 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial expressions can detect Parkinson's disease: preliminary evidence from videos collected online
Dec 09, 2020
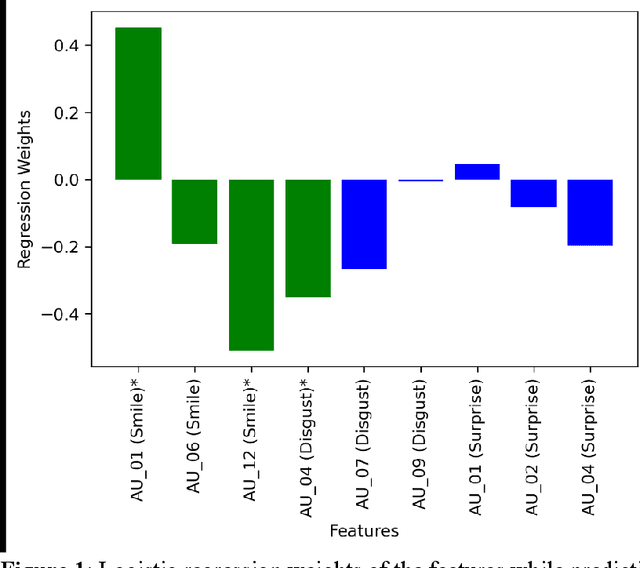
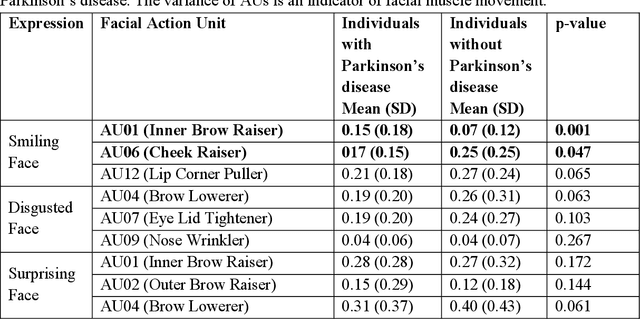
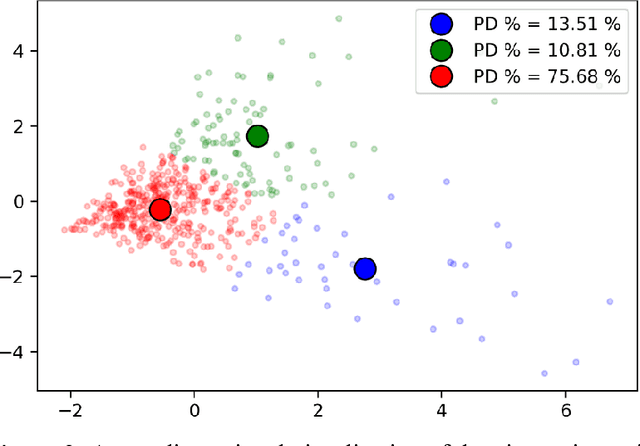
One of the symptoms of Parkinson's disease (PD) is hypomimia or reduced facial expressions. In this paper, we present a digital biomarker for PD that utilizes the study of micro-expressions. We analyzed the facial action units (AU) from 1812 videos of 604 individuals (61 with PD and 543 without PD, mean age 63.9 yo, sd 7.8 ) collected online using a web-based tool (www.parktest.net). In these videos, participants were asked to make three facial expressions (a smiling, disgusted, and surprised face) followed by a neutral face. Using techniques from computer vision and machine learning, we objectively measured the variance of the facial muscle movements and used it to distinguish between individuals with and without PD. The prediction accuracy using the facial micro-expressions was comparable to those methodologies that utilize motor symptoms. Logistic regression analysis revealed that participants with PD had less variance in AU6 (cheek raiser), AU12 (lip corner puller), and AU4 (brow lowerer) than non-PD individuals. An automated classifier using Support Vector Machine was trained on the variances and achieved 95.6% accuracy. Using facial expressions as a biomarker for PD could be potentially transformative for patients in need of physical separation (e.g., due to COVID) or are immobile.
Detecting Parkinson's Disease from Speech-task in an accessible and interpretable manner
Sep 02, 2020



Every nine minutes a person is diagnosed with Parkinson's Disease (PD) in the United States. However, studies have shown that between 25 and 80\% of individuals with Parkinson's Disease (PD) remain undiagnosed. An online, in the wild audio recording application has the potential to help screen for the disease if risk can be accurately assessed. In this paper, we collect data from 726 unique subjects (262 PD and 464 Non-PD) uttering the "quick brown fox jumps over the lazy dog ...." to conduct automated PD assessment. We extracted both standard acoustic features and deep learning based embedding features from the speech data and trained several machine learning algorithms on them. Our models achieved 0.75 AUC by modeling the standard acoustic features through the XGBoost model. We also provide explanation behind our model's decision and show that it is focusing mostly on the widely used MFCC features and a subset of dysphonia features previously used for detecting PD from verbal phonation task.