 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Sentry: Harnessing Ensemble Intelligence for Resilient Detection and Generalisation
Mar 29, 2024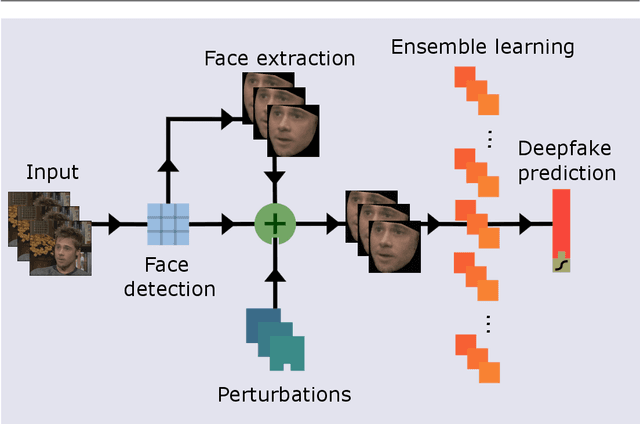
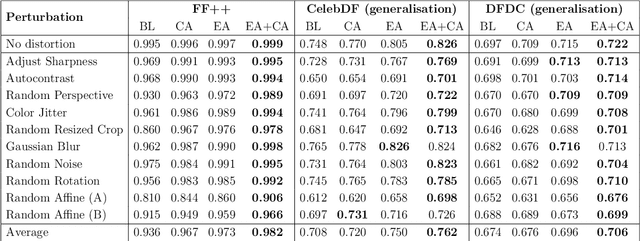
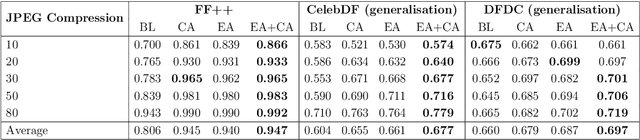

Recent advancements in Generative Adversarial Networks (GANs) have enabled photorealistic image generation with high quality. However, the malicious use of such generated media has raised concerns regarding visual misinformation. Although deepfake detection research has demonstrated high accuracy, it is vulnerable to advances in generation techniques and adversarial iterations on detection countermeasures. To address this, we propose a proactive and sustainable deepfake training augmentation solution that introduces artificial fingerprints into models. We achieve this by employing an ensemble learning approach that incorporates a pool of autoencoders that mimic the effect of the artefacts introduced by the deepfake generator models. Experiments on three datasets reveal that our proposed ensemble autoencoder-based data augmentation learning approach offers improvements in terms of generalisation, resistance against basic data perturbations such as noise, blurring, sharpness enhancement, and affine transforms, resilience to commonly used lossy compression algorithms such as JPEG, and enhanced resistance against adversarial attacks.
Face Verification with Challenging Imposters and Diversified Demographics
Oct 16, 2021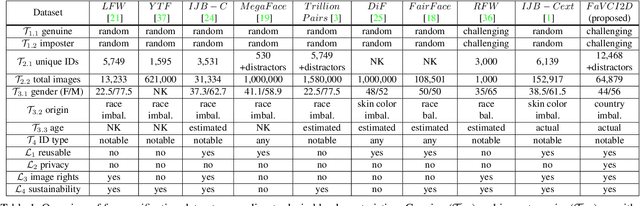

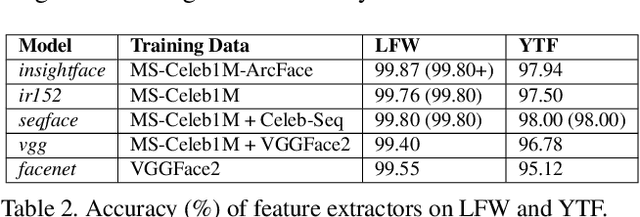
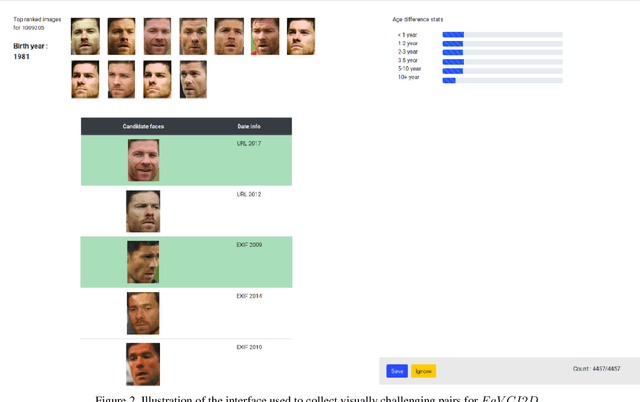
Face verification aims to distinguish between genuine and imposter pairs of faces, which include the same or different identities, respectively. The performance reported in recent years gives the impression that the task is practically solved. Here, we revisit the problem and argue that existing evaluation datasets were built using two oversimplifying design choices. First, the usual identity selection to form imposter pairs is not challenging enough because, in practice, verification is needed to detect challenging imposters. Second, the underlying demographics of existing datasets are often insufficient to account for the wide diversity of facial characteristics of people from across the world. To mitigate these limitations, we introduce the $FaVCI2D$ dataset. Imposter pairs are challenging because they include visually similar faces selected from a large pool of demographically diversified identities. The dataset also includes metadata related to gender, country and age to facilitate fine-grained analysis of results. $FaVCI2D$ is generated from freely distributable resources. Experiments with state-of-the-art deep models that provide nearly 100\% performance on existing datasets show a significant performance drop for $FaVCI2D$, confirming our starting hypothesis. Equally important, we analyze legal and ethical challenges which appeared in recent years and hindered the development of face analysis research. We introduce a series of design choices which address these challenges and make the dataset constitution and usage more sustainable and fairer. $FaVCI2D$ is available at~\url{https://github.com/AIMultimediaLab/FaVCI2D-Face-Verification-with-Challenging-Imposters-and-Diversified-Demographics}.