 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations in Healthcare LLMs with Granular Fact-Checking and Domain-Specific Adaptation
Dec 19, 2025In healthcare, it is essential for any LLM-generated output to be reliable and accurate, particularly in cases involving decision-making and patient safety. However, the outputs are often unreliable in such critical areas due to the risk of hallucinated outputs from the LLMs. To address this issue, we propose a fact-checking module that operates independently of any LLM, along with a domain-specific summarization model designed to minimize hallucination rates. Our model is fine-tuned using Low-Rank Adaptation (LoRa) on the MIMIC III dataset and is paired with the fact-checking module, which uses numerical tests for correctness and logical checks at a granular level through discrete logic in natural language processing (NLP) to validate facts against electronic health records (EHRs). We trained the LLM model on the full MIMIC-III dataset. For evaluation of the fact-checking module, we sampled 104 summaries, extracted them into 3,786 propositions, and used these as facts. The fact-checking module achieves a precision of 0.8904, a recall of 0.8234, and an F1-score of 0.8556. Additionally, the LLM summary model achieves a ROUGE-1 score of 0.5797 and a BERTScore of 0.9120 for summary quality.
PSMamba: Progressive Self-supervised Vision Mamba for Plant Disease Recognition
Dec 16, 2025Self-supervised Learning (SSL) has become a powerful paradigm for representation learning without manual annotations. However, most existing frameworks focus on global alignment and struggle to capture the hierarchical, multi-scale lesion patterns characteristic of plant disease imagery. To address this gap, we propose PSMamba, a progressive self-supervised framework that integrates the efficient sequence modelling of Vision Mamba (VM) with a dual-student hierarchical distillation strategy. Unlike conventional single teacher-student designs, PSMamba employs a shared global teacher and two specialised students: one processes mid-scale views to capture lesion distributions and vein structures, while the other focuses on local views to capture fine-grained cues such as texture irregularities and early-stage lesions. This multi-granular supervision facilitates the joint learning of contextual and detailed representations, with consistency losses ensuring coherent cross-scale alignment. Experiments on three benchmark datasets show that PSMamba consistently outperforms state-of-the-art SSL methods, delivering superior accuracy and robustness in both domain-shifted and fine-grained scenarios.
StateSpace-SSL: Linear-Time Self-supervised Learning for Plant Disease Detection
Dec 11, 2025Self-supervised learning (SSL) is attractive for plant disease detection as it can exploit large collections of unlabeled leaf images, yet most existing SSL methods are built on CNNs or vision transformers that are poorly matched to agricultural imagery. CNN-based SSL struggles to capture disease patterns that evolve continuously along leaf structures, while transformer-based SSL introduces quadratic attention cost from high-resolution patches. To address these limitations, we propose StateSpace-SSL, a linear-time SSL framework that employs a Vision Mamba state-space encoder to model long-range lesion continuity through directional scanning across the leaf surface. A prototype-driven teacher-student objective aligns representations across multiple views, encouraging stable and lesion-aware features from labelled data. Experiments on three publicly available plant disease datasets show that StateSpace-SSL consistently outperforms the CNN- and transformer-based SSL baselines in various evaluation metrics. Qualitative analyses further confirm that it learns compact, lesion-focused feature maps, highlighting the advantage of linear state-space modelling for self-supervised plant disease representation learning.
EPSegFZ: Efficient Point Cloud Semantic Segmentation for Few- and Zero-Shot Scenarios with Language Guidance
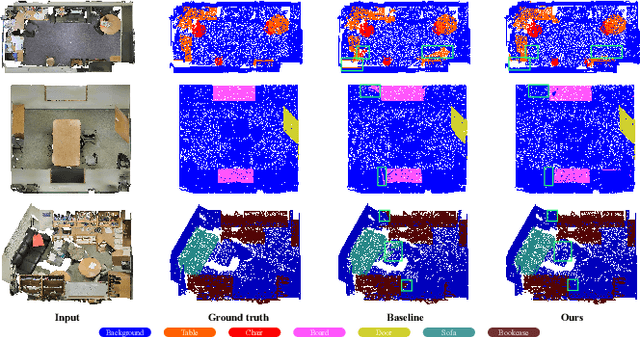
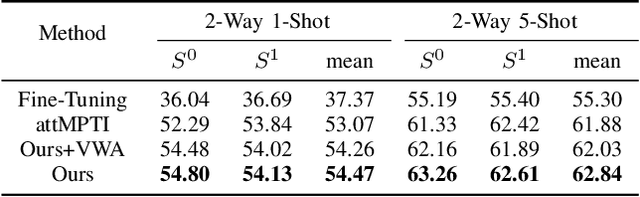
Nov 12, 2025Recent approaches for few-shot 3D point cloud semantic segmentation typically require a two-stage learning process, i.e., a pre-training stage followed by a few-shot training stage. While effective, these methods face overreliance on pre-training, which hinders model flexibility and adaptability. Some models tried to avoid pre-training yet failed to capture ample information. In addition, current approaches focus on visual information in the support set and neglect or do not fully exploit other useful data, such as textual annotations. This inadequate utilization of support information impairs the performance of the model and restricts its zero-shot ability. To address these limitations, we present a novel pre-training-free network, named Efficient Point Cloud Semantic Segmentation for Few- and Zero-shot scenarios. Our EPSegFZ incorporates three key components. A Prototype-Enhanced Registers Attention (ProERA) module and a Dual Relative Positional Encoding (DRPE)-based cross-attention mechanism for improved feature extraction and accurate query-prototype correspondence construction without pre-training. A Language-Guided Prototype Embedding (LGPE) module that effectively leverages textual information from the support set to improve few-shot performance and enable zero-shot inference. Extensive experiments show that our method outperforms the state-of-the-art method by 5.68% and 3.82% on the S3DIS and ScanNet benchmarks, respectively.
SingRef6D: Monocular Novel Object Pose Estimation with a Single RGB Reference
Sep 26, 2025Recent 6D pose estimation methods demonstrate notable performance but still face some practical limitations. For instance, many of them rely heavily on sensor depth, which may fail with challenging surface conditions, such as transparent or highly reflective materials. In the meantime, RGB-based solutions provide less robust matching performance in low-light and texture-less scenes due to the lack of geometry information. Motivated by these, we propose SingRef6D, a lightweight pipeline requiring only a single RGB image as a reference, eliminating the need for costly depth sensors, multi-view image acquisition, or training view synthesis models and neural fields. This enables SingRef6D to remain robust and capable even under resource-limited settings where depth or dense templates are unavailable. Our framework incorporates two key innovations. First, we propose a token-scaler-based fine-tuning mechanism with a novel optimization loss on top of Depth-Anything v2 to enhance its ability to predict accurate depth, even for challenging surfaces. Our results show a 14.41% improvement (in $\delta_{1.05}$) on REAL275 depth prediction compared to Depth-Anything v2 (with fine-tuned head). Second, benefiting from depth availability, we introduce a depth-aware matching process that effectively integrates spatial relationships within LoFTR, enabling our system to handle matching for challenging materials and lighting conditions. Evaluations of pose estimation on the REAL275, ClearPose, and Toyota-Light datasets show that our approach surpasses state-of-the-art methods, achieving a 6.1% improvement in average recall.
Optimizing Deep Learning for Skin Cancer Classification: A Computationally Efficient CNN with Minimal Accuracy Trade-Off
May 27, 2025



The rapid advancement of deep learning in medical image analysis has greatly enhanced the accuracy of skin cancer classification. However, current state-of-the-art models, especially those based on transfer learning like ResNet50, come with significant computational overhead, rendering them impractical for deployment in resource-constrained environments. This study proposes a custom CNN model that achieves a 96.7\% reduction in parameters (from 23.9 million in ResNet50 to 692,000) while maintaining a classification accuracy deviation of less than 0.022\%. Our empirical analysis of the HAM10000 dataset reveals that although transfer learning models provide a marginal accuracy improvement of approximately 0.022\%, they result in a staggering 13,216.76\% increase in FLOPs, considerably raising computational costs and inference latency. In contrast, our lightweight CNN architecture, which encompasses only 30.04 million FLOPs compared to ResNet50's 4.00 billion, significantly reduces energy consumption, memory footprint, and inference time. These findings underscore the trade-off between the complexity of deep models and their real-world feasibility, positioning our optimized CNN as a practical solution for mobile and edge-based skin cancer diagnostics.
Crash Severity Risk Modeling Strategies under Data Imbalance
Dec 03, 2024



This study investigates crash severity risk modeling strategies for work zones involving large vehicles (i.e., trucks, buses, and vans) when there are crash data imbalance between low-severity (LS) and high-severity (HS) crashes. We utilized crash data, involving large vehicles in South Carolina work zones for the period between 2014 and 2018, which included 4 times more LS crashes compared to HS crashes. The objective of this study is to explore crash severity prediction performance of various models under different feature selection and data balancing techniques. The findings of this study highlight a disparity between LS and HS predictions, with less-accurate prediction of HS crashes compared to LS crashes due to class imbalance and feature overlaps between LS and HS crashes. Combining features from multiple feature selection techniques: statistical correlation, feature importance, recursive elimination, statistical tests, and mutual information, slightly improves HS crash prediction performance. Data balancing techniques such as NearMiss-1 and RandomUnderSampler, maximize HS recall when paired with certain prediction models, such as Bayesian Mixed Logit (BML), NeuralNet, and RandomForest, making them suitable for HS crash prediction. Conversely, RandomOverSampler, HS Class Weighting, and Kernel-based Synthetic Minority Oversampling (K-SMOTE), used with certain prediction models such as BML, CatBoost, and LightGBM, achieve a balanced performance, defined as achieving an equitable trade-off between LS and HS prediction performance metrics. These insights provide safety analysts with guidance to select models, feature selection techniques, and data balancing techniques that align with their specific safety objectives, offering a robust foundation for enhancing work-zone crash severity prediction.
Few-Shot Point Cloud Semantic Segmentation via Contrastive Self-Supervision and Multi-Resolution Attention
Feb 21, 2023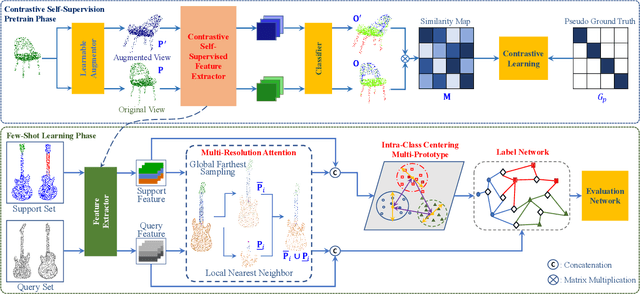
This paper presents an effective few-shot point cloud semantic segmentation approach for real-world applications. Existing few-shot segmentation methods on point cloud heavily rely on the fully-supervised pretrain with large annotated datasets, which causes the learned feature extraction bias to those pretrained classes. However, as the purpose of few-shot learning is to handle unknown/unseen classes, such class-specific feature extraction in pretrain is not ideal to generalize into new classes for few-shot learning. Moreover, point cloud datasets hardly have a large number of classes due to the annotation difficulty. To address these issues, we propose a contrastive self-supervision framework for few-shot learning pretrain, which aims to eliminate the feature extraction bias through class-agnostic contrastive supervision. Specifically, we implement a novel contrastive learning approach with a learnable augmentor for a 3D point cloud to achieve point-wise differentiation, so that to enhance the pretrain with managed overfitting through the self-supervision. Furthermore, we develop a multi-resolution attention module using both the nearest and farthest points to extract the local and global point information more effectively, and a center-concentrated multi-prototype is adopted to mitigate the intra-class sparsity. Comprehensive experiments are conducted to evaluate the proposed approach, which shows our approach achieves state-of-the-art performance. Moreover, a case study on practical CAM/CAD segmentation is presented to demonstrate the effectiveness of our approach for real-world applications.
CAM/CAD Point Cloud Part Segmentation via Few-Shot Learning
Jul 16, 2022
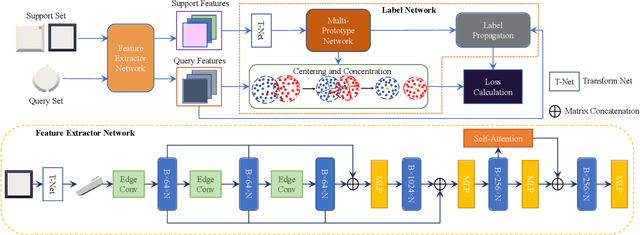


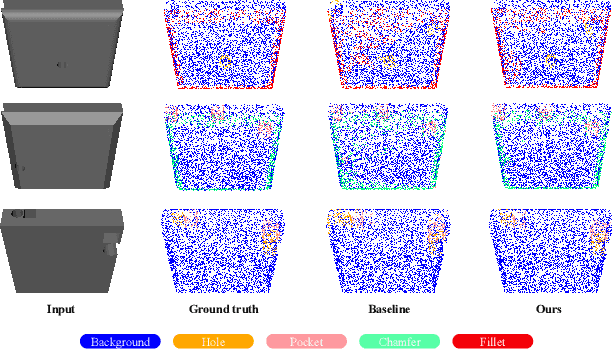
3D part segmentation is an essential step in advanced CAM/CAD workflow. Precise 3D segmentation contributes to lower defective rate of work-pieces produced by the manufacturing equipment (such as computer controlled CNCs), thereby improving work efficiency and attaining the attendant economic benefits. A large class of existing works on 3D model segmentation are mostly based on fully-supervised learning, which trains the AI models with large, annotated datasets. However, the disadvantage is that the resulting models from the fully-supervised learning methodology are highly reliant on the completeness of the available dataset, and its generalization ability is relatively poor to new unknown segmentation types (i.e. further additional novel classes). In this work, we propose and develop a noteworthy few-shot learning-based approach for effective part segmentation in CAM/CAD; and this is designed to significantly enhance its generalization ability and flexibly adapt to new segmentation tasks by using only relatively rather few samples. As a result, it not only reduces the requirements for the usually unattainable and exhaustive completeness of supervision datasets, but also improves the flexibility for real-world applications. As further improvement and innovation, we additionally adopt the transform net and the center loss block in the network. These characteristics serve to improve the comprehension for 3D features of the various possible instances of the whole work-piece and ensure the close distribution of the same class in feature space.
R2: Heuristic Bug-Based Any-angle Path-Planning using Lazy Searches
Jun 28, 2022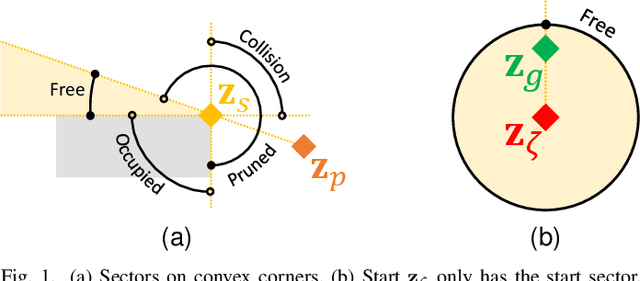
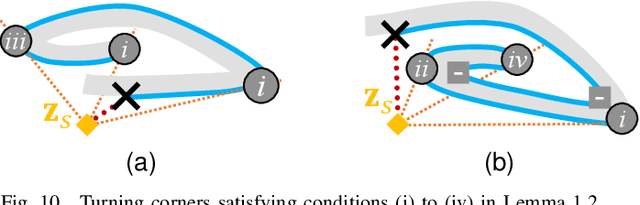
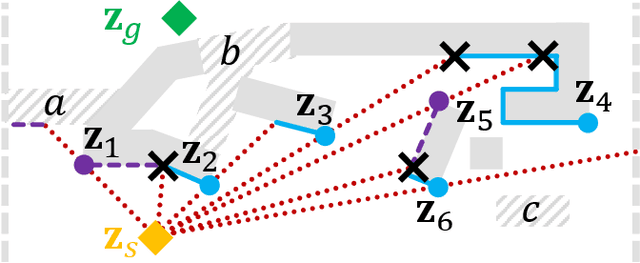
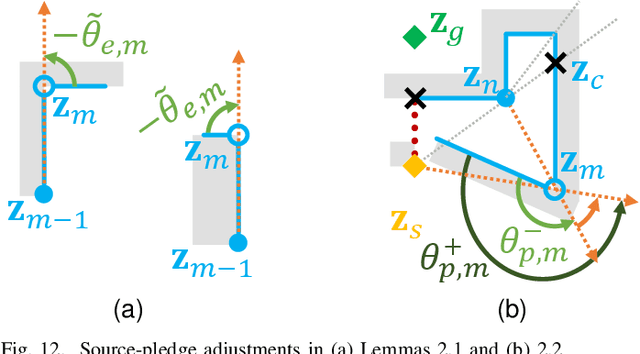
R2 is a novel online any-angle path planner that uses heuristic bug-based or ray casting approaches to find optimal paths in 2D maps with non-convex, polygonal obstacles. R2 is competitive to traditional free-space planners, finding paths quickly if queries have direct line-of-sight. On large sparse maps with few obstacle contours, which are likely to occur in practice, R2 outperforms free-space planners, and can be much faster than state-of-the-art free-space expansion planner Anya. On maps with many contours, Anya performs faster than R2. R2 is built on RayScan, introducing lazy-searches and a source-pledge counter to find successors optimistically on contiguous contours. The novel approach bypasses most successors on jagged contours to reduce expensive line-of-sight checks, therefore requiring no pre-processing to be a competitive online any-angle planner.