 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorSplat: Feed-Forward 3D Gaussian Splatting with 3D Geometric Priors
Apr 09, 2026Recent feed-forward Gaussian reconstruction models adopt a pixel-aligned formulation that maps each 2D pixel to a 3D Gaussian, entangling Gaussian representations tightly with the input images. In this paper, we propose AnchorSplat, a novel feed-forward 3DGS framework for scene-level reconstruction that represents the scene directly in 3D space. AnchorSplat introduces an anchor-aligned Gaussian representation guided by 3D geometric priors (e.g., sparse point clouds, voxels, or RGB-D point clouds), enabling a more geometry-aware renderable 3D Gaussians that is independent of image resolution and number of views. This design substantially reduces the number of required Gaussians, improving computational efficiency while enhancing reconstruction fidelity. Beyond the anchor-aligned design, we utilize a Gaussian Refiner to adjust the intermediate Gaussiansy via merely a few forward passes. Experiments on the ScanNet++ v2 NVS benchmark demonstrate the SOTA performance, outperforming previous methods with more view-consistent and substantially fewer Gaussian primitives.
GenTorrent: Scaling Large Language Model Serving with An Overley Network
Apr 30, 2025While significant progress has been made in research and development on open-source and cost-efficient large-language models (LLMs), serving scalability remains a critical challenge, particularly for small organizations and individuals seeking to deploy and test their LLM innovations. Inspired by peer-to-peer networks that leverage decentralized overlay nodes to increase throughput and availability, we propose GenTorrent, an LLM serving overlay that harnesses computing resources from decentralized contributors. We identify four key research problems inherent to enabling such a decentralized infrastructure: 1) overlay network organization; 2) LLM communication privacy; 3) overlay forwarding for resource efficiency; and 4) verification of serving quality. This work presents the first systematic study of these fundamental problems in the context of decentralized LLM serving. Evaluation results from a prototype implemented on a set of decentralized nodes demonstrate that GenTorrent achieves a latency reduction of over 50% compared to the baseline design without overlay forwarding. Furthermore, the security features introduce minimal overhead to serving latency and throughput. We believe this work pioneers a new direction for democratizing and scaling future AI serving capabilities.
Secure Decentralized Learning with Blockchain
Oct 10, 2023Federated Learning (FL) is a well-known paradigm of distributed machine learning on mobile and IoT devices, which preserves data privacy and optimizes communication efficiency. To avoid the single point of failure problem in FL, decentralized federated learning (DFL) has been proposed to use peer-to-peer communication for model aggregation, which has been considered an attractive solution for machine learning tasks on distributed personal devices. However, this process is vulnerable to attackers who share false models and data. If there exists a group of malicious clients, they might harm the performance of the model by carrying out a poisoning attack. In addition, in DFL, clients often lack the incentives to contribute their computing powers to do model training. In this paper, we proposed Blockchain-based Decentralized Federated Learning (BDFL), which leverages a blockchain for decentralized model verification and auditing. BDFL includes an auditor committee for model verification, an incentive mechanism to encourage the participation of clients, a reputation model to evaluate the trustworthiness of clients, and a protocol suite for dynamic network updates. Evaluation results show that, with the reputation mechanism, BDFL achieves fast model convergence and high accuracy on real datasets even if there exist 30\% malicious clients in the system.
A universal and improved mutation strategy for iterative wavefront shaping
Nov 21, 2022Recent advances in iterative wavefront shaping (WFS) techniques have made it possible to manipulate the light focusing and transport in scattering media. To improve the optimization performance, various optimization algorithms and improved strategies have been utilized. Here, a novel guided mutation (GM) strategy is proposed to improve optimization efficiency for iterative WFS. For both phase modulation and binary amplitude modulation, considerable improvements in optimization effect and rate have been obtained using multiple GM-enhanced algorithms. Due of its improvements and universality, GM is beneficial for applications ranging from controlling the transmission of light through disordered media to optical manipulation behind them.
Velocity Obstacle Based Risk-Bounded Motion Planning for Stochastic Multi-Agent Systems
Feb 20, 2022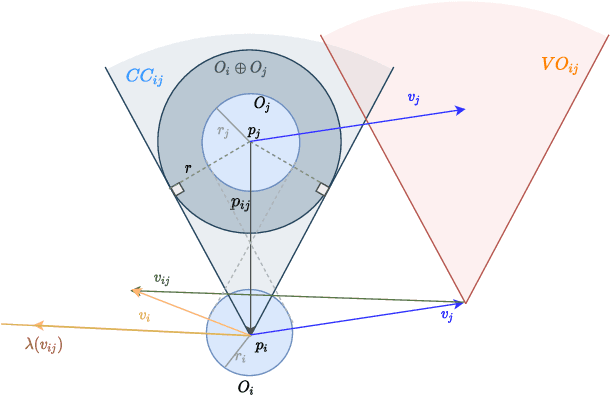
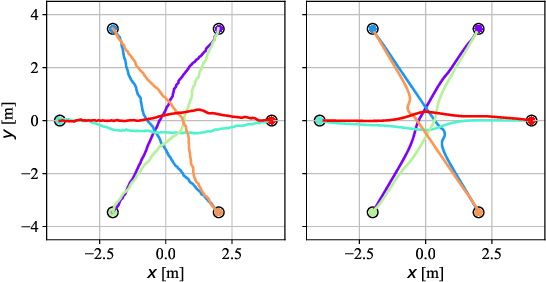
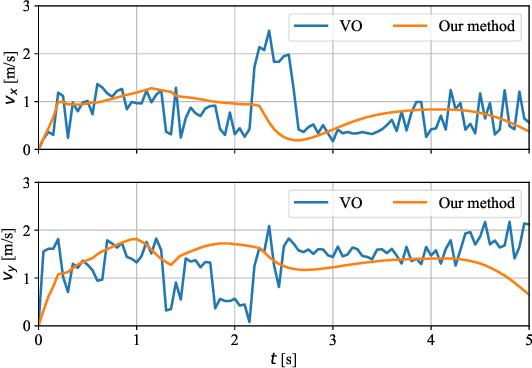
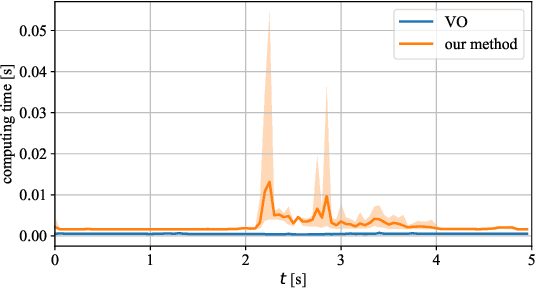
In this paper, we present an innovative risk-bounded motion planning methodology for stochastic multi-agent systems. For this methodology, the disturbance, noise, and model uncertainty are considered; and a velocity obstacle method is utilized to formulate the collision-avoidance constraints in the velocity space. With the exploitation of geometric information of static obstacles and velocity obstacles, a distributed optimization problem with probabilistic chance constraints is formulated for the stochastic multi-agent system. Consequently, collision-free trajectories are generated under a prescribed collision risk bound. Due to the existence of probabilistic and disjunctive constraints, the distributed chance-constrained optimization problem is reformulated as a mixed-integer program by introducing the binary variable to improve computational efficiency. This approach thus renders it possible to execute the motion planning task in the velocity space instead of the position space, which leads to smoother collision-free trajectories for multi-agent systems and higher computational efficiency. Moreover, the risk of potential collisions is bounded with this robust motion planning methodology. To validate the effectiveness of the methodology, different scenarios for multiple agents are investigated, and the simulation results clearly show that the proposed approach can generate high-quality trajectories under a predefined collision risk bound and avoid potential collisions effectively in the velocity space.
Receding Horizon Motion Planning for Multi-Agent Systems: A Velocity Obstacle Based Probabilistic Method
Mar 24, 2021
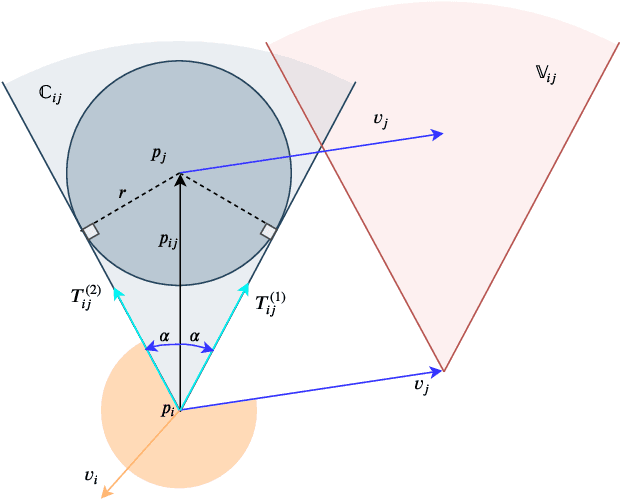
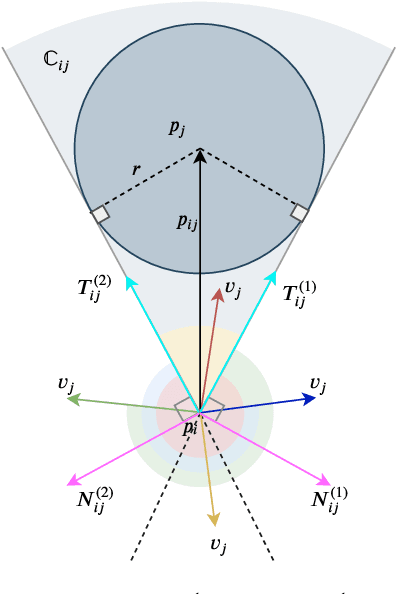
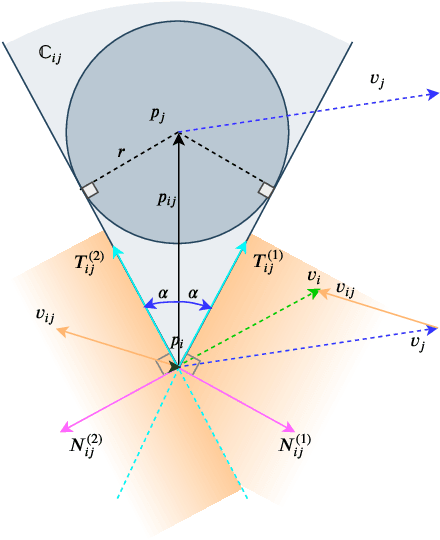
In this paper, a novel and innovative methodology for feasible motion planning in the multi-agent system is developed. On the basis of velocity obstacles characteristics, the chance constraints are formulated in the receding horizon control (RHC) problem, and geometric information of collision cones is used to generate the feasible regions of velocities for the host agent. By this approach, the motion planning is conducted at the velocity level instead of the position level. Thus, it guarantees a safer collision-free trajectory for the multi-agent system, especially for the systems with high-speed moving agents. Moreover, a probability threshold of potential collisions can be satisfied during the motion planning process. In order to validate the effectiveness of the methodology, different scenarios for multiple agents are investigated, and the simulation results clearly show that the proposed approach can effectively avoid potential collisions with a collision probability less than a specific threshold.
Neural Network iLQR: A New Reinforcement Learning Architecture
Nov 21, 2020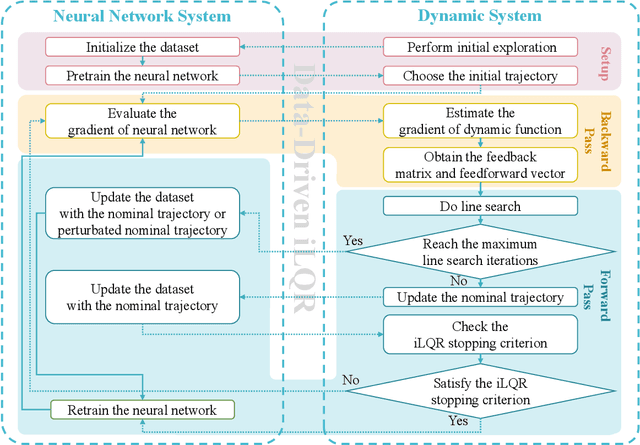
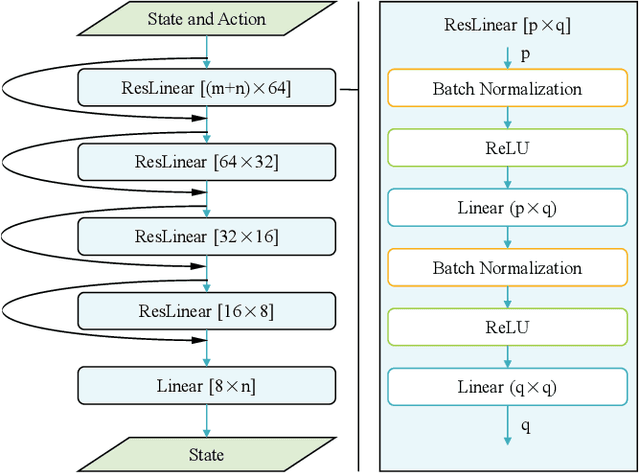
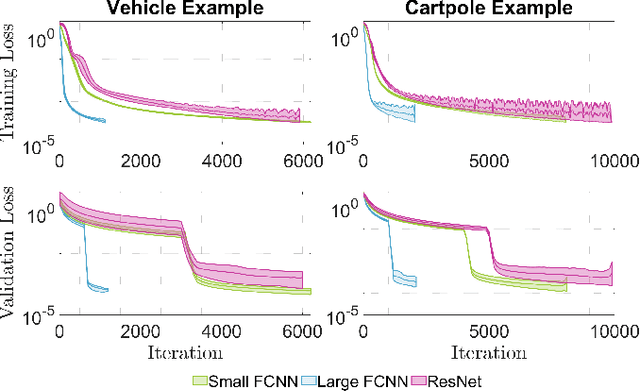
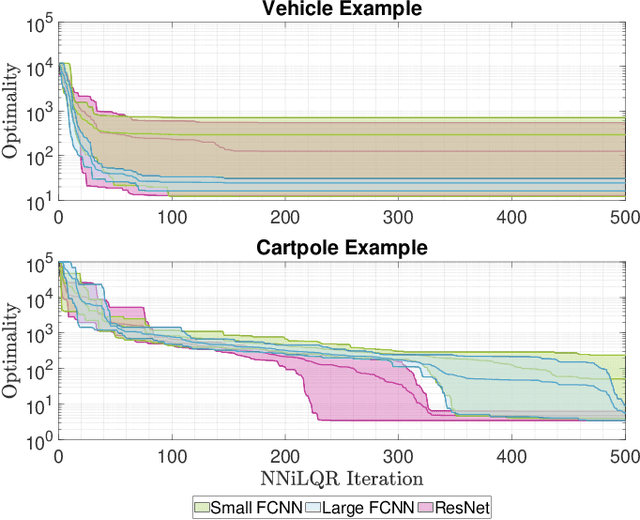
As a notable machine learning paradigm, the research efforts in the context of reinforcement learning have certainly progressed leaps and bounds. When compared with reinforcement learning methods with the given system model, the methodology of the reinforcement learning architecture based on the unknown model generally exhibits significantly broader universality and applicability. In this work, a new reinforcement learning architecture is developed and presented without the requirement of any prior knowledge of the system model, which is termed as an approach of a "neural network iterative linear quadratic regulator (NNiLQR)". Depending solely on measurement data, this method yields a completely new non-parametric routine for the establishment of the optimal policy (without the necessity of system modeling) through iterative refinements of the neural network system. Rather importantly, this approach significantly outperforms the classical iterative linear quadratic regulator (iLQR) method in terms of the given objective function because of the innovative utilization of further exploration in the methodology. As clearly indicated from the results attained in two illustrative examples, these significant merits of the NNiLQR method are demonstrated rather evidently.
Data-Driven Predictive Control for Multi-Agent Decision Making With Chance Constraints
Nov 06, 2020


In the recent literature, significant and substantial efforts have been dedicated to the important area of multi-agent decision-making problems. Particularly here, the model predictive control (MPC) methodology has demonstrated its effectiveness in various applications, such as mobile robots, unmanned vehicles, and drones. Nevertheless, in many specific scenarios involving the MPC methodology, accurate and effective system identification is a commonly encountered challenge. As a consequence, the overall system performance could be significantly weakened in outcome when the traditional MPC algorithm is adopted under such circumstances. To cater to this rather major shortcoming, this paper investigates an alternate data-driven approach to solve the multi-agent decision-making problem. Utilizing an innovative modified methodology with suitable closed-loop input/output measurements that comply with the appropriate persistency of excitation condition, a non-parametric predictive model is suitably constructed. This non-parametric predictive model approach in the work here attains the key advantage of alleviating the rather heavy computational burden encountered in the optimization procedures typical in alternative methodologies requiring open-loop input/output measurement data collection and parametric system identification. Then with a conservative approximation of probabilistic chance constraints for the MPC problem, a resulting deterministic optimization problem is formulated and solved efficiently and effectively. In the work here, this intuitive data-driven approach is also shown to preserve good robustness properties. Finally, a multi-drone system is used to demonstrate the practical appeal and highly effective outcome of this promising development in achieving very good system performance.
Accelerated Hierarchical ADMM for Nonconvex Optimization in Multi-Agent Decision Making
Nov 01, 2020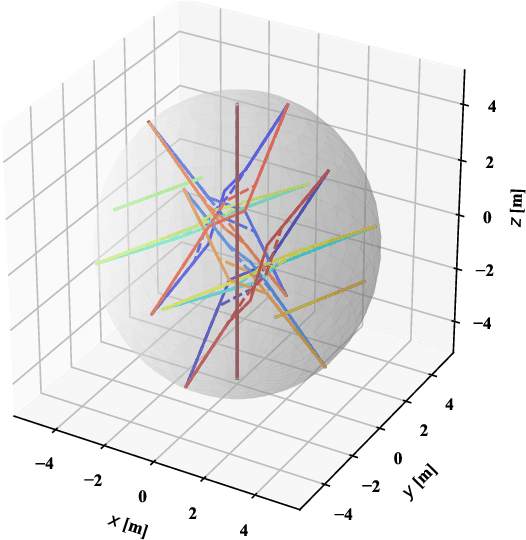
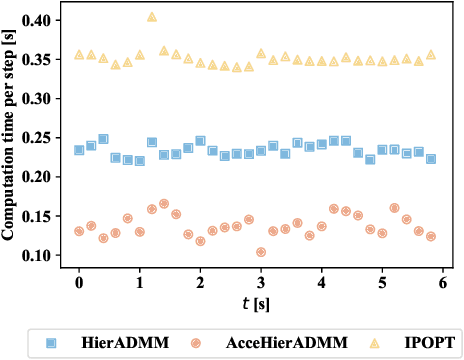
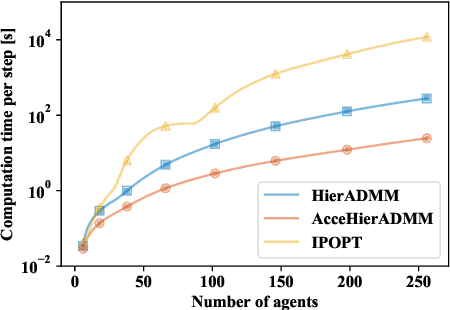
Distributed optimization is widely used to solve large-scale problems effectively in a localized and coordinated manner. Thus, it is noteworthy that the methodology of distributed model predictive control (DMPC) has become a promising approach to achieve effective outcomes; and particularly in decision-making tasks for multi-agent systems. However, the typical deployment of such DMPC frameworks would lead to involvement of nonlinear processes with a large number of nonconvex constraints. Noting all these attendant constraints and limitations, the development and innovation of a hierarchical three-block alternating direction method of multipliers (ADMM) approach is presented in the work here to solve the nonconvex optimization problem that arises for such a decision-making problem in multi-agent systems. Firstly thus, an additional slack variable is introduced to relax the original large-scale nonconvex optimization problem; such that the intractable nonconvex coupling constraints are suitably related to the distributed agents. Then, the approach with a hierarchical ADMM that contains outer loop iteration by the augmented Lagrangian method (ALM), and inner loop iteration by three-block semi-proximal ADMM, is utilized to solve the resulting relaxed nonconvex optimization problem. Additionally, it is shown that the appropriate desired stationary point exists for the procedures of the hierarchical stages for convergence in the algorithm. Next, the approximate optimization with a barrier method is then applied to accelerate the computational efficiency. Finally, a multi-agent system involving decision-making for multiple unmanned aerial vehicles (UAVs) is utilized to demonstrate the effectiveness of the proposed method in terms of attained performance and computational efficiency.
Alternating Direction Method of Multipliers for Constrained Iterative LQR in Autonomous Driving
Nov 01, 2020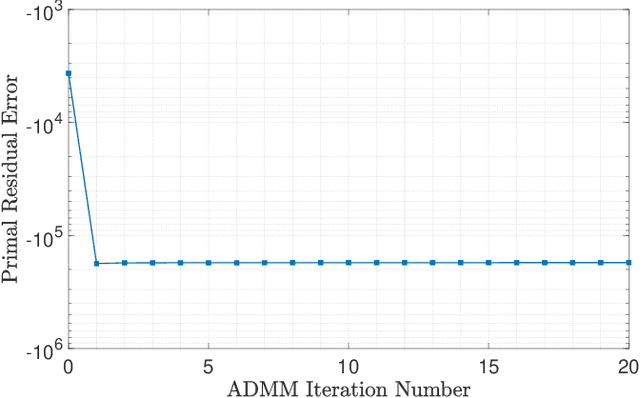
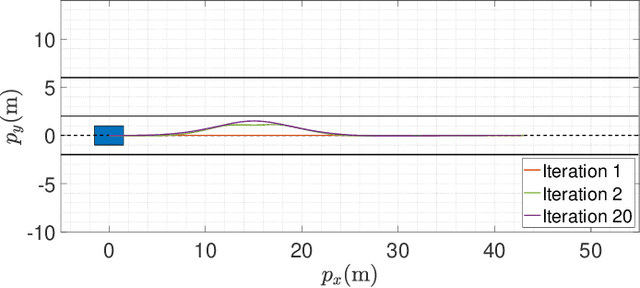
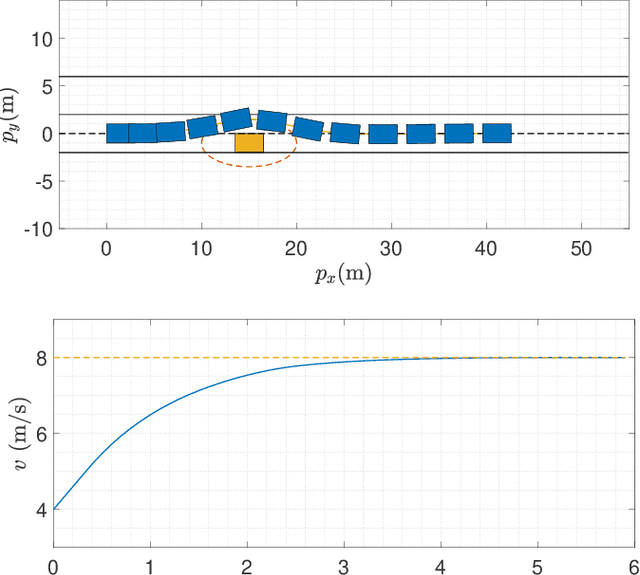
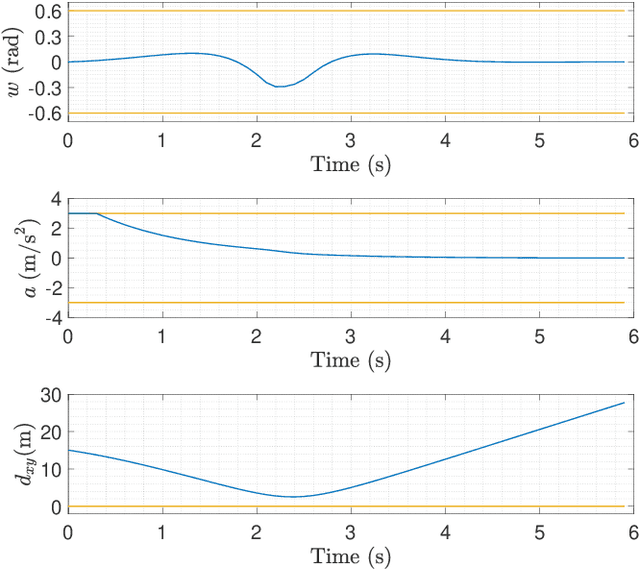
In the context of autonomous driving, the iterative linear quadratic regulator (iLQR) is known to be an efficient approach to deal with the nonlinear vehicle models in motion planning problems. Particularly, the constrained iLQR algorithm has shown noteworthy advantageous outcomes of computation efficiency in achieving motion planning tasks under general constraints of different types. However, the constrained iLQR methodology requires a feasible trajectory at the first iteration as a prerequisite. Also, the methodology leaves open the possibility for incorporation of fast, efficient, and effective optimization methods (i.e., fast-solvers) to further speed up the optimization process such that the requirements of real-time implementation can be successfully fulfilled. In this paper, a well-defined and commonly-encountered motion planning problem is formulated under nonlinear vehicle dynamics and various constraints, and an alternating direction method of multipliers (ADMM) is developed to determine the optimal control actions. With this development, the approach is able to circumvent the feasibility requirement of the trajectory at the first iteration. An illustrative example of motion planning in autonomous vehicles is then investigated with different driving scenarios taken into consideration. As clearly observed from the simulation results, the significance of this work in terms of obstacle avoidance is demonstrated. Furthermore, a noteworthy achievement of high computation efficiency is attained; and as a result, real-time computation and implementation can be realized through this framework, and thus it provides additional safety to the on-road driving tasks.