 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-BERT: Injecting Multimodal Information in the BERT Structure
Paper and Code
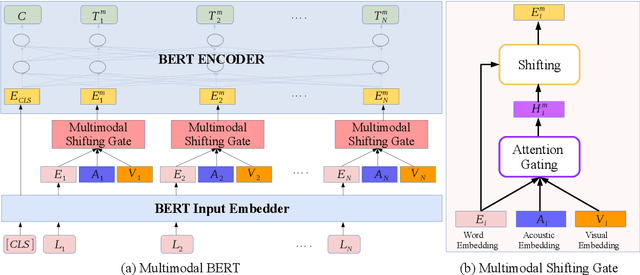
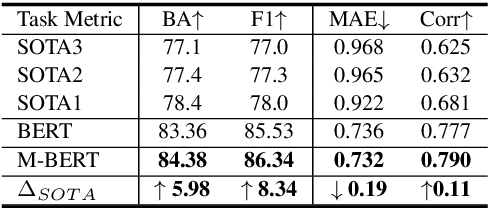
Multimodal language analysis is an emerging research area in natural language processing that models language in a multimodal manner. It aims to understand language from the modalities of text, visual, and acoustic by modeling both intra-modal and cross-modal interactions. BERT (Bidirectional Encoder Representations from Transformers) provides strong contextual language representations after training on large-scale unlabeled corpora. Fine-tuning the vanilla BERT model has shown promising results in building state-of-the-art models for diverse NLP tasks like question answering and language inference. However, fine-tuning BERT in the presence of information from other modalities remains an open research problem. In this paper, we inject multimodal information within the input space of BERT network for modeling multimodal language. The proposed injection method allows BERT to reach a new state of the art of $84.38\%$ binary accuracy on CMU-MOSI dataset (multimodal sentiment analysis) with a gap of 5.98 percent to the previous state of the art and 1.02 percent to the text-only BERT.