 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Sentry: Harnessing Ensemble Intelligence for Resilient Detection and Generalisation
Mar 29, 2024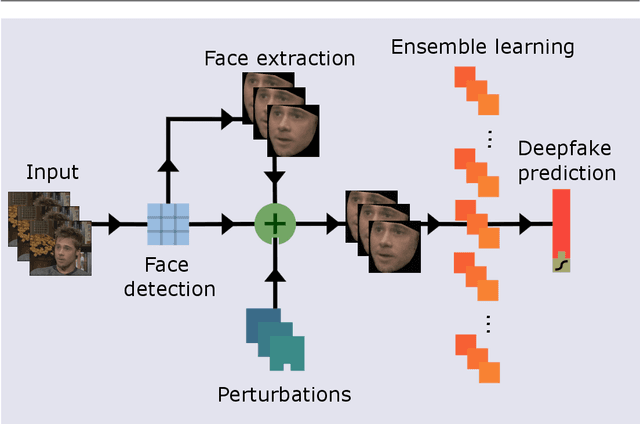
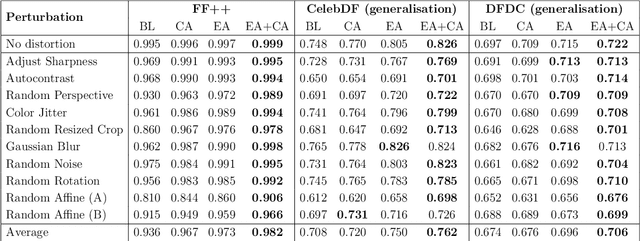
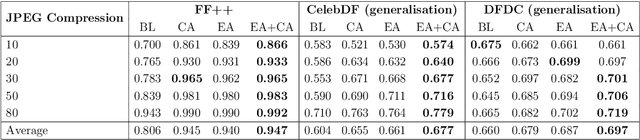

Recent advancements in Generative Adversarial Networks (GANs) have enabled photorealistic image generation with high quality. However, the malicious use of such generated media has raised concerns regarding visual misinformation. Although deepfake detection research has demonstrated high accuracy, it is vulnerable to advances in generation techniques and adversarial iterations on detection countermeasures. To address this, we propose a proactive and sustainable deepfake training augmentation solution that introduces artificial fingerprints into models. We achieve this by employing an ensemble learning approach that incorporates a pool of autoencoders that mimic the effect of the artefacts introduced by the deepfake generator models. Experiments on three datasets reveal that our proposed ensemble autoencoder-based data augmentation learning approach offers improvements in terms of generalisation, resistance against basic data perturbations such as noise, blurring, sharpness enhancement, and affine transforms, resilience to commonly used lossy compression algorithms such as JPEG, and enhanced resistance against adversarial attacks.
Overview of The MediaEval 2022 Predicting Video Memorability Task
Dec 13, 2022This paper describes the 5th edition of the Predicting Video Memorability Task as part of MediaEval2022. This year we have reorganised and simplified the task in order to lubricate a greater depth of inquiry. Similar to last year, two datasets are provided in order to facilitate generalisation, however, this year we have replaced the TRECVid2019 Video-to-Text dataset with the VideoMem dataset in order to remedy underlying data quality issues, and to prioritise short-term memorability prediction by elevating the Memento10k dataset as the primary dataset. Additionally, a fully fledged electroencephalography (EEG)-based prediction sub-task is introduced. In this paper, we outline the core facets of the task and its constituent sub-tasks; describing the datasets, evaluation metrics, and requirements for participant submissions.
Experiences from the MediaEval Predicting Media Memorability Task
Dec 07, 2022


The Predicting Media Memorability task in the MediaEval evaluation campaign has been running annually since 2018 and several different tasks and data sets have been used in this time. This has allowed us to compare the performance of many memorability prediction techniques on the same data and in a reproducible way and to refine and improve on those techniques. The resources created to compute media memorability are now being used by researchers well beyond the actual evaluation campaign. In this paper we present a summary of the task, including the collective lessons we have learned for the research community.
Overview of The MediaEval 2021 Predicting Media Memorability Task
Dec 11, 2021This paper describes the MediaEval 2021 Predicting Media Memorability}task, which is in its 4th edition this year, as the prediction of short-term and long-term video memorability remains a challenging task. In 2021, two datasets of videos are used: first, a subset of the TRECVid 2019 Video-to-Text dataset; second, the Memento10K dataset in order to provide opportunities to explore cross-dataset generalisation. In addition, an Electroencephalography (EEG)-based prediction pilot subtask is introduced. In this paper, we outline the main aspects of the task and describe the datasets, evaluation metrics, and requirements for participants' submissions.
An Annotated Video Dataset for Computing Video Memorability
Dec 04, 2021
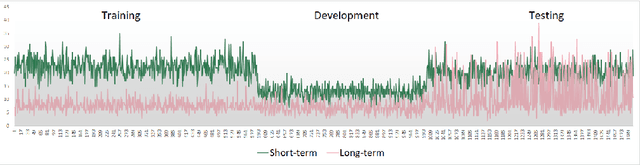
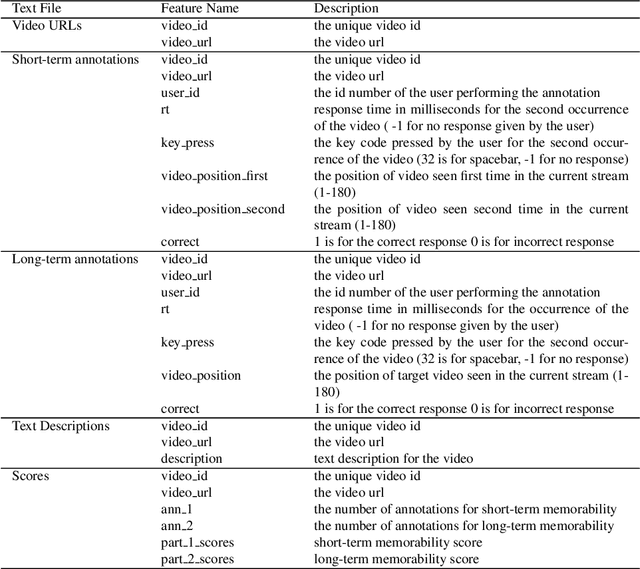
Using a collection of publicly available links to short form video clips of an average of 6 seconds duration each, 1,275 users manually annotated each video multiple times to indicate both long-term and short-term memorability of the videos. The annotations were gathered as part of an online memory game and measured a participant's ability to recall having seen the video previously when shown a collection of videos. The recognition tasks were performed on videos seen within the previous few minutes for short-term memorability and within the previous 24 to 72 hours for long-term memorability. Data includes the reaction times for each recognition of each video. Associated with each video are text descriptions (captions) as well as a collection of image-level features applied to 3 frames extracted from each video (start, middle and end). Video-level features are also provided. The dataset was used in the Video Memorability task as part of the MediaEval benchmark in 2020.
* 11 pages
Face Verification with Challenging Imposters and Diversified Demographics
Oct 16, 2021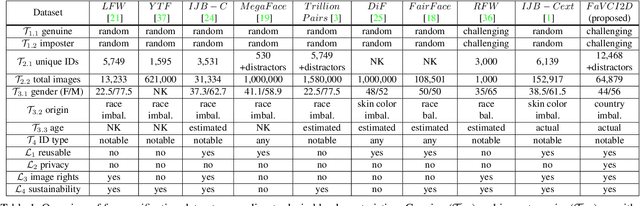

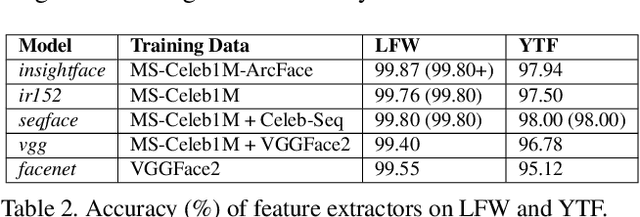
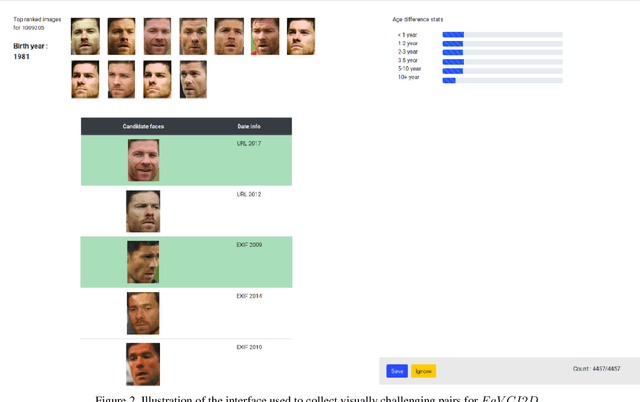
Face verification aims to distinguish between genuine and imposter pairs of faces, which include the same or different identities, respectively. The performance reported in recent years gives the impression that the task is practically solved. Here, we revisit the problem and argue that existing evaluation datasets were built using two oversimplifying design choices. First, the usual identity selection to form imposter pairs is not challenging enough because, in practice, verification is needed to detect challenging imposters. Second, the underlying demographics of existing datasets are often insufficient to account for the wide diversity of facial characteristics of people from across the world. To mitigate these limitations, we introduce the $FaVCI2D$ dataset. Imposter pairs are challenging because they include visually similar faces selected from a large pool of demographically diversified identities. The dataset also includes metadata related to gender, country and age to facilitate fine-grained analysis of results. $FaVCI2D$ is generated from freely distributable resources. Experiments with state-of-the-art deep models that provide nearly 100\% performance on existing datasets show a significant performance drop for $FaVCI2D$, confirming our starting hypothesis. Equally important, we analyze legal and ethical challenges which appeared in recent years and hindered the development of face analysis research. We introduce a series of design choices which address these challenges and make the dataset constitution and usage more sustainable and fairer. $FaVCI2D$ is available at~\url{https://github.com/AIMultimediaLab/FaVCI2D-Face-Verification-with-Challenging-Imposters-and-Diversified-Demographics}.
Overview of MediaEval 2020 Predicting Media Memorability Task: What Makes a Video Memorable?
Dec 31, 2020
This paper describes the MediaEval 2020 \textit{Predicting Media Memorability} task. After first being proposed at MediaEval 2018, the Predicting Media Memorability task is in its 3rd edition this year, as the prediction of short-term and long-term video memorability (VM) remains a challenging task. In 2020, the format remained the same as in previous editions. This year the videos are a subset of the TRECVid 2019 Video-to-Text dataset, containing more action rich video content as compared with the 2019 task. In this paper a description of some aspects of this task is provided, including its main characteristics, a description of the collection, the ground truth dataset, evaluation metrics and the requirements for participants' run submissions.
* 3 pages, 1 Figure
MediaEval 2018: Predicting Media Memorability Task
Jul 03, 2018In this paper, we present the Predicting Media Memorability task, which is proposed as part of the MediaEval 2018 Benchmarking Initiative for Multimedia Evaluation. Participants are expected to design systems that automatically predict memorability scores for videos, which reflect the probability of a video being remembered. In contrast to previous work in image memorability prediction, where memorability was measured a few minutes after memorization, the proposed dataset comes with short-term and long-term memorability annotations. All task characteristics are described, namely: the task's challenges and breakthrough, the released data set and ground truth, the required participant runs and the evaluation metrics.