 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-FM: Multimodal LLMs for Anomaly Detection via Multi-Stage Reasoning and Fine-Grained Reward Optimization
Aug 06, 2025



While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities across diverse domains, their application to specialized anomaly detection (AD) remains constrained by domain adaptation challenges. Existing Group Relative Policy Optimization (GRPO) based approaches suffer from two critical limitations: inadequate training data utilization when models produce uniform responses, and insufficient supervision over reasoning processes that encourage immediate binary decisions without deliberative analysis. We propose a comprehensive framework addressing these limitations through two synergistic innovations. First, we introduce a multi-stage deliberative reasoning process that guides models from region identification to focused examination, generating diverse response patterns essential for GRPO optimization while enabling structured supervision over analytical workflows. Second, we develop a fine-grained reward mechanism incorporating classification accuracy and localization supervision, transforming binary feedback into continuous signals that distinguish genuine analytical insight from spurious correctness. Comprehensive evaluation across multiple industrial datasets demonstrates substantial performance improvements in adapting general vision-language models to specialized anomaly detection. Our method achieves superior accuracy with efficient adaptation of existing annotations, effectively bridging the gap between general-purpose MLLM capabilities and the fine-grained visual discrimination required for detecting subtle manufacturing defects and structural irregularities.
Incremental Few-Shot Learning via Implanting and Compressing
Apr 07, 2022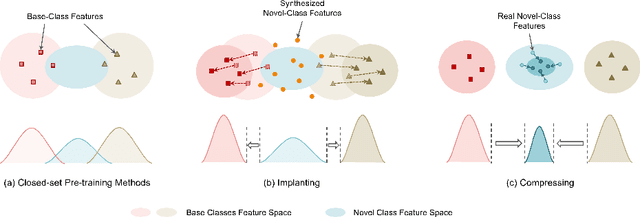
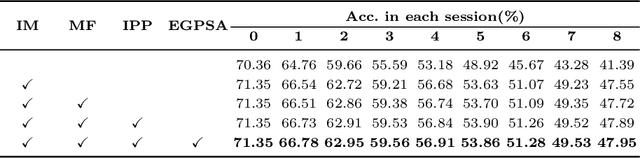
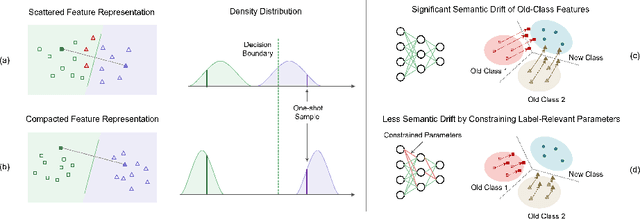
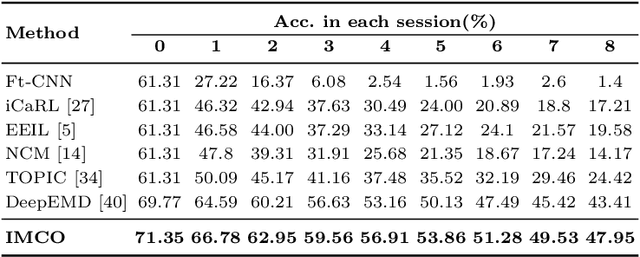
This work focuses on tackling the challenging but realistic visual task of Incremental Few-Shot Learning (IFSL), which requires a model to continually learn novel classes from only a few examples while not forgetting the base classes on which it was pre-trained. Our study reveals that the challenges of IFSL lie in both inter-class separation and novel-class representation. Dur to intra-class variation, a novel class may implicitly leverage the knowledge from multiple base classes to construct its feature representation. Hence, simply reusing the pre-trained embedding space could lead to a scattered feature distribution and result in category confusion. To address such issues, we propose a two-step learning strategy referred to as \textbf{Im}planting and \textbf{Co}mpressing (\textbf{IMCO}), which optimizes both feature space partition and novel class reconstruction in a systematic manner. Specifically, in the \textbf{Implanting} step, we propose to mimic the data distribution of novel classes with the assistance of data-abundant base set, so that a model could learn semantically-rich features that are beneficial for discriminating between the base and other unseen classes. In the \textbf{Compressing} step, we adapt the feature extractor to precisely represent each novel class for enhancing intra-class compactness, together with a regularized parameter updating rule for preventing aggressive model updating. Finally, we demonstrate that IMCO outperforms competing baselines with a significant margin, both in image classification task and more challenging object detection task.
Towards Generalized and Incremental Few-Shot Object Detection
Sep 23, 2021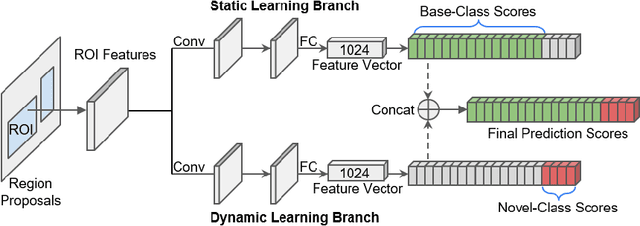
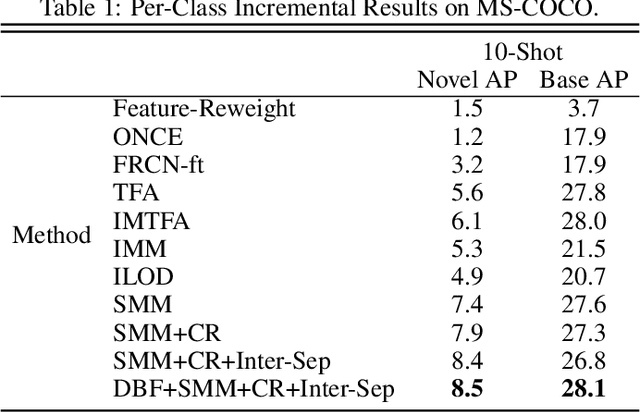
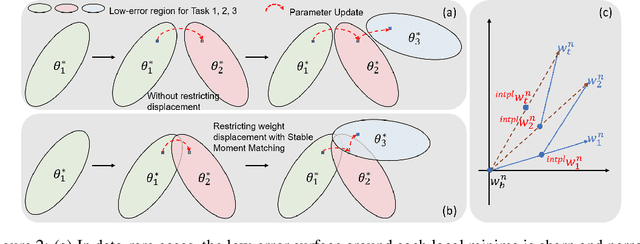
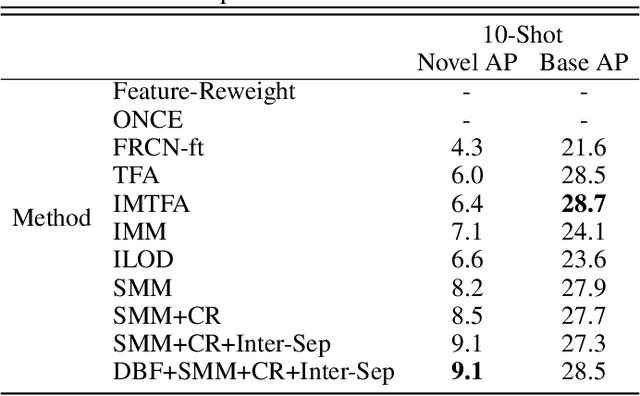
Real-world object detection is highly desired to be equipped with the learning expandability that can enlarge its detection classes incrementally. Moreover, such learning from only few annotated training samples further adds the flexibility for the object detector, which is highly expected in many applications such as autonomous driving, robotics, etc. However, such sequential learning scenario with few-shot training samples generally causes catastrophic forgetting and dramatic overfitting. In this paper, to address the above incremental few-shot learning issues, a novel Incremental Few-Shot Object Detection (iFSOD) method is proposed to enable the effective continual learning from few-shot samples. Specifically, a Double-Branch Framework (DBF) is proposed to decouple the feature representation of base and novel (few-shot) class, which facilitates both the old-knowledge retention and new-class adaption simultaneously. Furthermore, a progressive model updating rule is carried out to preserve the long-term memory on old classes effectively when adapt to sequential new classes. Moreover, an inter-task class separation loss is proposed to extend the decision region of new-coming classes for better feature discrimination. We conduct experiments on both Pascal VOC and MS-COCO, which demonstrate that our method can effectively solve the problem of incremental few-shot detection and significantly improve the detection accuracy on both base and novel classes.
Grasping Detection Network with Uncertainty Estimation for Confidence-Driven Semi-Supervised Domain Adaptation
Aug 20, 2020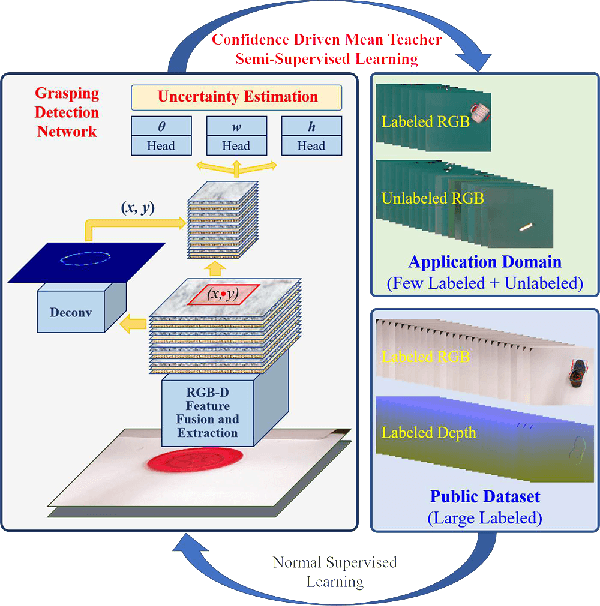
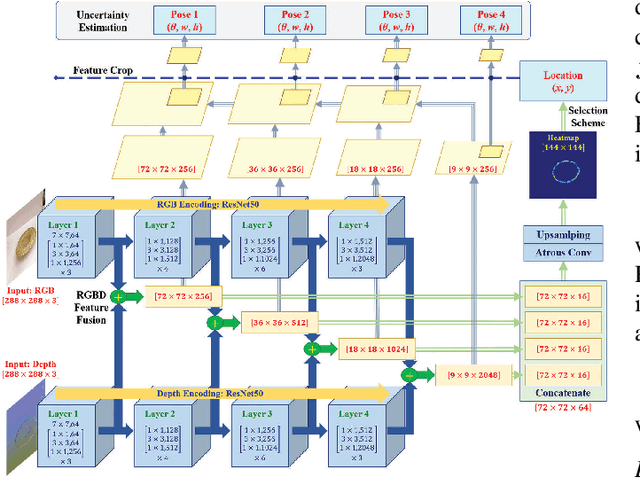
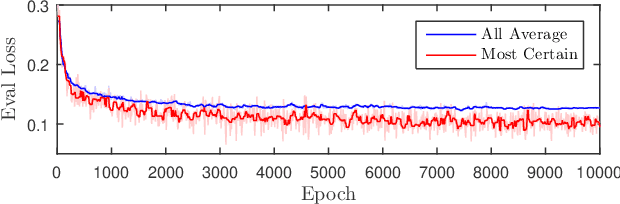

Data-efficient domain adaptation with only a few labelled data is desired for many robotic applications, e.g., in grasping detection, the inference skill learned from a grasping dataset is not universal enough to directly apply on various other daily/industrial applications. This paper presents an approach enabling the easy domain adaptation through a novel grasping detection network with confidence-driven semi-supervised learning, where these two components deeply interact with each other. The proposed grasping detection network specially provides a prediction uncertainty estimation mechanism by leveraging on Feature Pyramid Network (FPN), and the mean-teacher semi-supervised learning utilizes such uncertainty information to emphasizing the consistency loss only for those unlabelled data with high confidence, which we referred it as the confidence-driven mean teacher. This approach largely prevents the student model to learn the incorrect/harmful information from the consistency loss, which speeds up the learning progress and improves the model accuracy. Our results show that the proposed network can achieve high success rate on the Cornell grasping dataset, and for domain adaptation with very limited data, the confidence-driven mean teacher outperforms the original mean teacher and direct training by more than 10% in evaluation loss especially for avoiding the overfitting and model diverging.
Low-shot Object Detection via Classification Refinement
May 06, 2020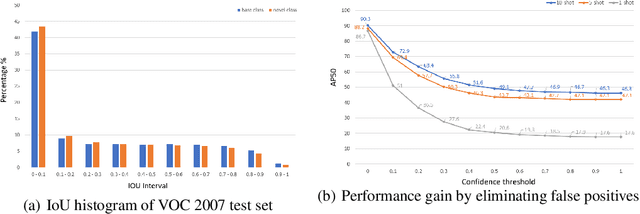
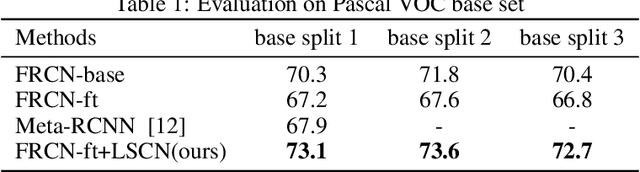
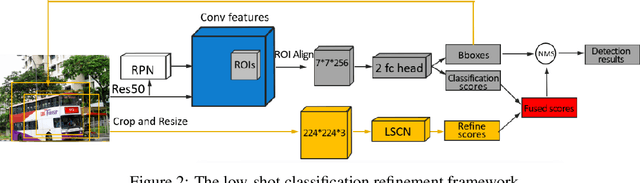
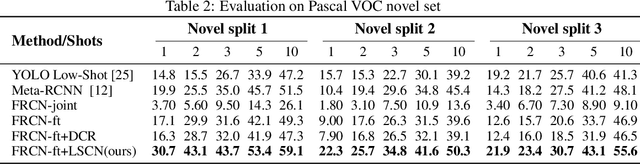
This work aims to address the problem of low-shot object detection, where only a few training samples are available for each category. Regarding the fact that conventional fully supervised approaches usually suffer huge performance drop with rare classes where data is insufficient, our study reveals that there exists more serious misalignment between classification confidence and localization accuracy on rarely labeled categories, and the prone to overfitting class-specific parameters is the crucial cause of this issue. In this paper, we propose a novel low-shot classification correction network (LSCN) which can be adopted into any anchor-based detector to directly enhance the detection accuracy on data-rare categories, without sacrificing the performance on base categories. Specially, we sample false positive proposals from a base detector to train a separate classification correction network. During inference, the well-trained correction network removes false positives from the base detector. The proposed correction network is data-efficient yet highly effective with four carefully designed components, which are Unified recognition, Global receptive field, Inter-class separation, and Confidence calibration. Experiments show our proposed method can bring significant performance gains to rarely labeled categories and outperforms previous work on COCO and PASCAL VOC by a large margin.