 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Harmonic Densely Connected Hybrid Transformer Network Architecture for Chronic Wound Segmentation Utilising Multi-Colour Space Tensor Merging
Oct 04, 2024



Chronic wounds and associated complications present ever growing burdens for clinics and hospitals world wide. Venous, arterial, diabetic, and pressure wounds are becoming increasingly common globally. These conditions can result in highly debilitating repercussions for those affected, with limb amputations and increased mortality risk resulting from infection becoming more common. New methods to assist clinicians in chronic wound care are therefore vital to maintain high quality care standards. This paper presents an improved HarDNet segmentation architecture which integrates a contrast-eliminating component in the initial layers of the network to enhance feature learning. We also utilise a multi-colour space tensor merging process and adjust the harmonic shape of the convolution blocks to facilitate these additional features. We train our proposed model using wound images from light-skinned patients and test the model on two test sets (one set with ground truth, and one without) comprising only darker-skinned cases. Subjective ratings are obtained from clinical wound experts with intraclass correlation coefficient used to determine inter-rater reliability. For the dark-skin tone test set with ground truth, we demonstrate improvements in terms of Dice similarity coefficient (+0.1221) and intersection over union (+0.1274). Qualitative analysis showed high expert ratings, with improvements of >3% demonstrated when comparing the baseline model with the proposed model. This paper presents the first study to focus on darker-skin tones for chronic wound segmentation using models trained only on wound images exhibiting lighter skin. Diabetes is highly prevalent in countries where patients have darker skin tones, highlighting the need for a greater focus on such cases. Additionally, we conduct the largest qualitative study to date for chronic wound segmentation.
ROCOv2: Radiology Objects in COntext Version 2, an Updated Multimodal Image Dataset
May 16, 2024Automated medical image analysis systems often require large amounts of training data with high quality labels, which are difficult and time consuming to generate. This paper introduces Radiology Object in COntext version 2 (ROCOv2), a multimodal dataset consisting of radiological images and associated medical concepts and captions extracted from the PMC Open Access subset. It is an updated version of the ROCO dataset published in 2018, and adds 35,705 new images added to PMC since 2018. It further provides manually curated concepts for imaging modalities with additional anatomical and directional concepts for X-rays. The dataset consists of 79,789 images and has been used, with minor modifications, in the concept detection and caption prediction tasks of ImageCLEFmedical Caption 2023. The dataset is suitable for training image annotation models based on image-caption pairs, or for multi-label image classification using Unified Medical Language System (UMLS) concepts provided with each image. In addition, it can serve for pre-training of medical domain models, and evaluation of deep learning models for multi-task learning.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Boosting EfficientNets Ensemble Performance via Pseudo-Labels and Synthetic Images by pix2pixHD for Infection and Ischaemia Classification in Diabetic Foot Ulcers
Nov 30, 2021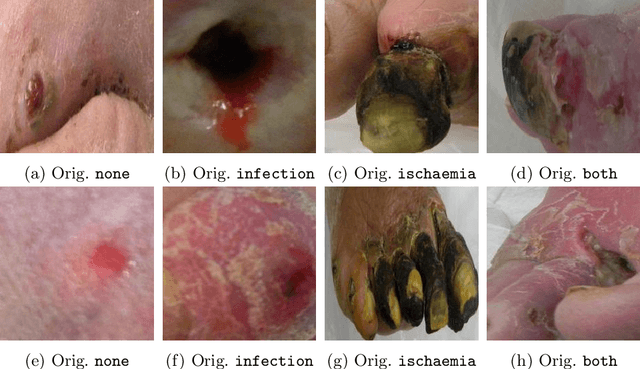
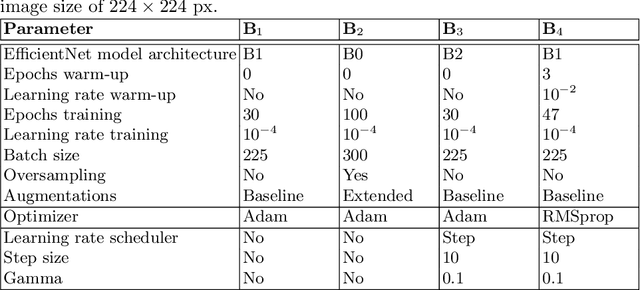
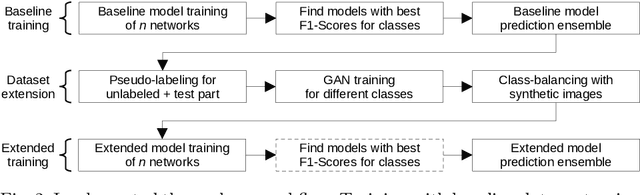
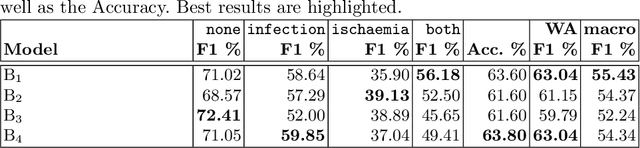
Diabetic foot ulcers are a common manifestation of lesions on the diabetic foot, a syndrome acquired as a long-term complication of diabetes mellitus. Accompanying neuropathy and vascular damage promote acquisition of pressure injuries and tissue death due to ischaemia. Affected areas are prone to infections, hindering the healing progress. The research at hand investigates an approach on classification of infection and ischaemia, conducted as part of the Diabetic Foot Ulcer Challenge (DFUC) 2021. Different models of the EfficientNet family are utilized in ensembles. An extension strategy for the training data is applied, involving pseudo-labeling for unlabeled images, and extensive generation of synthetic images via pix2pixHD to cope with severe class imbalances. The resulting extended training dataset features $8.68$ times the size of the baseline and shows a real to synthetic image ratio of $1:3$. Performances of models and ensembles trained on the baseline and extended training dataset are compared. Synthetic images featured a broad qualitative variety. Results show that models trained on the extended training dataset as well as their ensemble benefit from the large extension. F1-Scores for rare classes receive outstanding boosts, while those for common classes are either not harmed or boosted moderately. A critical discussion concretizes benefits and identifies limitations, suggesting improvements. The work concludes that classification performance of individual models as well as that of ensembles can be boosted utilizing synthetic images. Especially performance for rare classes benefits notably.