 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROCOv2: Radiology Objects in COntext Version 2, an Updated Multimodal Image Dataset
May 16, 2024Automated medical image analysis systems often require large amounts of training data with high quality labels, which are difficult and time consuming to generate. This paper introduces Radiology Object in COntext version 2 (ROCOv2), a multimodal dataset consisting of radiological images and associated medical concepts and captions extracted from the PMC Open Access subset. It is an updated version of the ROCO dataset published in 2018, and adds 35,705 new images added to PMC since 2018. It further provides manually curated concepts for imaging modalities with additional anatomical and directional concepts for X-rays. The dataset consists of 79,789 images and has been used, with minor modifications, in the concept detection and caption prediction tasks of ImageCLEFmedical Caption 2023. The dataset is suitable for training image annotation models based on image-caption pairs, or for multi-label image classification using Unified Medical Language System (UMLS) concepts provided with each image. In addition, it can serve for pre-training of medical domain models, and evaluation of deep learning models for multi-task learning.
Overview of The MediaEval 2022 Predicting Video Memorability Task
Dec 13, 2022This paper describes the 5th edition of the Predicting Video Memorability Task as part of MediaEval2022. This year we have reorganised and simplified the task in order to lubricate a greater depth of inquiry. Similar to last year, two datasets are provided in order to facilitate generalisation, however, this year we have replaced the TRECVid2019 Video-to-Text dataset with the VideoMem dataset in order to remedy underlying data quality issues, and to prioritise short-term memorability prediction by elevating the Memento10k dataset as the primary dataset. Additionally, a fully fledged electroencephalography (EEG)-based prediction sub-task is introduced. In this paper, we outline the core facets of the task and its constituent sub-tasks; describing the datasets, evaluation metrics, and requirements for participant submissions.
Overview of the EEG Pilot Subtask at MediaEval 2021: Predicting Media Memorability
Dec 15, 2021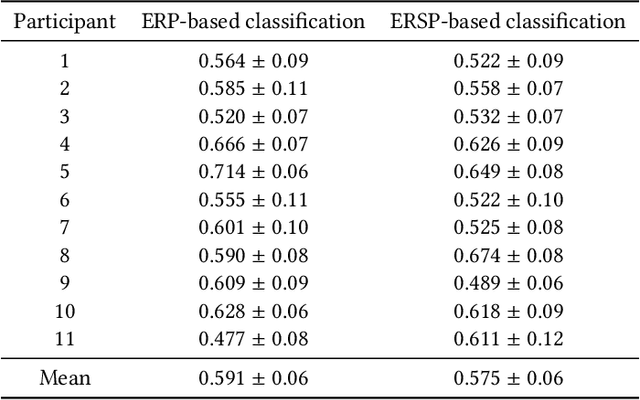
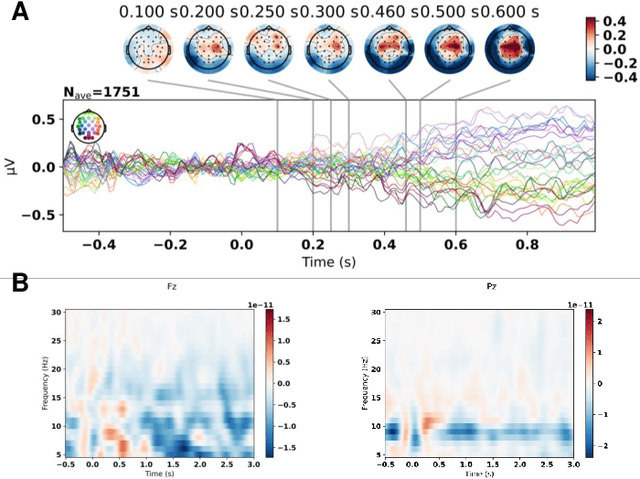
The aim of the Memorability-EEG pilot subtask at MediaEval'2021 is to promote interest in the use of neural signals -- either alone or in combination with other data sources -- in the context of predicting video memorability by highlighting the utility of EEG data. The dataset created consists of pre-extracted features from EEG recordings of subjects while watching a subset of videos from Predicting Media Memorability subtask 1. This demonstration pilot gives interested researchers a sense of how neural signals can be used without any prior domain knowledge, and enables them to do so in a future memorability task. The dataset can be used to support the exploration of novel machine learning and processing strategies for predicting video memorability, while potentially increasing interdisciplinary interest in the subject of memorability, and opening the door to new combined EEG-computer vision approaches.