 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial expressions can detect Parkinson's disease: preliminary evidence from videos collected online
Dec 09, 2020
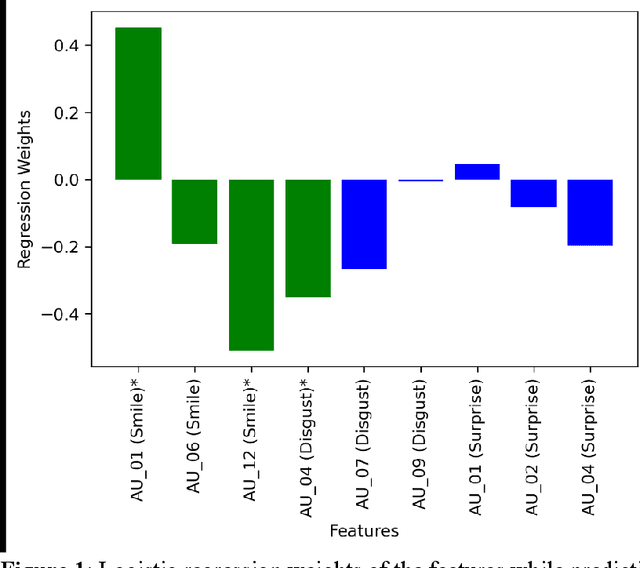
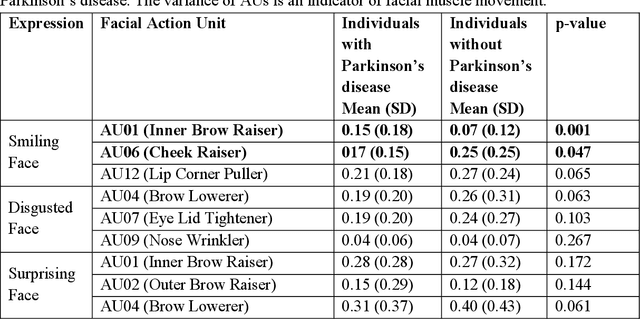
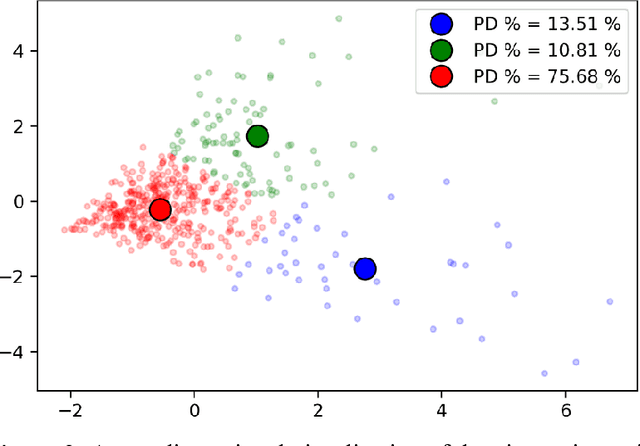
One of the symptoms of Parkinson's disease (PD) is hypomimia or reduced facial expressions. In this paper, we present a digital biomarker for PD that utilizes the study of micro-expressions. We analyzed the facial action units (AU) from 1812 videos of 604 individuals (61 with PD and 543 without PD, mean age 63.9 yo, sd 7.8 ) collected online using a web-based tool (www.parktest.net). In these videos, participants were asked to make three facial expressions (a smiling, disgusted, and surprised face) followed by a neutral face. Using techniques from computer vision and machine learning, we objectively measured the variance of the facial muscle movements and used it to distinguish between individuals with and without PD. The prediction accuracy using the facial micro-expressions was comparable to those methodologies that utilize motor symptoms. Logistic regression analysis revealed that participants with PD had less variance in AU6 (cheek raiser), AU12 (lip corner puller), and AU4 (brow lowerer) than non-PD individuals. An automated classifier using Support Vector Machine was trained on the variances and achieved 95.6% accuracy. Using facial expressions as a biomarker for PD could be potentially transformative for patients in need of physical separation (e.g., due to COVID) or are immobile.
Detecting Parkinson's Disease from Speech-task in an accessible and interpretable manner
Sep 02, 2020



Every nine minutes a person is diagnosed with Parkinson's Disease (PD) in the United States. However, studies have shown that between 25 and 80\% of individuals with Parkinson's Disease (PD) remain undiagnosed. An online, in the wild audio recording application has the potential to help screen for the disease if risk can be accurately assessed. In this paper, we collect data from 726 unique subjects (262 PD and 464 Non-PD) uttering the "quick brown fox jumps over the lazy dog ...." to conduct automated PD assessment. We extracted both standard acoustic features and deep learning based embedding features from the speech data and trained several machine learning algorithms on them. Our models achieved 0.75 AUC by modeling the standard acoustic features through the XGBoost model. We also provide explanation behind our model's decision and show that it is focusing mostly on the widely used MFCC features and a subset of dysphonia features previously used for detecting PD from verbal phonation task.
Discourse Behavior of Older Adults Interacting With a Dialogue Agent Competent in Multiple Topics
Jul 14, 2019
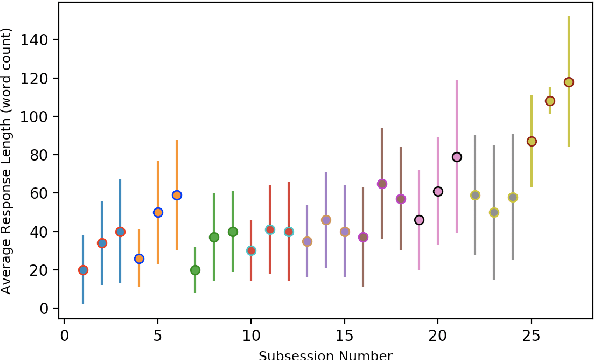

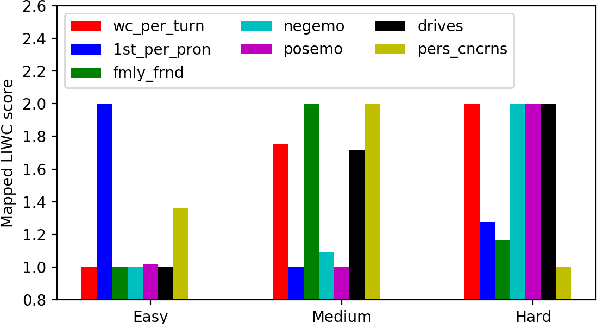
We present some results concerning the dialogue behavior and inferred sentiment of a group of older adults interacting with a computer-based avatar. Our avatar is unique in its ability to hold natural dialogues on a wide range of everyday topics---27 topics in three groups, developed with the help of gerontologists. The three groups vary in ``degrees of intimacy", and as such in degrees of difficulty for the user. Each participant interacted with the avatar for 7-9 sessions over a period of 3-4 weeks; analysis of the dialogues reveals correlations such as greater verbosity for more difficult topics, increasing verbosity with successive sessions, especially for more difficult topics, stronger sentiment on topics concerned with life goals rather than routine activities, and stronger self-disclosure for more intimate topics. In addition to their intrinsic interest, these results also reflect positively on the sophistication of our dialogue system.
Are you really looking at me? A Framework for Extracting Interpersonal Eye Gaze from Conventional Video
Jun 21, 2019
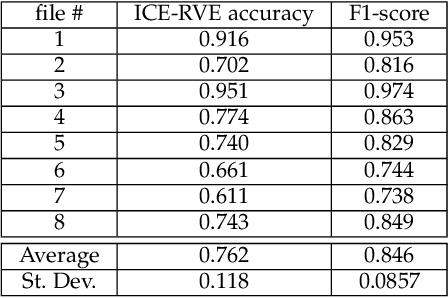


Despite a revolution in the pervasiveness of video cameras in our daily lives, one of the most meaningful forms of nonverbal affective communication, interpersonal eye gaze, i.e. eye gaze relative to a conversation partner, is not available from common video. We introduce the Interpersonal-Calibrating Eye-gaze Encoder (ICE), which automatically extracts interpersonal gaze from video recordings without specialized hardware and without prior knowledge of participant locations. Leveraging the intuition that individuals spend a large portion of a conversation looking at each other enables the ICE dynamic clustering algorithm to extract interpersonal gaze. We validate ICE in both video chat using an objective metric with an infrared gaze tracker (F1=0.846, N=8), as well as in face-to-face communication with expert-rated evaluations of eye contact (r= 0.37, N=170). We then use ICE to analyze behavior in two different, yet important affective communication domains: interrogation-based deception detection, and communication skill assessment in speed dating. We find that honest witnesses break interpersonal gaze contact and look down more often than deceptive witnesses when answering questions (p=0.004, d=0.79). In predicting expert communication skill ratings in speed dating videos, we demonstrate that interpersonal gaze alone has more predictive power than facial expressions.
Dialogue Design and Management for Multi-Session Casual Conversation with Older Adults
Jan 20, 2019
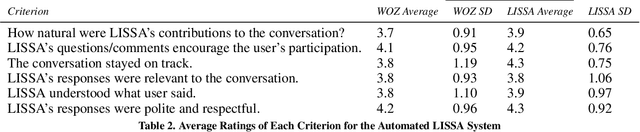
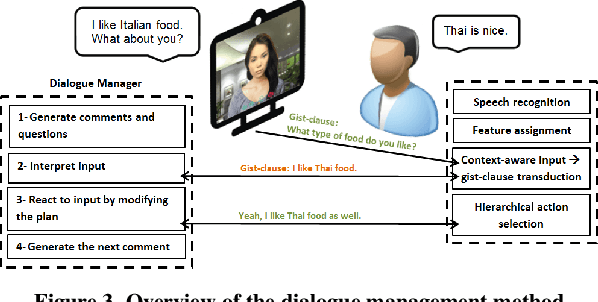
We address the problem of designing a conversational avatar capable of a sequence of casual conversations with older adults. Users at risk of loneliness, social anxiety or a sense of ennui may benefit from practicing such conversations in private, at their convenience. We describe an automatic spoken dialogue manager for LISSA, an on-screen virtual agent that can keep older users involved in conversations over several sessions, each lasting 10-20 minutes. The idea behind LISSA is to improve users' communication skills by providing feedback on their non-verbal behavior at certain points in the course of the conversations. In this paper, we analyze the dialogues collected from the first session between LISSA and each of 8 participants. We examine the quality of the conversations by comparing the transcripts with those collected in a WOZ setting. LISSA's contributions to the conversations were judged by research assistants who rated the extent to which the contributions were "natural", "on track", "encouraging", "understanding", "relevant", and "polite". The results show that the automatic dialogue manager was able to handle conversation with the users smoothly and naturally.