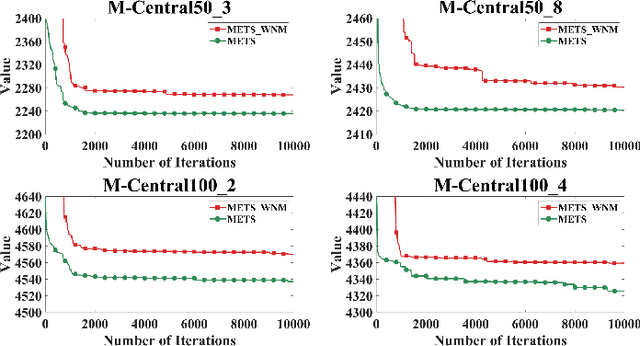
The green vehicle routing problem with private capacitated alternative fuel stations (GVRP-PCAFS) extends the traditional green vehicle routing problem by considering refueling stations limited capacity, where a limited number of vehicles can refuel simultaneously with additional vehicles must wait. This feature presents new challenges for route planning, as waiting times at stations must be managed while keeping route durations within limits and reducing total travel distance. This article presents METS, a novel memetic algorithm (MA) with separate constraint-based tour segmentation (SCTS) and efficient local search (ELS) for solving GVRP-PCAFS. METS combines global and local search effectively through three novelties. For global search, the SCTS strategy splits giant tours to generate diverse solutions, and the search process is guided by a comprehensive fitness evaluation function to dynamically control feasibility and diversity to produce solutions that are both diverse and near-feasible. For local search, ELS incorporates tailored move operators with constant-time move evaluation mechanisms, enabling efficient exploration of large solution neighborhoods. Experimental results demonstrate that METS discovers 31 new best-known solutions out of 40 instances in existing benchmark sets, achieving substantial improvements over current state-of-the-art methods. Additionally, a new large-scale benchmark set based on real-world logistics data is introduced to facilitate future research.
In-Context Meta LoRA Generation
Jan 30, 2025



Low-rank Adaptation (LoRA) has demonstrated remarkable capabilities for task specific fine-tuning. However, in scenarios that involve multiple tasks, training a separate LoRA model for each one results in considerable inefficiency in terms of storage and inference. Moreover, existing parameter generation methods fail to capture the correlations among these tasks, making multi-task LoRA parameter generation challenging. To address these limitations, we propose In-Context Meta LoRA (ICM-LoRA), a novel approach that efficiently achieves task-specific customization of large language models (LLMs). Specifically, we use training data from all tasks to train a tailored generator, Conditional Variational Autoencoder (CVAE). CVAE takes task descriptions as inputs and produces task-aware LoRA weights as outputs. These LoRA weights are then merged with LLMs to create task-specialized models without the need for additional fine-tuning. Furthermore, we utilize in-context meta-learning for knowledge enhancement and task mapping, to capture the relationship between tasks and parameter distributions. As a result, our method achieves more accurate LoRA parameter generation for diverse tasks using CVAE. ICM-LoRA enables more accurate LoRA parameter reconstruction than current parameter reconstruction methods and is useful for implementing task-specific enhancements of LoRA parameters. At the same time, our method occupies 283MB, only 1\% storage compared with the original LoRA.
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Jun 27, 2024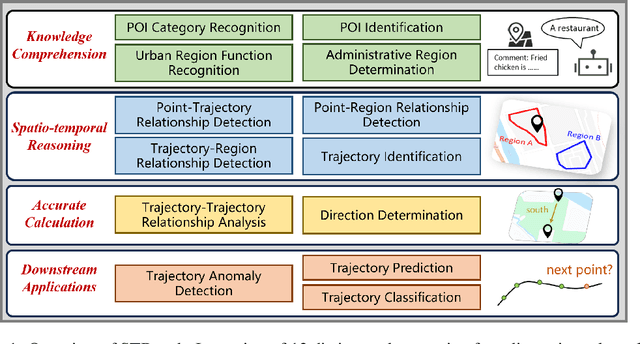

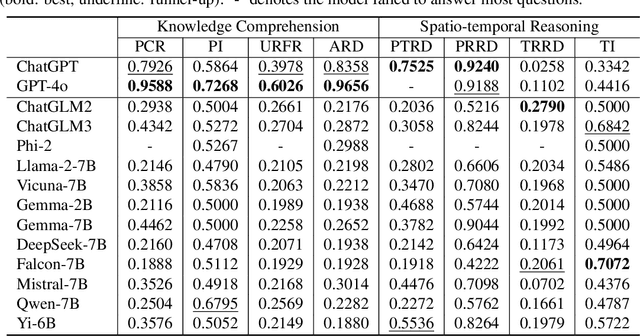
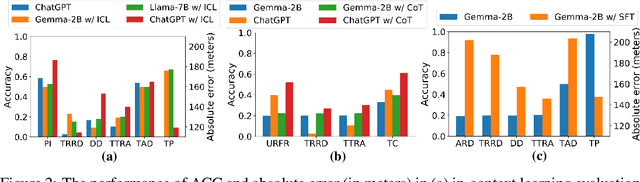
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
Dual-domain Collaborative Denoising for Social Recommendation
May 08, 2024

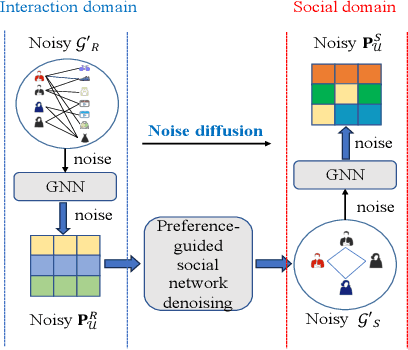
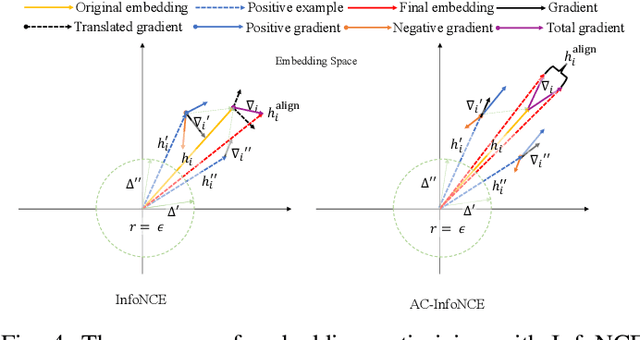
Social recommendation leverages social network to complement user-item interaction data for recommendation task, aiming to mitigate the data sparsity issue in recommender systems. However, existing social recommendation methods encounter the following challenge: both social network and interaction data contain substaintial noise, and the propagation of such noise through Graph Neural Networks (GNNs) not only fails to enhance recommendation performance but may also interfere with the model's normal training. Despite the importance of denoising for social network and interaction data, only a limited number of studies have considered the denoising for social network and all of them overlook that for interaction data, hindering the denoising effect and recommendation performance. Based on this, we propose a novel model called Dual-domain Collaborative Denoising for Social Recommendation ($\textbf{DCDSR}$). DCDSR comprises two primary modules: the structure-level collaborative denoising module and the embedding-space collaborative denoising module. In the structure-level collaborative denoising module, information from interaction domain is first employed to guide social network denoising. Subsequently, the denoised social network is used to supervise the denoising for interaction data. The embedding-space collaborative denoising module devotes to resisting the noise cross-domain diffusion problem through contrastive learning with dual-domain embedding collaborative perturbation. Additionally, a novel contrastive learning strategy, named Anchor-InfoNCE, is introduced to better harness the denoising capability of contrastive learning. Evaluating our model on three real-world datasets verifies that DCDSR has a considerable denoising effect, thus outperforms the state-of-the-art social recommendation methods.
Neural Influence Estimator: Towards Real-time Solutions to Influence Blocking Maximization
Aug 27, 2023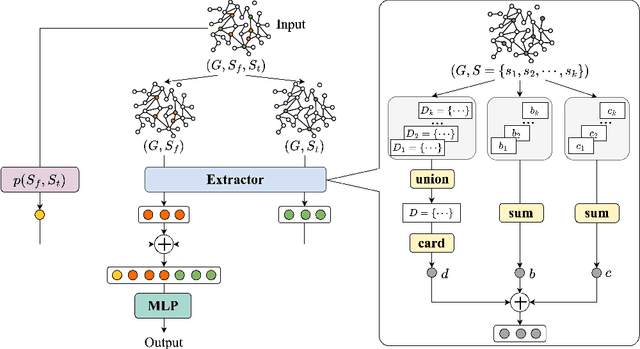
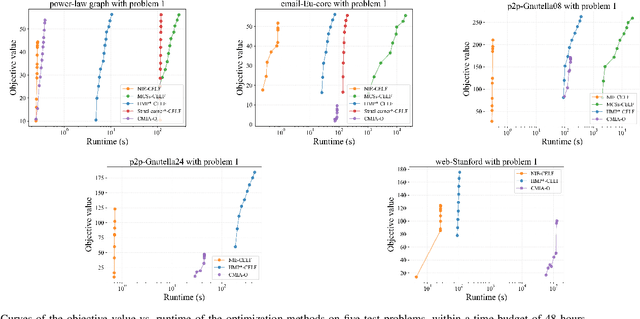
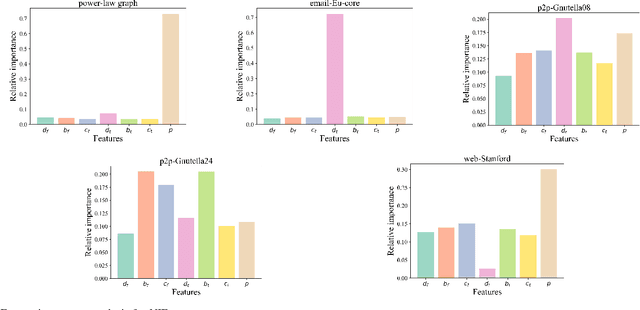
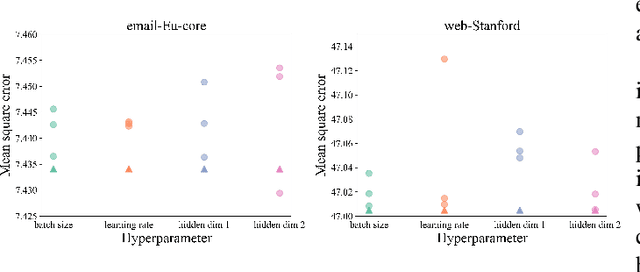
Real-time solutions to the influence blocking maximization (IBM) problems are crucial for promptly containing the spread of misinformation. However, achieving this goal is non-trivial, mainly because assessing the blocked influence of an IBM problem solution typically requires plenty of expensive Monte Carlo simulations (MCSs). Although several approaches have been proposed to enhance efficiency, they still fail to achieve real-time solutions to IBM problems of practical scales. This work presents a novel approach that enables solving IBM problems with hundreds of thousands of nodes and edges in seconds. The key idea is to construct a fast-to-evaluate surrogate model, called neural influence estimator (NIE), as a substitute for the time-intensive MCSs. To this end, a learning problem is formulated to build the NIE that takes the false-and-true information instance as input, extracts features describing the topology and inter-relationship between two seed sets, and predicts the blocked influence. A well-trained NIE can generalize across different IBM problems defined on a social network, and can be readily combined with existing IBM optimization algorithms such as the greedy algorithm. The experiments on 25 IBM problems with up to millions of edges show that the NIE-based optimization method can be up to four orders of magnitude faster than MCSs-based optimization method to achieve the same solution quality. Moreover, given a real-time constraint of one minute, the NIE-based method can solve IBM problems with up to hundreds of thousands of nodes, which is at least one order of magnitude larger than what can be solved by existing methods.
A New Knowledge Gradient-based Method for Constrained Bayesian Optimization
Jan 20, 2021Black-box problems are common in real life like structural design, drug experiments, and machine learning. When optimizing black-box systems, decision-makers always consider multiple performances and give the final decision by comprehensive evaluations. Motivated by such practical needs, we focus on constrained black-box problems where the objective and constraints lack known special structure, and evaluations are expensive and even with noise. We develop a novel constrained Bayesian optimization approach based on the knowledge gradient method ($c-\rm{KG}$). A new acquisition function is proposed to determine the next batch of samples considering optimality and feasibility. An unbiased estimator of the gradient of the new acquisition function is derived to implement the $c-\rm{KG}$ approach.
Grasping Detection Network with Uncertainty Estimation for Confidence-Driven Semi-Supervised Domain Adaptation
Aug 20, 2020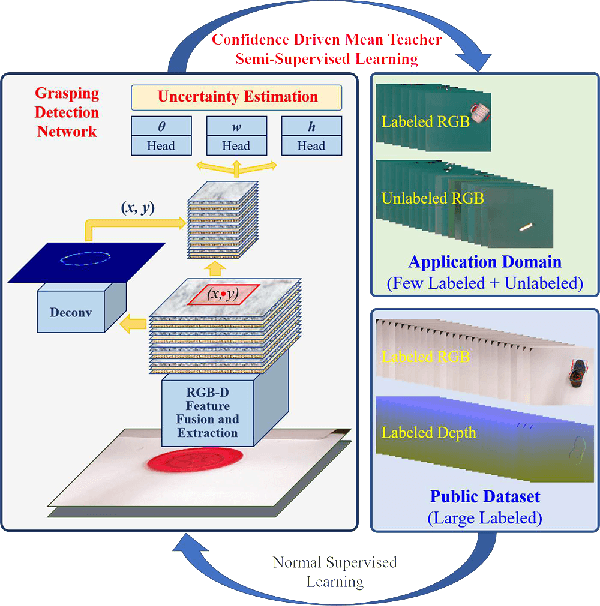
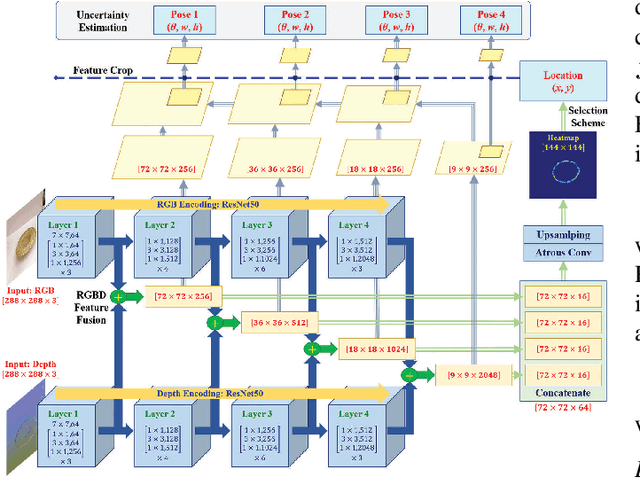
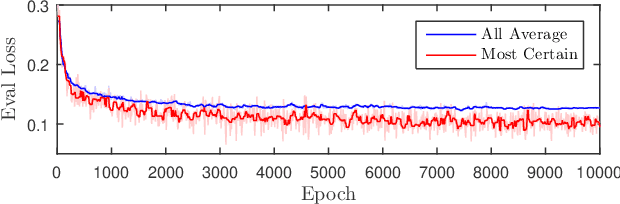

Data-efficient domain adaptation with only a few labelled data is desired for many robotic applications, e.g., in grasping detection, the inference skill learned from a grasping dataset is not universal enough to directly apply on various other daily/industrial applications. This paper presents an approach enabling the easy domain adaptation through a novel grasping detection network with confidence-driven semi-supervised learning, where these two components deeply interact with each other. The proposed grasping detection network specially provides a prediction uncertainty estimation mechanism by leveraging on Feature Pyramid Network (FPN), and the mean-teacher semi-supervised learning utilizes such uncertainty information to emphasizing the consistency loss only for those unlabelled data with high confidence, which we referred it as the confidence-driven mean teacher. This approach largely prevents the student model to learn the incorrect/harmful information from the consistency loss, which speeds up the learning progress and improves the model accuracy. Our results show that the proposed network can achieve high success rate on the Cornell grasping dataset, and for domain adaptation with very limited data, the confidence-driven mean teacher outperforms the original mean teacher and direct training by more than 10% in evaluation loss especially for avoiding the overfitting and model diverging.
A biological plausible audio-visual integration model for continual lifelong learning
Jul 17, 2020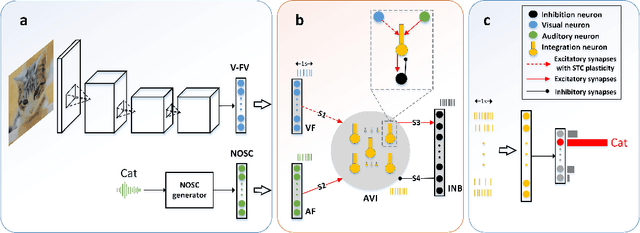

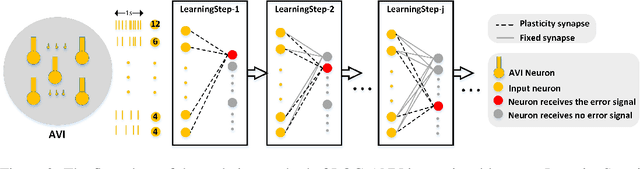

The problem of catastrophic forgetting can be traced back to the 1980s, but it has not been completely solved. Since human brains are good at continual lifelong learning, brain-inspired methods may provide solutions to this problem. The end result of learning different objects in different categories is the formation of concepts in the brain. Experiments showed that concepts are likely encoded by concept cells in the medial temporal lobe (MTL) of the human brain. Furthermore, concept cells encode concepts sparsely and are responsive to multi-modal stimuli. However, it is unknown how concepts are formed in the MTL. Here we assume that the integration of audio and visual perceptual information in the MTL during learning is a crucial step to form concepts and make continual learning possible, and we propose a biological plausible audio-visual integration model (AVIM), which is a spiking neural network with multi-compartmental neuron model and a calcium based synaptic tagging and capture plasticity model, as a possible mechanism of concept formation. We then build such a model and run on different datasets to test its ability of continual learning. Our simulation results show that the AVIM not only achieves state-of-the-art performance compared with other advanced methods but also the output of AVIM for each concept has stable representations during the continual learning process. These results support our assumption that concept formation is essential for continuous lifelong learning, and suggest the AVIM we propose here is a possible mechanism of concept formation, and hence is a brain-like solution to the problem of catastrophic forgetting.