 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Action Chunking at Inference-time for Vision-Language-Action Models
Apr 05, 2026In Vision-Language-Action (VLA) models, action chunking (i.e., executing a sequence of actions without intermediate replanning) is a key technique to improve robotic manipulation abilities. However, a large chunk size reduces the model's responsiveness to new information, while a small one increases the likelihood of mode-jumping, jerky behavior resulting from discontinuities between chunks. Therefore, selecting the optimal chunk size is an urgent demand to balance the model's reactivity and consistency. Unfortunately, a dominant trend in current VLA models is an empirical fixed chunk length at inference-time, hindering their superiority and scalability across diverse manipulation tasks. To address this issue, we propose a novel Adaptive Action Chunking (AAC) strategy, which exploits action entropy as the cue to adaptively determine the chunk size based on current predictions. Extensive experiments on a wide range of simulated and real-world robotic manipulation tasks have demonstrated that our approach substantially improves performance over the state-of-the-art alternatives. The videos and source code are publicly available at https://lance-lot.github.io/adaptive-chunking.github.io/.
Robotic Control Optimization Through Kernel Selection in Safe Bayesian Optimization
Nov 12, 2024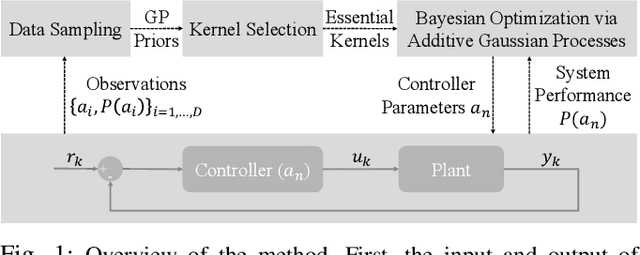
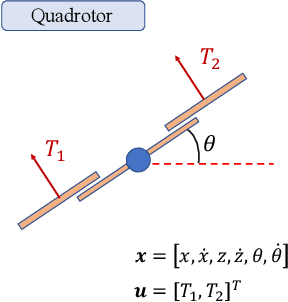
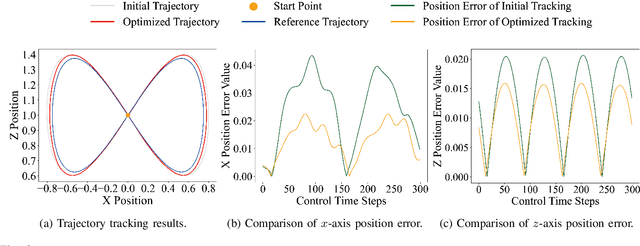
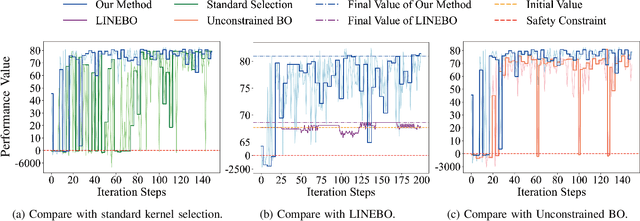
Control system optimization has long been a fundamental challenge in robotics. While recent advancements have led to the development of control algorithms that leverage learning-based approaches, such as SafeOpt, to optimize single feedback controllers, scaling these methods to high-dimensional complex systems with multiple controllers remains an open problem. In this paper, we propose a novel learning-based control optimization method, which enhances the additive Gaussian process-based Safe Bayesian Optimization algorithm to efficiently tackle high-dimensional problems through kernel selection. We use PID controller optimization in drones as a representative example and test the method on Safe Control Gym, a benchmark designed for evaluating safe control techniques. We show that the proposed method provides a more efficient and optimal solution for high-dimensional control optimization problems, demonstrating significant improvements over existing techniques.
Safe Bayesian Optimization for High-Dimensional Control Systems via Additive Gaussian Processes
Aug 29, 2024
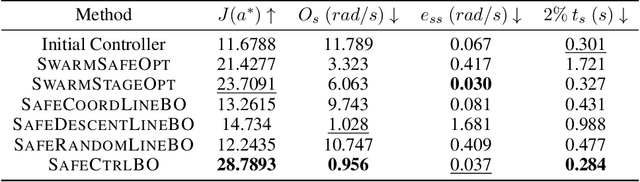
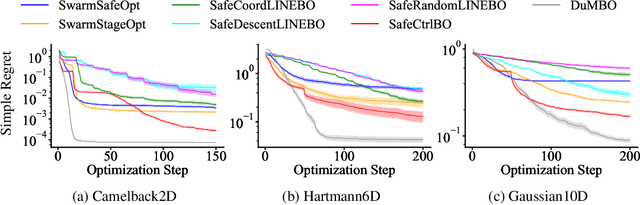

Controller tuning and optimization have been among the most fundamental problems in robotics and mechatronic systems. The traditional methodology is usually model-based, but its performance heavily relies on an accurate mathematical model of the system. In control applications with complex dynamics, obtaining a precise model is often challenging, leading us towards a data-driven approach. While optimizing a single controller has been explored by various researchers, it remains a challenge to obtain the optimal controller parameters safely and efficiently when multiple controllers are involved. In this paper, we propose a high-dimensional safe Bayesian optimization method based on additive Gaussian processes to optimize multiple controllers simultaneously and safely. Additive Gaussian kernels replace the traditional squared-exponential kernels or Mat\'ern kernels, enhancing the efficiency with which Gaussian processes update information on unknown functions. Experimental results on a permanent magnet synchronous motor (PMSM) demonstrate that compared to existing safe Bayesian optimization algorithms, our method can obtain optimal parameters more efficiently while ensuring safety.
Evolving R2 to R2+: Optimal, Delayed Line-of-sight Vector-based Path Planning
May 08, 2024



A vector-based any-angle path planner, R2, is evolved in to R2+ in this paper. By delaying line-of-sight, R2 and R2+ search times are largely unaffected by the distance between the start and goal points, but are exponential in the worst case with respect to the number of collisions during searches. To improve search times, additional discarding conditions in the overlap rule are introduced in R2+. In addition, R2+ resolves interminable chases in R2 by replacing ad hoc points with limited occupied-sector traces from target nodes, and simplifies R2 by employing new abstract structures and ensuring target progression during a trace. R2+ preserves the speed of R2 when paths are expected to detour around few obstacles, and searches significantly faster than R2 in maps with many disjoint obstacles.
R2: Heuristic Bug-Based Any-angle Path-Planning using Lazy Searches
Jun 28, 2022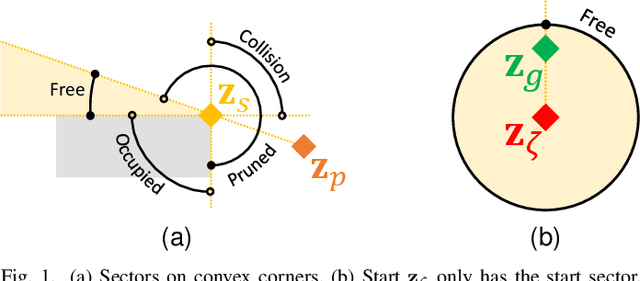
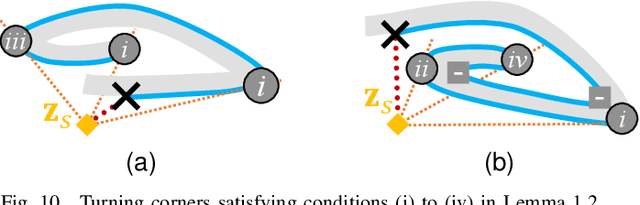
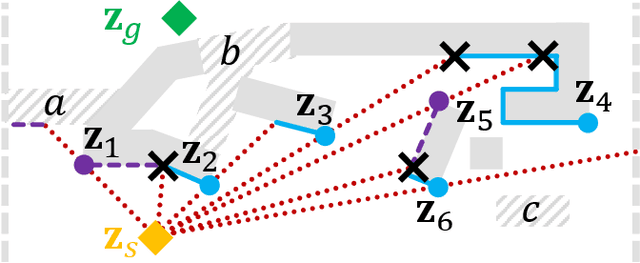
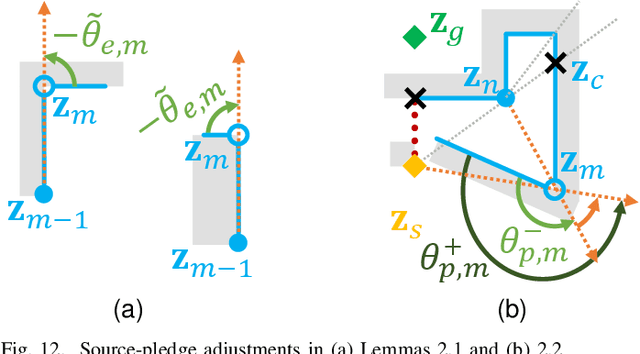
R2 is a novel online any-angle path planner that uses heuristic bug-based or ray casting approaches to find optimal paths in 2D maps with non-convex, polygonal obstacles. R2 is competitive to traditional free-space planners, finding paths quickly if queries have direct line-of-sight. On large sparse maps with few obstacle contours, which are likely to occur in practice, R2 outperforms free-space planners, and can be much faster than state-of-the-art free-space expansion planner Anya. On maps with many contours, Anya performs faster than R2. R2 is built on RayScan, introducing lazy-searches and a source-pledge counter to find successors optimistically on contiguous contours. The novel approach bypasses most successors on jagged contours to reduce expensive line-of-sight checks, therefore requiring no pre-processing to be a competitive online any-angle planner.
Incremental Few-Shot Learning via Implanting and Compressing
Apr 07, 2022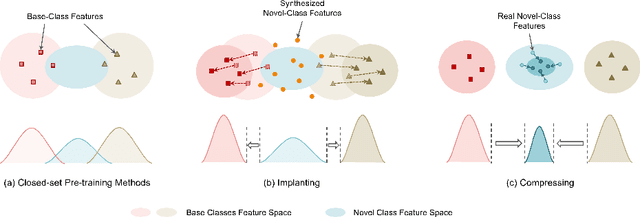
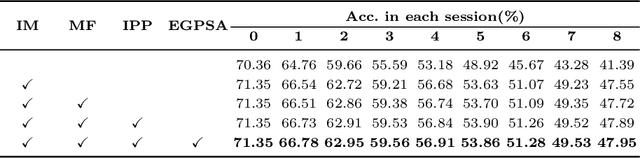
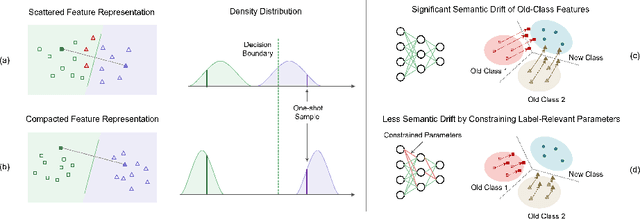
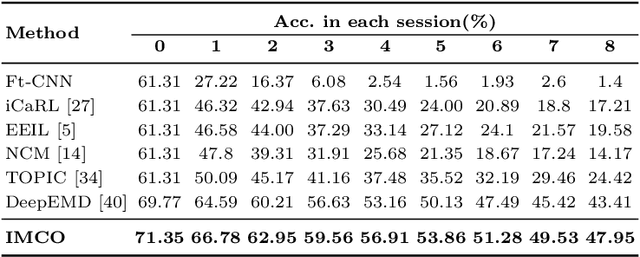
This work focuses on tackling the challenging but realistic visual task of Incremental Few-Shot Learning (IFSL), which requires a model to continually learn novel classes from only a few examples while not forgetting the base classes on which it was pre-trained. Our study reveals that the challenges of IFSL lie in both inter-class separation and novel-class representation. Dur to intra-class variation, a novel class may implicitly leverage the knowledge from multiple base classes to construct its feature representation. Hence, simply reusing the pre-trained embedding space could lead to a scattered feature distribution and result in category confusion. To address such issues, we propose a two-step learning strategy referred to as \textbf{Im}planting and \textbf{Co}mpressing (\textbf{IMCO}), which optimizes both feature space partition and novel class reconstruction in a systematic manner. Specifically, in the \textbf{Implanting} step, we propose to mimic the data distribution of novel classes with the assistance of data-abundant base set, so that a model could learn semantically-rich features that are beneficial for discriminating between the base and other unseen classes. In the \textbf{Compressing} step, we adapt the feature extractor to precisely represent each novel class for enhancing intra-class compactness, together with a regularized parameter updating rule for preventing aggressive model updating. Finally, we demonstrate that IMCO outperforms competing baselines with a significant margin, both in image classification task and more challenging object detection task.
Towards Generalized and Incremental Few-Shot Object Detection
Sep 23, 2021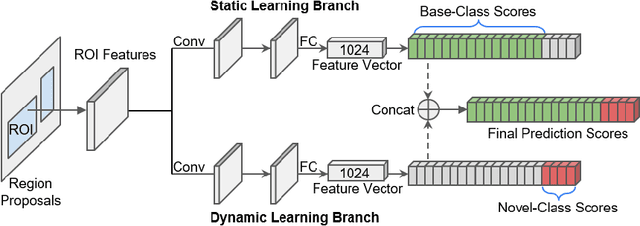
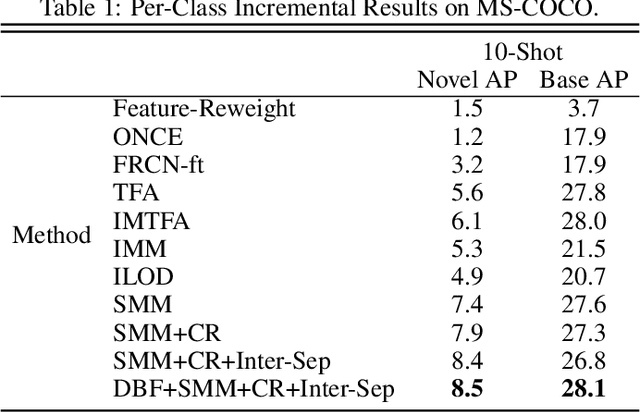
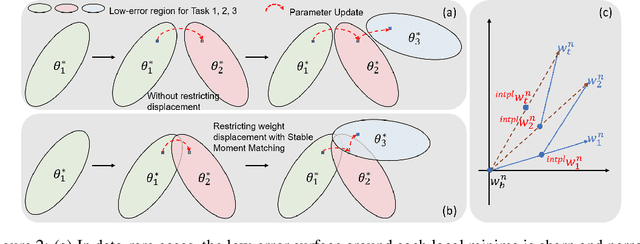
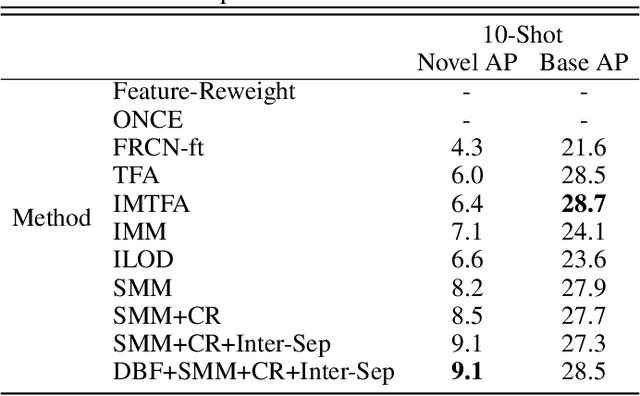
Real-world object detection is highly desired to be equipped with the learning expandability that can enlarge its detection classes incrementally. Moreover, such learning from only few annotated training samples further adds the flexibility for the object detector, which is highly expected in many applications such as autonomous driving, robotics, etc. However, such sequential learning scenario with few-shot training samples generally causes catastrophic forgetting and dramatic overfitting. In this paper, to address the above incremental few-shot learning issues, a novel Incremental Few-Shot Object Detection (iFSOD) method is proposed to enable the effective continual learning from few-shot samples. Specifically, a Double-Branch Framework (DBF) is proposed to decouple the feature representation of base and novel (few-shot) class, which facilitates both the old-knowledge retention and new-class adaption simultaneously. Furthermore, a progressive model updating rule is carried out to preserve the long-term memory on old classes effectively when adapt to sequential new classes. Moreover, an inter-task class separation loss is proposed to extend the decision region of new-coming classes for better feature discrimination. We conduct experiments on both Pascal VOC and MS-COCO, which demonstrate that our method can effectively solve the problem of incremental few-shot detection and significantly improve the detection accuracy on both base and novel classes.
Low-shot Object Detection via Classification Refinement
May 06, 2020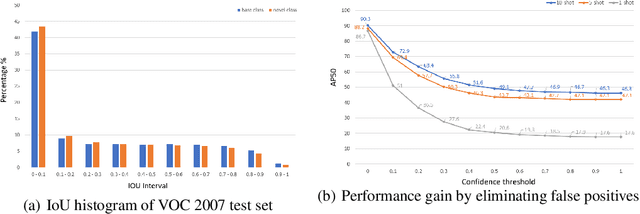
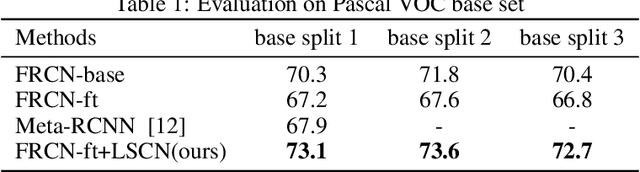
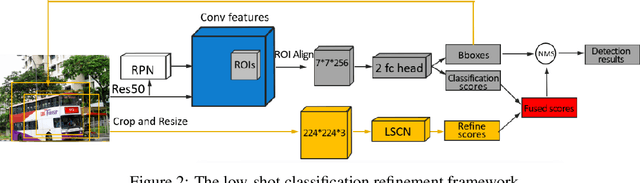
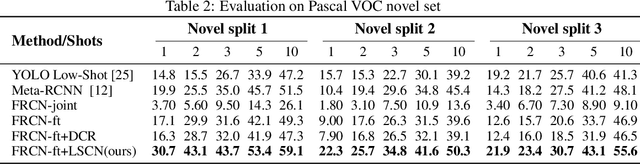
This work aims to address the problem of low-shot object detection, where only a few training samples are available for each category. Regarding the fact that conventional fully supervised approaches usually suffer huge performance drop with rare classes where data is insufficient, our study reveals that there exists more serious misalignment between classification confidence and localization accuracy on rarely labeled categories, and the prone to overfitting class-specific parameters is the crucial cause of this issue. In this paper, we propose a novel low-shot classification correction network (LSCN) which can be adopted into any anchor-based detector to directly enhance the detection accuracy on data-rare categories, without sacrificing the performance on base categories. Specially, we sample false positive proposals from a base detector to train a separate classification correction network. During inference, the well-trained correction network removes false positives from the base detector. The proposed correction network is data-efficient yet highly effective with four carefully designed components, which are Unified recognition, Global receptive field, Inter-class separation, and Confidence calibration. Experiments show our proposed method can bring significant performance gains to rarely labeled categories and outperforms previous work on COCO and PASCAL VOC by a large margin.