 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-BERT: Injecting Multimodal Information in the BERT Structure
Aug 15, 2019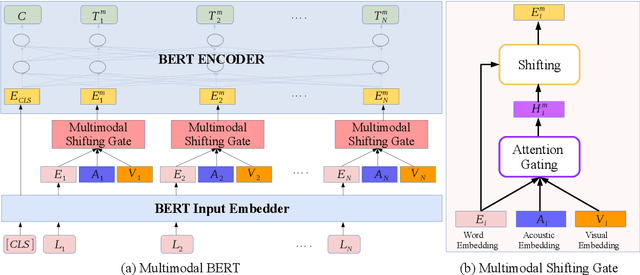
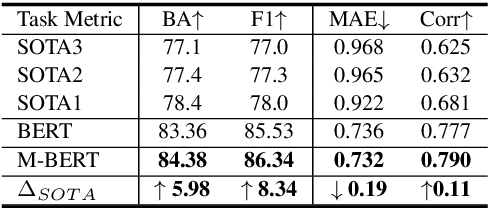
Multimodal language analysis is an emerging research area in natural language processing that models language in a multimodal manner. It aims to understand language from the modalities of text, visual, and acoustic by modeling both intra-modal and cross-modal interactions. BERT (Bidirectional Encoder Representations from Transformers) provides strong contextual language representations after training on large-scale unlabeled corpora. Fine-tuning the vanilla BERT model has shown promising results in building state-of-the-art models for diverse NLP tasks like question answering and language inference. However, fine-tuning BERT in the presence of information from other modalities remains an open research problem. In this paper, we inject multimodal information within the input space of BERT network for modeling multimodal language. The proposed injection method allows BERT to reach a new state of the art of $84.38\%$ binary accuracy on CMU-MOSI dataset (multimodal sentiment analysis) with a gap of 5.98 percent to the previous state of the art and 1.02 percent to the text-only BERT.
Are you really looking at me? A Framework for Extracting Interpersonal Eye Gaze from Conventional Video
Jun 21, 2019
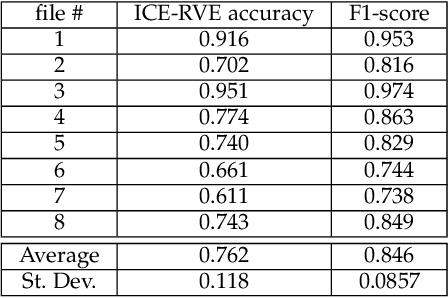


Despite a revolution in the pervasiveness of video cameras in our daily lives, one of the most meaningful forms of nonverbal affective communication, interpersonal eye gaze, i.e. eye gaze relative to a conversation partner, is not available from common video. We introduce the Interpersonal-Calibrating Eye-gaze Encoder (ICE), which automatically extracts interpersonal gaze from video recordings without specialized hardware and without prior knowledge of participant locations. Leveraging the intuition that individuals spend a large portion of a conversation looking at each other enables the ICE dynamic clustering algorithm to extract interpersonal gaze. We validate ICE in both video chat using an objective metric with an infrared gaze tracker (F1=0.846, N=8), as well as in face-to-face communication with expert-rated evaluations of eye contact (r= 0.37, N=170). We then use ICE to analyze behavior in two different, yet important affective communication domains: interrogation-based deception detection, and communication skill assessment in speed dating. We find that honest witnesses break interpersonal gaze contact and look down more often than deceptive witnesses when answering questions (p=0.004, d=0.79). In predicting expert communication skill ratings in speed dating videos, we demonstrate that interpersonal gaze alone has more predictive power than facial expressions.