 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPSegFZ: Efficient Point Cloud Semantic Segmentation for Few- and Zero-Shot Scenarios with Language Guidance
Nov 12, 2025Recent approaches for few-shot 3D point cloud semantic segmentation typically require a two-stage learning process, i.e., a pre-training stage followed by a few-shot training stage. While effective, these methods face overreliance on pre-training, which hinders model flexibility and adaptability. Some models tried to avoid pre-training yet failed to capture ample information. In addition, current approaches focus on visual information in the support set and neglect or do not fully exploit other useful data, such as textual annotations. This inadequate utilization of support information impairs the performance of the model and restricts its zero-shot ability. To address these limitations, we present a novel pre-training-free network, named Efficient Point Cloud Semantic Segmentation for Few- and Zero-shot scenarios. Our EPSegFZ incorporates three key components. A Prototype-Enhanced Registers Attention (ProERA) module and a Dual Relative Positional Encoding (DRPE)-based cross-attention mechanism for improved feature extraction and accurate query-prototype correspondence construction without pre-training. A Language-Guided Prototype Embedding (LGPE) module that effectively leverages textual information from the support set to improve few-shot performance and enable zero-shot inference. Extensive experiments show that our method outperforms the state-of-the-art method by 5.68% and 3.82% on the S3DIS and ScanNet benchmarks, respectively.
SingRef6D: Monocular Novel Object Pose Estimation with a Single RGB Reference
Sep 26, 2025Recent 6D pose estimation methods demonstrate notable performance but still face some practical limitations. For instance, many of them rely heavily on sensor depth, which may fail with challenging surface conditions, such as transparent or highly reflective materials. In the meantime, RGB-based solutions provide less robust matching performance in low-light and texture-less scenes due to the lack of geometry information. Motivated by these, we propose SingRef6D, a lightweight pipeline requiring only a single RGB image as a reference, eliminating the need for costly depth sensors, multi-view image acquisition, or training view synthesis models and neural fields. This enables SingRef6D to remain robust and capable even under resource-limited settings where depth or dense templates are unavailable. Our framework incorporates two key innovations. First, we propose a token-scaler-based fine-tuning mechanism with a novel optimization loss on top of Depth-Anything v2 to enhance its ability to predict accurate depth, even for challenging surfaces. Our results show a 14.41% improvement (in $\delta_{1.05}$) on REAL275 depth prediction compared to Depth-Anything v2 (with fine-tuned head). Second, benefiting from depth availability, we introduce a depth-aware matching process that effectively integrates spatial relationships within LoFTR, enabling our system to handle matching for challenging materials and lighting conditions. Evaluations of pose estimation on the REAL275, ClearPose, and Toyota-Light datasets show that our approach surpasses state-of-the-art methods, achieving a 6.1% improvement in average recall.
Few-Shot Point Cloud Semantic Segmentation via Contrastive Self-Supervision and Multi-Resolution Attention
Feb 21, 2023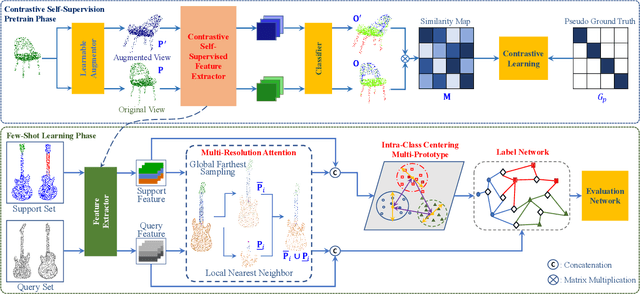
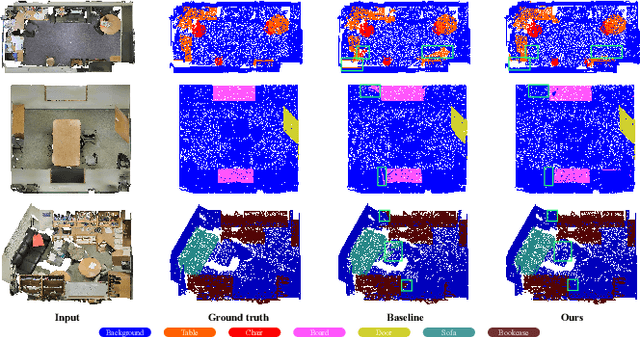
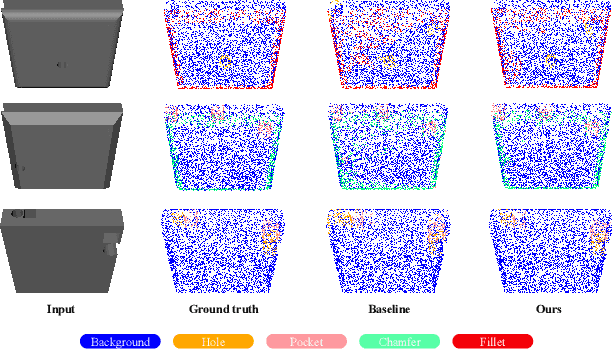
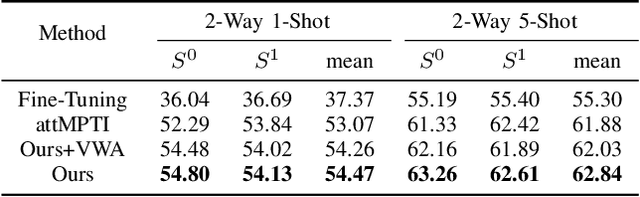
This paper presents an effective few-shot point cloud semantic segmentation approach for real-world applications. Existing few-shot segmentation methods on point cloud heavily rely on the fully-supervised pretrain with large annotated datasets, which causes the learned feature extraction bias to those pretrained classes. However, as the purpose of few-shot learning is to handle unknown/unseen classes, such class-specific feature extraction in pretrain is not ideal to generalize into new classes for few-shot learning. Moreover, point cloud datasets hardly have a large number of classes due to the annotation difficulty. To address these issues, we propose a contrastive self-supervision framework for few-shot learning pretrain, which aims to eliminate the feature extraction bias through class-agnostic contrastive supervision. Specifically, we implement a novel contrastive learning approach with a learnable augmentor for a 3D point cloud to achieve point-wise differentiation, so that to enhance the pretrain with managed overfitting through the self-supervision. Furthermore, we develop a multi-resolution attention module using both the nearest and farthest points to extract the local and global point information more effectively, and a center-concentrated multi-prototype is adopted to mitigate the intra-class sparsity. Comprehensive experiments are conducted to evaluate the proposed approach, which shows our approach achieves state-of-the-art performance. Moreover, a case study on practical CAM/CAD segmentation is presented to demonstrate the effectiveness of our approach for real-world applications.
CAM/CAD Point Cloud Part Segmentation via Few-Shot Learning
Jul 16, 2022
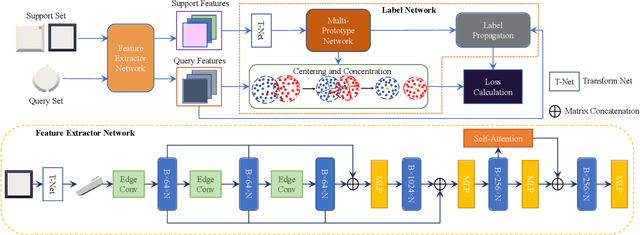


3D part segmentation is an essential step in advanced CAM/CAD workflow. Precise 3D segmentation contributes to lower defective rate of work-pieces produced by the manufacturing equipment (such as computer controlled CNCs), thereby improving work efficiency and attaining the attendant economic benefits. A large class of existing works on 3D model segmentation are mostly based on fully-supervised learning, which trains the AI models with large, annotated datasets. However, the disadvantage is that the resulting models from the fully-supervised learning methodology are highly reliant on the completeness of the available dataset, and its generalization ability is relatively poor to new unknown segmentation types (i.e. further additional novel classes). In this work, we propose and develop a noteworthy few-shot learning-based approach for effective part segmentation in CAM/CAD; and this is designed to significantly enhance its generalization ability and flexibly adapt to new segmentation tasks by using only relatively rather few samples. As a result, it not only reduces the requirements for the usually unattainable and exhaustive completeness of supervision datasets, but also improves the flexibility for real-world applications. As further improvement and innovation, we additionally adopt the transform net and the center loss block in the network. These characteristics serve to improve the comprehension for 3D features of the various possible instances of the whole work-piece and ensure the close distribution of the same class in feature space.
Masked Self-Supervision for Remaining Useful Lifetime Prediction in Machine Tools
Jul 04, 2022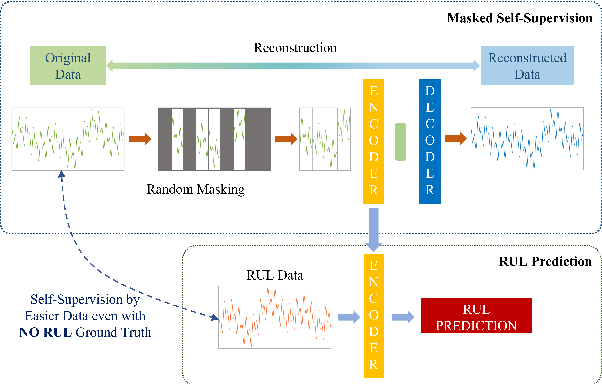



Prediction of Remaining Useful Lifetime(RUL) in the modern manufacturing and automation workplace for machines and tools is essential in Industry 4.0. This is clearly evident as continuous tool wear, or worse, sudden machine breakdown will lead to various manufacturing failures which would clearly cause economic loss. With the availability of deep learning approaches, the great potential and prospect of utilizing these for RUL prediction have resulted in several models which are designed driven by operation data of manufacturing machines. Current efforts in these which are based on fully-supervised models heavily rely on the data labeled with their RULs. However, the required RUL prediction data (i.e. the annotated and labeled data from faulty and/or degraded machines) can only be obtained after the machine breakdown occurs. The scarcity of broken machines in the modern manufacturing and automation workplace in real-world situations increases the difficulty of getting sufficient annotated and labeled data. In contrast, the data from healthy machines is much easier to be collected. Noting this challenge and the potential for improved effectiveness and applicability, we thus propose (and also fully develop) a method based on the idea of masked autoencoders which will utilize unlabeled data to do self-supervision. In thus the work here, a noteworthy masked self-supervised learning approach is developed and utilized. This is designed to seek to build a deep learning model for RUL prediction by utilizing unlabeled data. The experiments to verify the effectiveness of this development are implemented on the C-MAPSS datasets (which are collected from the data from the NASA turbofan engine). The results rather clearly show that our development and approach here perform better, in both accuracy and effectiveness, for RUL prediction when compared with approaches utilizing a fully-supervised model.
R2: Heuristic Bug-Based Any-angle Path-Planning using Lazy Searches
Jun 28, 2022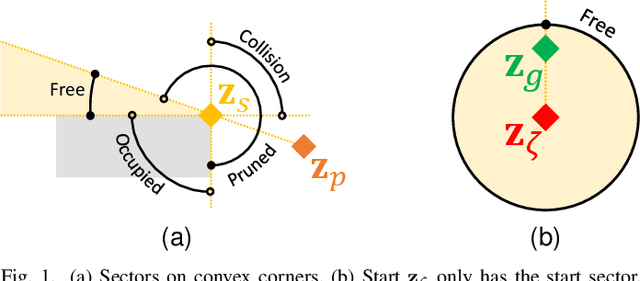
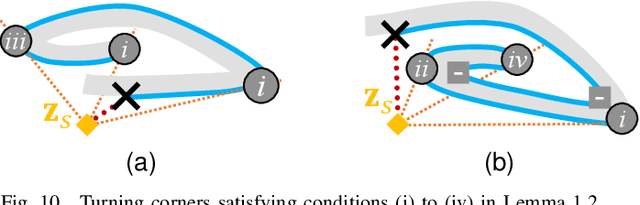
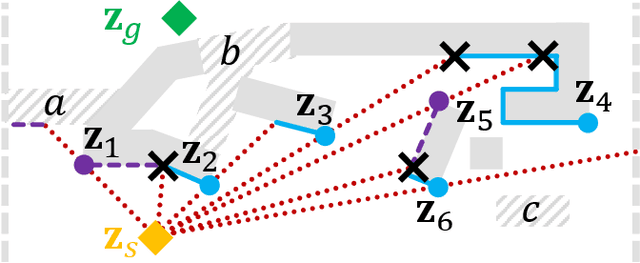
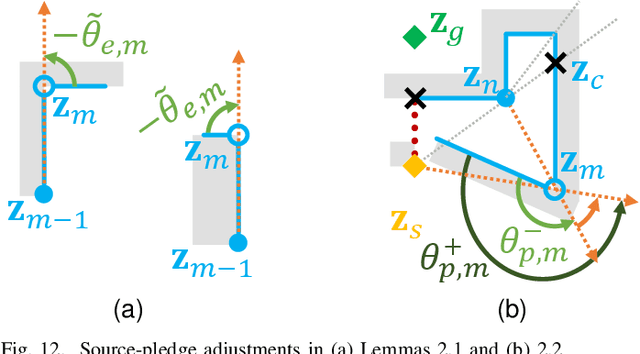
R2 is a novel online any-angle path planner that uses heuristic bug-based or ray casting approaches to find optimal paths in 2D maps with non-convex, polygonal obstacles. R2 is competitive to traditional free-space planners, finding paths quickly if queries have direct line-of-sight. On large sparse maps with few obstacle contours, which are likely to occur in practice, R2 outperforms free-space planners, and can be much faster than state-of-the-art free-space expansion planner Anya. On maps with many contours, Anya performs faster than R2. R2 is built on RayScan, introducing lazy-searches and a source-pledge counter to find successors optimistically on contiguous contours. The novel approach bypasses most successors on jagged contours to reduce expensive line-of-sight checks, therefore requiring no pre-processing to be a competitive online any-angle planner.
Incremental Few-Shot Learning via Implanting and Compressing
Apr 07, 2022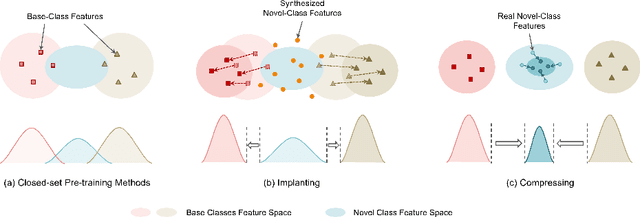
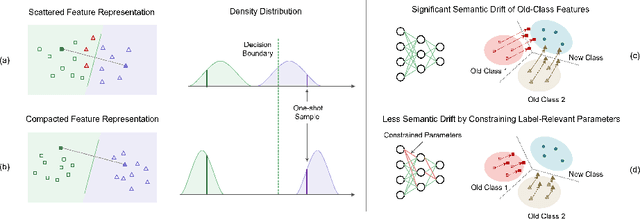
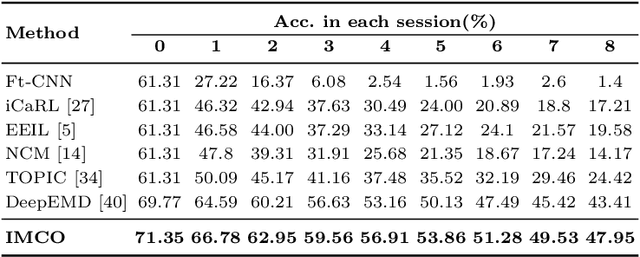
This work focuses on tackling the challenging but realistic visual task of Incremental Few-Shot Learning (IFSL), which requires a model to continually learn novel classes from only a few examples while not forgetting the base classes on which it was pre-trained. Our study reveals that the challenges of IFSL lie in both inter-class separation and novel-class representation. Dur to intra-class variation, a novel class may implicitly leverage the knowledge from multiple base classes to construct its feature representation. Hence, simply reusing the pre-trained embedding space could lead to a scattered feature distribution and result in category confusion. To address such issues, we propose a two-step learning strategy referred to as \textbf{Im}planting and \textbf{Co}mpressing (\textbf{IMCO}), which optimizes both feature space partition and novel class reconstruction in a systematic manner. Specifically, in the \textbf{Implanting} step, we propose to mimic the data distribution of novel classes with the assistance of data-abundant base set, so that a model could learn semantically-rich features that are beneficial for discriminating between the base and other unseen classes. In the \textbf{Compressing} step, we adapt the feature extractor to precisely represent each novel class for enhancing intra-class compactness, together with a regularized parameter updating rule for preventing aggressive model updating. Finally, we demonstrate that IMCO outperforms competing baselines with a significant margin, both in image classification task and more challenging object detection task.
Velocity Obstacle Based Risk-Bounded Motion Planning for Stochastic Multi-Agent Systems
Feb 20, 2022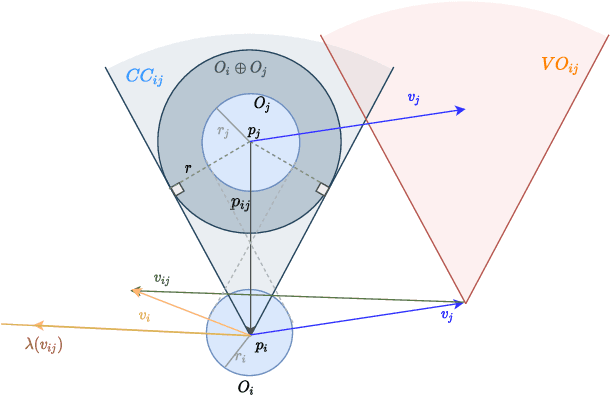
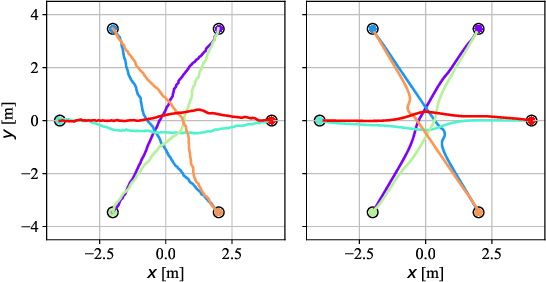
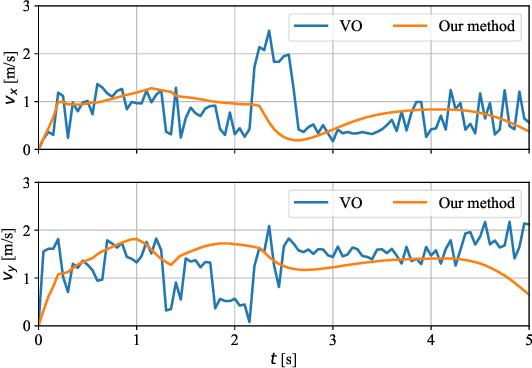
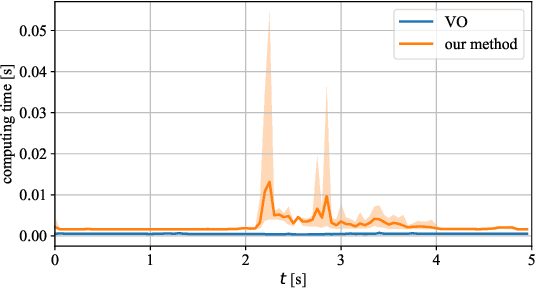
In this paper, we present an innovative risk-bounded motion planning methodology for stochastic multi-agent systems. For this methodology, the disturbance, noise, and model uncertainty are considered; and a velocity obstacle method is utilized to formulate the collision-avoidance constraints in the velocity space. With the exploitation of geometric information of static obstacles and velocity obstacles, a distributed optimization problem with probabilistic chance constraints is formulated for the stochastic multi-agent system. Consequently, collision-free trajectories are generated under a prescribed collision risk bound. Due to the existence of probabilistic and disjunctive constraints, the distributed chance-constrained optimization problem is reformulated as a mixed-integer program by introducing the binary variable to improve computational efficiency. This approach thus renders it possible to execute the motion planning task in the velocity space instead of the position space, which leads to smoother collision-free trajectories for multi-agent systems and higher computational efficiency. Moreover, the risk of potential collisions is bounded with this robust motion planning methodology. To validate the effectiveness of the methodology, different scenarios for multiple agents are investigated, and the simulation results clearly show that the proposed approach can generate high-quality trajectories under a predefined collision risk bound and avoid potential collisions effectively in the velocity space.
Towards Generalized and Incremental Few-Shot Object Detection
Sep 23, 2021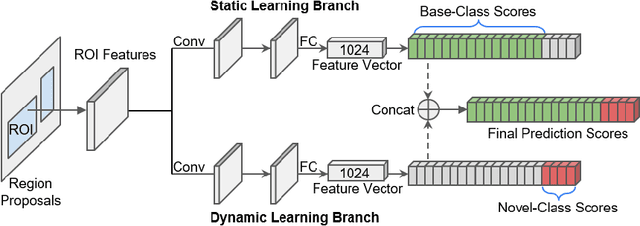
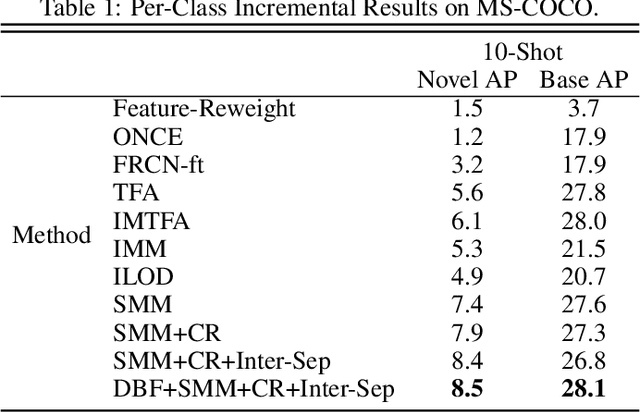
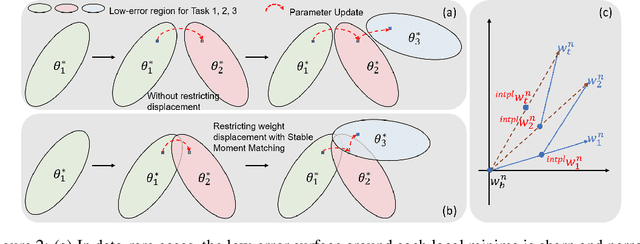
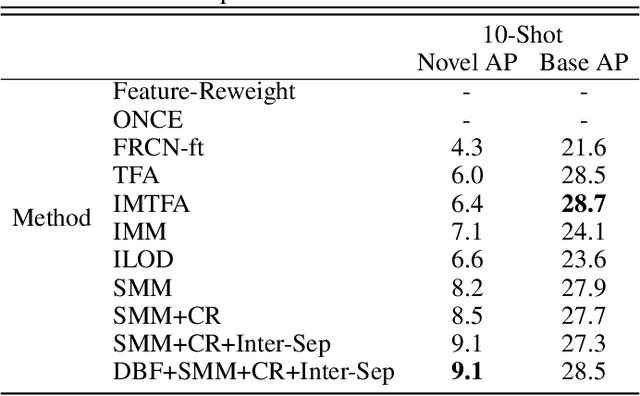
Real-world object detection is highly desired to be equipped with the learning expandability that can enlarge its detection classes incrementally. Moreover, such learning from only few annotated training samples further adds the flexibility for the object detector, which is highly expected in many applications such as autonomous driving, robotics, etc. However, such sequential learning scenario with few-shot training samples generally causes catastrophic forgetting and dramatic overfitting. In this paper, to address the above incremental few-shot learning issues, a novel Incremental Few-Shot Object Detection (iFSOD) method is proposed to enable the effective continual learning from few-shot samples. Specifically, a Double-Branch Framework (DBF) is proposed to decouple the feature representation of base and novel (few-shot) class, which facilitates both the old-knowledge retention and new-class adaption simultaneously. Furthermore, a progressive model updating rule is carried out to preserve the long-term memory on old classes effectively when adapt to sequential new classes. Moreover, an inter-task class separation loss is proposed to extend the decision region of new-coming classes for better feature discrimination. We conduct experiments on both Pascal VOC and MS-COCO, which demonstrate that our method can effectively solve the problem of incremental few-shot detection and significantly improve the detection accuracy on both base and novel classes.
Differentiable Moving Horizon Estimation for Robust Flight Control
Aug 29, 2021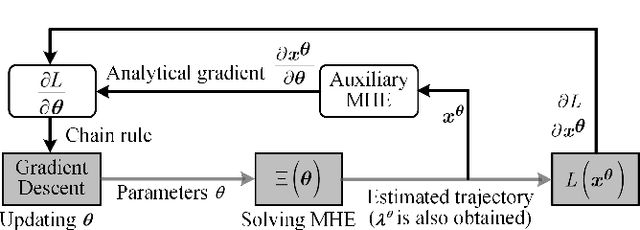
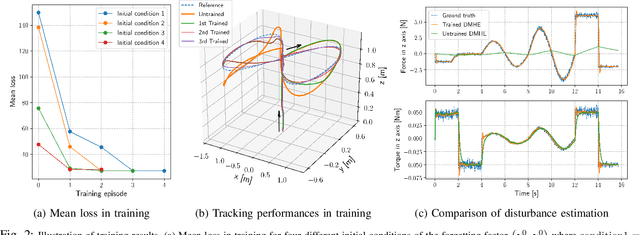
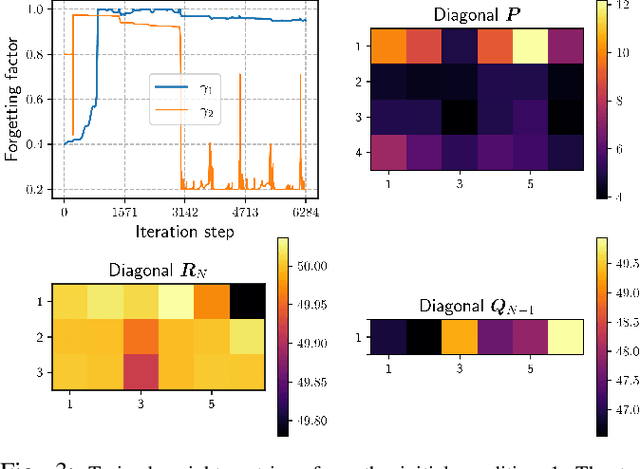
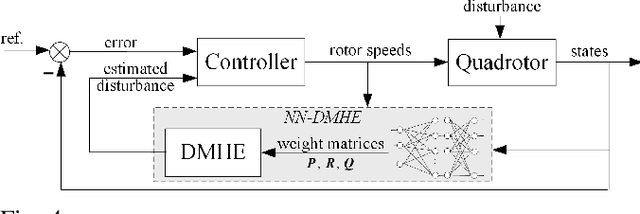
Estimating and reacting to external disturbances is of fundamental importance for robust control of quadrotors. Existing estimators typically require significant tuning or training with a large amount of data, including the ground truth, to achieve satisfactory performance. This paper proposes a data-efficient differentiable moving horizon estimation (DMHE) algorithm that can automatically tune the MHE parameters online and also adapt to different scenarios. We achieve this by deriving the analytical gradient of the estimated trajectory from MHE with respect to the tuning parameters, enabling end-to-end learning for auto-tuning. Most interestingly, we show that the gradient can be calculated efficiently from a Kalman filter in a recursive form. Moreover, we develop a model-based policy gradient algorithm to learn the parameters directly from the trajectory tracking errors without the need for the ground truth. The proposed DMHE can be further embedded as a layer with other neural networks for joint optimization. Finally, we demonstrate the effectiveness of the proposed method via both simulation and experiments on quadrotors, where challenging scenarios such as sudden payload change and flying in downwash are examined.