 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Symbolic Solving: Multi Chain-of-Thought Voting for Geometric Reasoning in Large Language Models
Apr 01, 2026Geometric Problem Solving (GPS) remains at the heart of enhancing mathematical reasoning in large language models because it requires the combination of diagrammatic understanding, symbolic manipulation and logical inference. In existing literature, researchers have chiefly focused on synchronising the diagram descriptions with text literals and solving the problem. In this vein, they have either taken a neural, symbolic or neuro-symbolic approach. But this solves only the first two of the requirements, namely diagrammatic understanding and symbolic manipulation, while leaving logical inference underdeveloped. The logical inference is often limited to one chain-of-thought (CoT). To address this weakness in hitherto existing models, this paper proposes MARS-GPS, that generates multiple parallel reasoning rollouts augmented with Python code execution for numerical verification, ranks them using token-level entropy as a confidence signal, and aggregates answers through a multi-stage voting and self-verification pipeline. Empirical results show that MARS-GPS with 8 parallel rollouts achieves 88.8% on Geometry3K, a nearly +11% improvement over the prior state-of-the-art, with accuracy scaling consistently as the number of rollouts increases from 1 to 16 (+6.0% on ablation subset). We provide our code and data in an anonymous repository: https://anonymous.4open.science/r/MARS-GPS-DE55.
Courtroom-Style Multi-Agent Debate with Progressive RAG and Role-Switching for Controversial Claim Verification
Mar 30, 2026Large language models (LLMs) remain unreliable for high-stakes claim verification due to hallucinations and shallow reasoning. While retrieval-augmented generation (RAG) and multi-agent debate (MAD) address this, they are limited by one-pass retrieval and unstructured debate dynamics. We propose a courtroom-style multi-agent framework, PROClaim, that reformulates verification as a structured, adversarial deliberation. Our approach integrates specialized roles (e.g., Plaintiff, Defense, Judge) with Progressive RAG (P-RAG) to dynamically expand and refine the evidence pool during the debate. Furthermore, we employ evidence negotiation, self-reflection, and heterogeneous multi-judge aggregation to enforce calibration, robustness, and diversity. In zero-shot evaluations on the Check-COVID benchmark, PROClaim achieves 81.7% accuracy, outperforming standard multi-agent debate by 10.0 percentage points, with P-RAG driving the primary performance gains (+7.5 pp). We ultimately demonstrate that structural deliberation and model heterogeneity effectively mitigate systematic biases, providing a robust foundation for reliable claim verification. Our code and data are publicly available at https://github.com/mnc13/PROClaim.
BanglaLorica: Design and Evaluation of a Robust Watermarking Algorithm for Large Language Models in Bangla Text Generation
Jan 08, 2026As large language models (LLMs) are increasingly deployed for text generation, watermarking has become essential for authorship attribution, intellectual property protection, and misuse detection. While existing watermarking methods perform well in high-resource languages, their robustness in low-resource languages remains underexplored. This work presents the first systematic evaluation of state-of-the-art text watermarking methods: KGW, Exponential Sampling (EXP), and Waterfall, for Bangla LLM text generation under cross-lingual round-trip translation (RTT) attacks. Under benign conditions, KGW and EXP achieve high detection accuracy (>88%) with negligible perplexity and ROUGE degradation. However, RTT causes detection accuracy to collapse below RTT causes detection accuracy to collapse to 9-13%, indicating a fundamental failure of token-level watermarking. To address this, we propose a layered watermarking strategy that combines embedding-time and post-generation watermarks. Experimental results show that layered watermarking improves post-RTT detection accuracy by 25-35%, achieving 40-50% accuracy, representing a 3$\times$ to 4$\times$ relative improvement over single-layer methods, at the cost of controlled semantic degradation. Our findings quantify the robustness-quality trade-off in multilingual watermarking and establish layered watermarking as a practical, training-free solution for low-resource languages such as Bangla. Our code and data will be made public.
PhysicsEval: Inference-Time Techniques to Improve the Reasoning Proficiency of Large Language Models on Physics Problems
Jul 31, 2025



The discipline of physics stands as a cornerstone of human intellect, driving the evolution of technology and deepening our understanding of the fundamental principles of the cosmos. Contemporary literature includes some works centered on the task of solving physics problems - a crucial domain of natural language reasoning. In this paper, we evaluate the performance of frontier LLMs in solving physics problems, both mathematical and descriptive. We also employ a plethora of inference-time techniques and agentic frameworks to improve the performance of the models. This includes the verification of proposed solutions in a cumulative fashion by other, smaller LLM agents, and we perform a comparative analysis of the performance that the techniques entail. There are significant improvements when the multi-agent framework is applied to problems that the models initially perform poorly on. Furthermore, we introduce a new evaluation benchmark for physics problems, ${\rm P{\small HYSICS}E{\small VAL}}$, consisting of 19,609 problems sourced from various physics textbooks and their corresponding correct solutions scraped from physics forums and educational websites. Our code and data are publicly available at https://github.com/areebuzair/PhysicsEval.
BdSLW401: Transformer-Based Word-Level Bangla Sign Language Recognition Using Relative Quantization Encoding (RQE)
Mar 04, 2025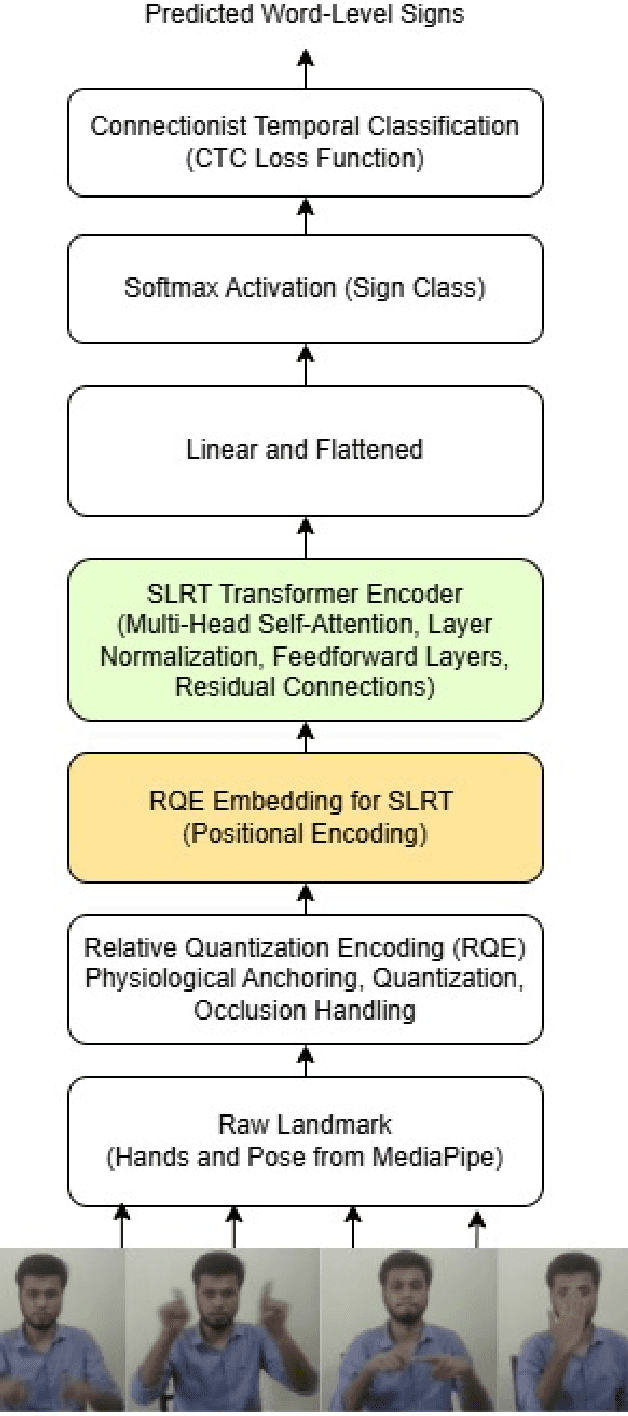
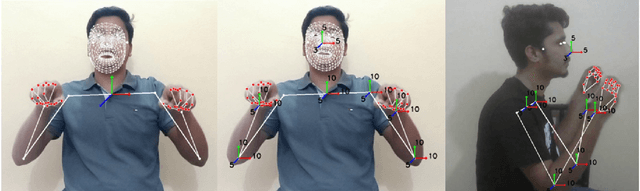
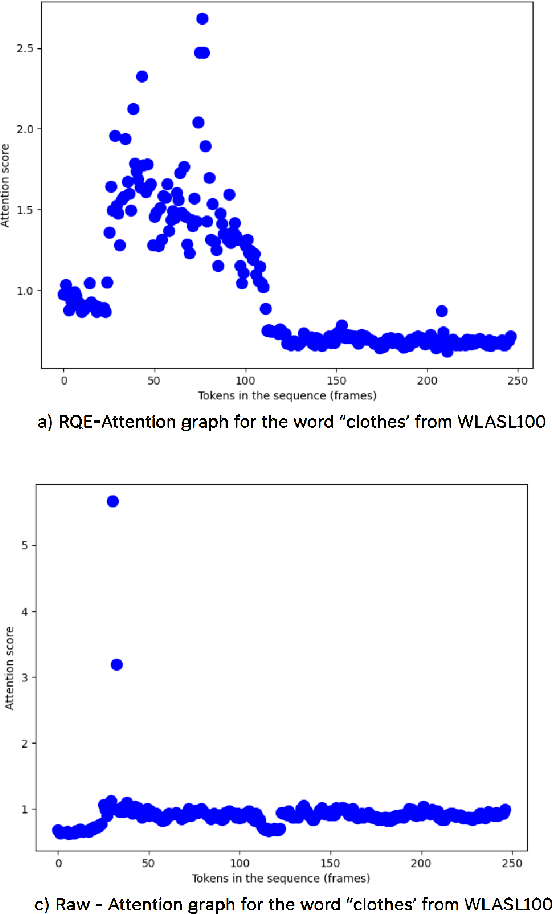

Sign language recognition (SLR) for low-resource languages like Bangla suffers from signer variability, viewpoint variations, and limited annotated datasets. In this paper, we present BdSLW401, a large-scale, multi-view, word-level Bangla Sign Language (BdSL) dataset with 401 signs and 102,176 video samples from 18 signers in front and lateral views. To improve transformer-based SLR, we introduce Relative Quantization Encoding (RQE), a structured embedding approach anchoring landmarks to physiological reference points and quantize motion trajectories. RQE improves attention allocation by decreasing spatial variability, resulting in 44.3% WER reduction in WLASL100, 21.0% in SignBD-200, and significant gains in BdSLW60 and SignBD-90. However, fixed quantization becomes insufficient on large-scale datasets (e.g., WLASL2000), indicating the need for adaptive encoding strategies. Further, RQE-SF, an extended variant that stabilizes shoulder landmarks, achieves improvements in pose consistency at the cost of small trade-offs in lateral view recognition. The attention graphs prove that RQE improves model interpretability by focusing on the major articulatory features (fingers, wrists) and the more distinctive frames instead of global pose changes. Introducing BdSLW401 and demonstrating the effectiveness of RQE-enhanced structured embeddings, this work advances transformer-based SLR for low-resource languages and sets a benchmark for future research in this area.
BDA: Bangla Text Data Augmentation Framework
Dec 11, 2024



Data augmentation involves generating synthetic samples that resemble those in a given dataset. In resource-limited fields where high-quality data is scarce, augmentation plays a crucial role in increasing the volume of training data. This paper introduces a Bangla Text Data Augmentation (BDA) Framework that uses both pre-trained models and rule-based methods to create new variants of the text. A filtering process is included to ensure that the new text keeps the same meaning as the original while also adding variety in the words used. We conduct a comprehensive evaluation of the framework's effectiveness in Bangla text classification tasks. Our framework achieved significant improvement in F1 scores across five distinct datasets, delivering performance equivalent to models trained on 100\% of the data while utilizing only 50\% of the training dataset. Additionally, we explore the impact of data scarcity by progressively reducing the training data and augmenting it through BDA, resulting in notable F1 score enhancements. The study offers a thorough examination of BDA's performance, identifying key factors for optimal results and addressing its limitations through detailed analysis.
Math Word Problem Solving by Generating Linguistic Variants of Problem Statements
Jun 24, 2023



The art of mathematical reasoning stands as a fundamental pillar of intellectual progress and is a central catalyst in cultivating human ingenuity. Researchers have recently published a plethora of works centered around the task of solving Math Word Problems (MWP) $-$ a crucial stride towards general AI. These existing models are susceptible to dependency on shallow heuristics and spurious correlations to derive the solution expressions. In order to ameliorate this issue, in this paper, we propose a framework for MWP solvers based on the generation of linguistic variants of the problem text. The approach involves solving each of the variant problems and electing the predicted expression with the majority of the votes. We use DeBERTa (Decoding-enhanced BERT with disentangled attention) as the encoder to leverage its rich textual representations and enhanced mask decoder to construct the solution expressions. Furthermore, we introduce a challenging dataset, $\mathrm{P\small{ARA}\normalsize{MAWPS}}$, consisting of paraphrased, adversarial, and inverse variants of selectively sampled MWPs from the benchmark $\mathrm{M\small{AWPS}}$ dataset. We extensively experiment on this dataset along with other benchmark datasets using some baseline MWP solver models. We show that training on linguistic variants of problem statements and voting on candidate predictions improve the mathematical reasoning and robustness of the model. We make our code and data publicly available.
BanglaBook: A Large-scale Bangla Dataset for Sentiment Analysis from Book Reviews
May 26, 2023



The analysis of consumer sentiment, as expressed through reviews, can provide a wealth of insight regarding the quality of a product. While the study of sentiment analysis has been widely explored in many popular languages, relatively less attention has been given to the Bangla language, mostly due to a lack of relevant data and cross-domain adaptability. To address this limitation, we present BanglaBook, a large-scale dataset of Bangla book reviews consisting of 158,065 samples classified into three broad categories: positive, negative, and neutral. We provide a detailed statistical analysis of the dataset and employ a range of machine learning models to establish baselines including SVM, LSTM, and Bangla-BERT. Our findings demonstrate a substantial performance advantage of pre-trained models over models that rely on manually crafted features, emphasizing the necessity for additional training resources in this domain. Additionally, we conduct an in-depth error analysis by examining sentiment unigrams, which may provide insight into common classification errors in under-resourced languages like Bangla. Our codes and data are publicly available at https://github.com/mohsinulkabir14/BanglaBook.
Venn Diagram Multi-label Class Interpretation of Diabetic Foot Ulcer with Color and Sharpness Enhancement
May 05, 2023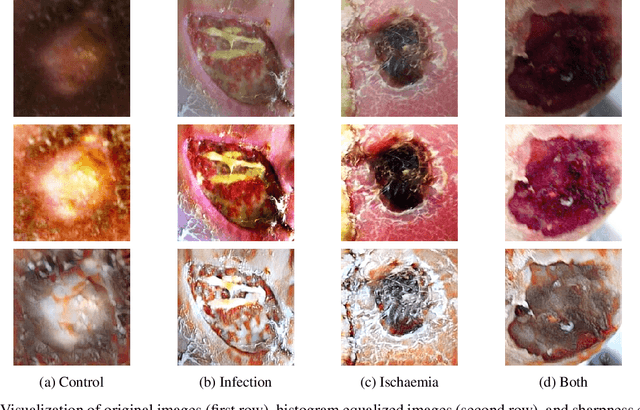
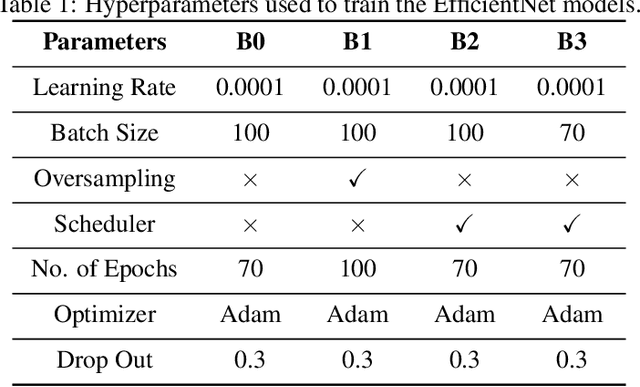
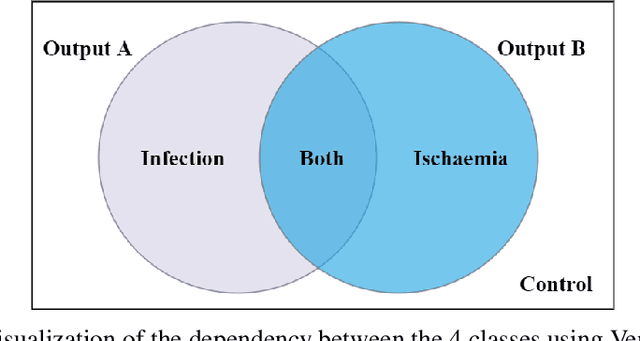
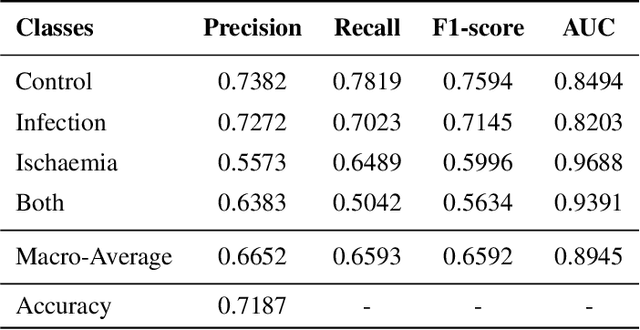
DFU is a severe complication of diabetes that can lead to amputation of the lower limb if not treated properly. Inspired by the 2021 Diabetic Foot Ulcer Grand Challenge, researchers designed automated multi-class classification of DFU, including infection, ischaemia, both of these conditions, and none of these conditions. However, it remains a challenge as classification accuracy is still not satisfactory. This paper proposes a Venn Diagram interpretation of multi-label CNN-based method, utilizing different image enhancement strategies, to improve the multi-class DFU classification. We propose to reduce the four classes into two since both class wounds can be interpreted as the simultaneous occurrence of infection and ischaemia and none class wounds as the absence of infection and ischaemia. We introduce a novel Venn Diagram representation block in the classifier to interpret all four classes from these two classes. To make our model more resilient, we propose enhancing the perceptual quality of DFU images, particularly blurry or inconsistently lit DFU images, by performing color and sharpness enhancements on them. We also employ a fine-tuned optimization technique, adaptive sharpness aware minimization, to improve the CNN model generalization performance. The proposed method is evaluated on the test dataset of DFUC2021, containing 5,734 images and the results are compared with the top-3 winning entries of DFUC2021. Our proposed approach outperforms these existing approaches and achieves Macro-Average F1, Recall and Precision scores of 0.6592, 0.6593, and 0.6652, respectively.Additionally, We perform ablation studies and image quality measurements to further interpret our proposed method. This proposed method will benefit patients with DFUs since it tackles the inconsistencies in captured images and can be employed for a more robust remote DFU wound classification.
TextMI: Textualize Multimodal Information for Integrating Non-verbal Cues in Pre-trained Language Models
Mar 29, 2023Pre-trained large language models have recently achieved ground-breaking performance in a wide variety of language understanding tasks. However, the same model can not be applied to multimodal behavior understanding tasks (e.g., video sentiment/humor detection) unless non-verbal features (e.g., acoustic and visual) can be integrated with language. Jointly modeling multiple modalities significantly increases the model complexity, and makes the training process data-hungry. While an enormous amount of text data is available via the web, collecting large-scale multimodal behavioral video datasets is extremely expensive, both in terms of time and money. In this paper, we investigate whether large language models alone can successfully incorporate non-verbal information when they are presented in textual form. We present a way to convert the acoustic and visual information into corresponding textual descriptions and concatenate them with the spoken text. We feed this augmented input to a pre-trained BERT model and fine-tune it on three downstream multimodal tasks: sentiment, humor, and sarcasm detection. Our approach, TextMI, significantly reduces model complexity, adds interpretability to the model's decision, and can be applied for a diverse set of tasks while achieving superior (multimodal sarcasm detection) or near SOTA (multimodal sentiment analysis and multimodal humor detection) performance. We propose TextMI as a general, competitive baseline for multimodal behavioral analysis tasks, particularly in a low-resource setting.