 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
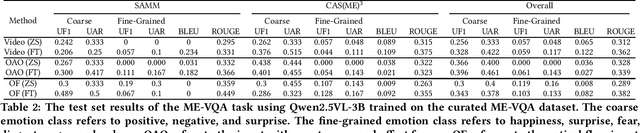
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
Gaussian Random Fields as an Abstract Representation of Patient Metadata for Multimodal Medical Image Segmentation
Mar 07, 2025The growing rate of chronic wound occurrence, especially in patients with diabetes, has become a concerning trend in recent years. Chronic wounds are difficult and costly to treat, and have become a serious burden on health care systems worldwide. Chronic wounds can have devastating consequences for the patient, with infection often leading to reduced quality of life and increased mortality risk. Innovative deep learning methods for the detection and monitoring of such wounds have the potential to reduce the impact to both patient and clinician. We present a novel multimodal segmentation method which allows for the introduction of patient metadata into the training workflow whereby the patient data are expressed as Gaussian random fields. Our results indicate that the proposed method improved performance when utilising multiple models, each trained on different metadata categories. Using the Diabetic Foot Ulcer Challenge 2022 test set, when compared to the baseline results (intersection over union = 0.4670, Dice similarity coefficient = 0.5908) we demonstrate improvements of +0.0220 and +0.0229 for intersection over union and Dice similarity coefficient respectively. This paper presents the first study to focus on integrating patient data into a chronic wound segmentation workflow. Our results show significant performance gains when training individual models using specific metadata categories, followed by average merging of prediction masks using distance transforms. All source code for this study is available at: https://github.com/mmu-dermatology-research/multimodal-grf
An Enhanced Harmonic Densely Connected Hybrid Transformer Network Architecture for Chronic Wound Segmentation Utilising Multi-Colour Space Tensor Merging
Oct 04, 2024



Chronic wounds and associated complications present ever growing burdens for clinics and hospitals world wide. Venous, arterial, diabetic, and pressure wounds are becoming increasingly common globally. These conditions can result in highly debilitating repercussions for those affected, with limb amputations and increased mortality risk resulting from infection becoming more common. New methods to assist clinicians in chronic wound care are therefore vital to maintain high quality care standards. This paper presents an improved HarDNet segmentation architecture which integrates a contrast-eliminating component in the initial layers of the network to enhance feature learning. We also utilise a multi-colour space tensor merging process and adjust the harmonic shape of the convolution blocks to facilitate these additional features. We train our proposed model using wound images from light-skinned patients and test the model on two test sets (one set with ground truth, and one without) comprising only darker-skinned cases. Subjective ratings are obtained from clinical wound experts with intraclass correlation coefficient used to determine inter-rater reliability. For the dark-skin tone test set with ground truth, we demonstrate improvements in terms of Dice similarity coefficient (+0.1221) and intersection over union (+0.1274). Qualitative analysis showed high expert ratings, with improvements of >3% demonstrated when comparing the baseline model with the proposed model. This paper presents the first study to focus on darker-skin tones for chronic wound segmentation using models trained only on wound images exhibiting lighter skin. Diabetes is highly prevalent in countries where patients have darker skin tones, highlighting the need for a greater focus on such cases. Additionally, we conduct the largest qualitative study to date for chronic wound segmentation.
Dermoscopic Dark Corner Artifacts Removal: Friend or Foe?
Jun 23, 2023



One of the more significant obstacles in classification of skin cancer is the presence of artifacts. This paper investigates the effect of dark corner artifacts, which result from the use of dermoscopes, on the performance of a deep learning binary classification task. Previous research attempted to remove and inpaint dark corner artifacts, with the intention of creating an ideal condition for models. However, such research has been shown to be inconclusive due to lack of available datasets labelled with dark corner artifacts and detailed analysis and discussion. To address these issues, we label 10,250 skin lesion images from publicly available datasets and introduce a balanced dataset with an equal number of melanoma and non-melanoma cases. The training set comprises 6126 images without artifacts, and the testing set comprises 4124 images with dark corner artifacts. We conduct three experiments to provide new understanding on the effects of dark corner artifacts, including inpainted and synthetically generated examples, on a deep learning method. Our results suggest that introducing synthetic dark corner artifacts which have been superimposed onto the training set improved model performance, particularly in terms of the true negative rate. This indicates that deep learning learnt to ignore dark corner artifacts, rather than treating it as melanoma, when dark corner artifacts were introduced into the training set. Further, we propose a new approach to quantifying heatmaps indicating network focus using a root mean square measure of the brightness intensity in the different regions of the heatmaps. This paper provides a new guideline for skin lesions analysis with an emphasis on reproducibility.
Venn Diagram Multi-label Class Interpretation of Diabetic Foot Ulcer with Color and Sharpness Enhancement
May 05, 2023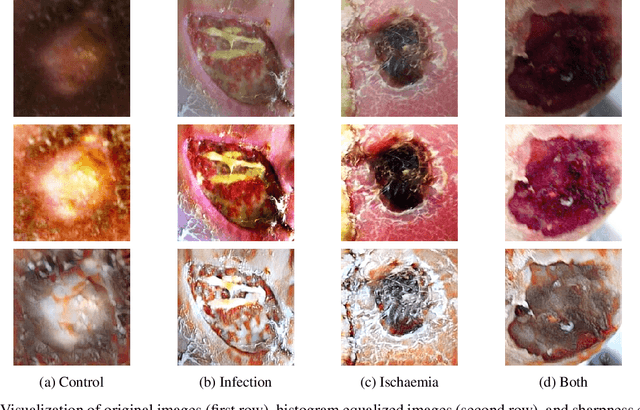
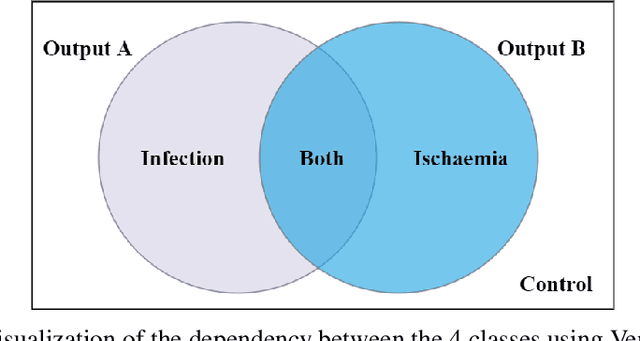
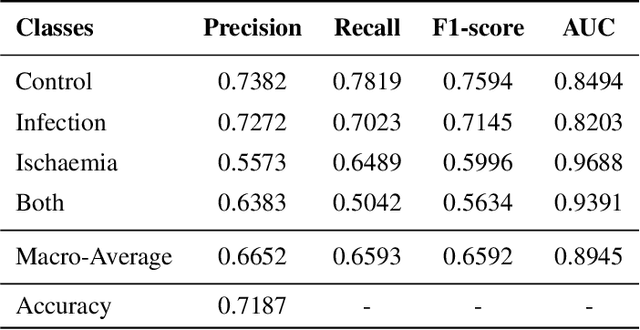
DFU is a severe complication of diabetes that can lead to amputation of the lower limb if not treated properly. Inspired by the 2021 Diabetic Foot Ulcer Grand Challenge, researchers designed automated multi-class classification of DFU, including infection, ischaemia, both of these conditions, and none of these conditions. However, it remains a challenge as classification accuracy is still not satisfactory. This paper proposes a Venn Diagram interpretation of multi-label CNN-based method, utilizing different image enhancement strategies, to improve the multi-class DFU classification. We propose to reduce the four classes into two since both class wounds can be interpreted as the simultaneous occurrence of infection and ischaemia and none class wounds as the absence of infection and ischaemia. We introduce a novel Venn Diagram representation block in the classifier to interpret all four classes from these two classes. To make our model more resilient, we propose enhancing the perceptual quality of DFU images, particularly blurry or inconsistently lit DFU images, by performing color and sharpness enhancements on them. We also employ a fine-tuned optimization technique, adaptive sharpness aware minimization, to improve the CNN model generalization performance. The proposed method is evaluated on the test dataset of DFUC2021, containing 5,734 images and the results are compared with the top-3 winning entries of DFUC2021. Our proposed approach outperforms these existing approaches and achieves Macro-Average F1, Recall and Precision scores of 0.6592, 0.6593, and 0.6652, respectively.Additionally, We perform ablation studies and image quality measurements to further interpret our proposed method. This proposed method will benefit patients with DFUs since it tackles the inconsistencies in captured images and can be employed for a more robust remote DFU wound classification.
Quantifying the Effect of Image Similarity on Diabetic Foot Ulcer Classification
Apr 25, 2023This research conducts an investigation on the effect of visually similar images within a publicly available diabetic foot ulcer dataset when training deep learning classification networks. The presence of binary-identical duplicate images in datasets used to train deep learning algorithms is a well known issue that can introduce unwanted bias which can degrade network performance. However, the effect of visually similar non-identical images is an under-researched topic, and has so far not been investigated in any diabetic foot ulcer studies. We use an open-source fuzzy algorithm to identify groups of increasingly similar images in the Diabetic Foot Ulcers Challenge 2021 (DFUC2021) training dataset. Based on each similarity threshold, we create new training sets that we use to train a range of deep learning multi-class classifiers. We then evaluate the performance of the best performing model on the DFUC2021 test set. Our findings show that the model trained on the training set with the 80\% similarity threshold images removed achieved the best performance using the InceptionResNetV2 network. This model showed improvements in F1-score, precision, and recall of 0.023, 0.029, and 0.013, respectively. These results indicate that highly similar images can contribute towards the presence of performance degrading bias within the Diabetic Foot Ulcers Challenge 2021 dataset, and that the removal of images that are 80\% similar from the training set can help to boost classification performance.
Diabetic Foot Ulcer Grand Challenge 2022 Summary
Apr 24, 2023The Diabetic Foot Ulcer Challenge 2022 focused on the task of diabetic foot ulcer segmentation, based on the work completed in previous DFU challenges. The challenge provided 4000 images of full-view foot ulcer images together with corresponding delineation of ulcer regions. This paper provides an overview of the challenge, a summary of the methods proposed by the challenge participants, the results obtained from each technique, and a comparison of the challenge results. The best-performing network was a modified HarDNet-MSEG, with a Dice score of 0.7287.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
AAU-net: An Adaptive Attention U-net for Breast Lesions Segmentation in Ultrasound Images
Apr 26, 2022



Various deep learning methods have been proposed to segment breast lesion from ultrasound images. However, similar intensity distributions, variable tumor morphology and blurred boundaries present challenges for breast lesions segmentation, especially for malignant tumors with irregular shapes. Considering the complexity of ultrasound images, we develop an adaptive attention U-net (AAU-net) to segment breast lesions automatically and stably from ultrasound images. Specifically, we introduce a hybrid adaptive attention module, which mainly consists of a channel self-attention block and a spatial self-attention block, to replace the traditional convolution operation. Compared with the conventional convolution operation, the design of the hybrid adaptive attention module can help us capture more features under different receptive fields. Different from existing attention mechanisms, the hybrid adaptive attention module can guide the network to adaptively select more robust representation in channel and space dimensions to cope with more complex breast lesions segmentation. Extensive experiments with several state-of-the-art deep learning segmentation methods on three public breast ultrasound datasets show that our method has better performance on breast lesion segmentation. Furthermore, robustness analysis and external experiments demonstrate that our proposed AAU-net has better generalization performance on the segmentation of breast lesions. Moreover, the hybrid adaptive attention module can be flexibly applied to existing network frameworks.