 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Outpainting To Enhance the Memorability of Short-Form Videos
Nov 21, 2024



With the expanding use of the short-form video format in advertising, social media, entertainment, education and more, there is a need for such media to both captivate and be remembered. Video memorability indicates to us how likely a video is to be remembered by a viewer who has no emotional or personal connection with its content. This paper presents the results of using generative outpainting to expand the screen size of a short-form video with a view to improving its memorability. Advances in machine learning and deep learning are compared and leveraged to understand how extending the borders of video screensizes can affect their memorability to viewers. Using quantitative evaluation we determine the best-performing model for outpainting and the impact of outpainting based on image saliency on video memorability scores
Using Saliency and Cropping to Improve Video Memorability
Sep 21, 2023Video memorability is a measure of how likely a particular video is to be remembered by a viewer when that viewer has no emotional connection with the video content. It is an important characteristic as videos that are more memorable are more likely to be shared, viewed, and discussed. This paper presents results of a series of experiments where we improved the memorability of a video by selectively cropping frames based on image saliency. We present results of a basic fixed cropping as well as the results from dynamic cropping where both the size of the crop and the position of the crop within the frame, move as the video is played and saliency is tracked. Our results indicate that especially for videos of low initial memorability, the memorability score can be improved.
Diffusing Surrogate Dreams of Video Scenes to Predict Video Memorability
Dec 19, 2022


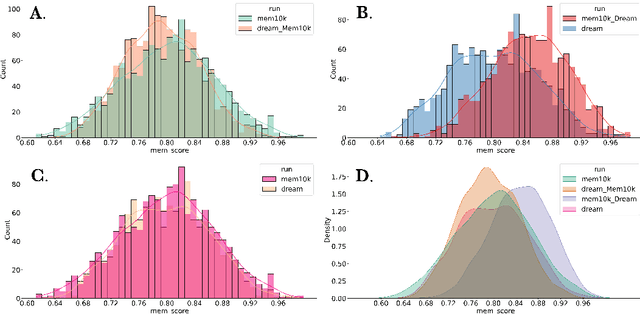
As part of the MediaEval 2022 Predicting Video Memorability task we explore the relationship between visual memorability, the visual representation that characterises it, and the underlying concept portrayed by that visual representation. We achieve state-of-the-art memorability prediction performance with a model trained and tested exclusively on surrogate dream images, elevating concepts to the status of a cornerstone memorability feature, and finding strong evidence to suggest that the intrinsic memorability of visual content can be distilled to its underlying concept or meaning irrespective of its specific visual representational.
Overview of The MediaEval 2022 Predicting Video Memorability Task
Dec 13, 2022This paper describes the 5th edition of the Predicting Video Memorability Task as part of MediaEval2022. This year we have reorganised and simplified the task in order to lubricate a greater depth of inquiry. Similar to last year, two datasets are provided in order to facilitate generalisation, however, this year we have replaced the TRECVid2019 Video-to-Text dataset with the VideoMem dataset in order to remedy underlying data quality issues, and to prioritise short-term memorability prediction by elevating the Memento10k dataset as the primary dataset. Additionally, a fully fledged electroencephalography (EEG)-based prediction sub-task is introduced. In this paper, we outline the core facets of the task and its constituent sub-tasks; describing the datasets, evaluation metrics, and requirements for participant submissions.
Experiences from the MediaEval Predicting Media Memorability Task
Dec 07, 2022


The Predicting Media Memorability task in the MediaEval evaluation campaign has been running annually since 2018 and several different tasks and data sets have been used in this time. This has allowed us to compare the performance of many memorability prediction techniques on the same data and in a reproducible way and to refine and improve on those techniques. The resources created to compute media memorability are now being used by researchers well beyond the actual evaluation campaign. In this paper we present a summary of the task, including the collective lessons we have learned for the research community.
Analysing the Memorability of a Procedural Crime-Drama TV Series, CSI
Aug 06, 2022

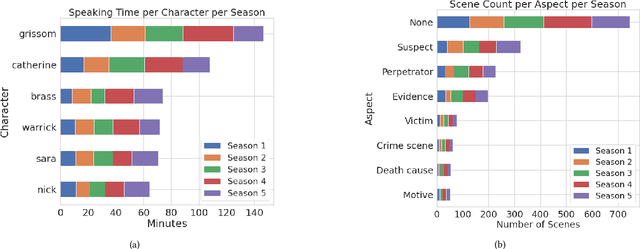
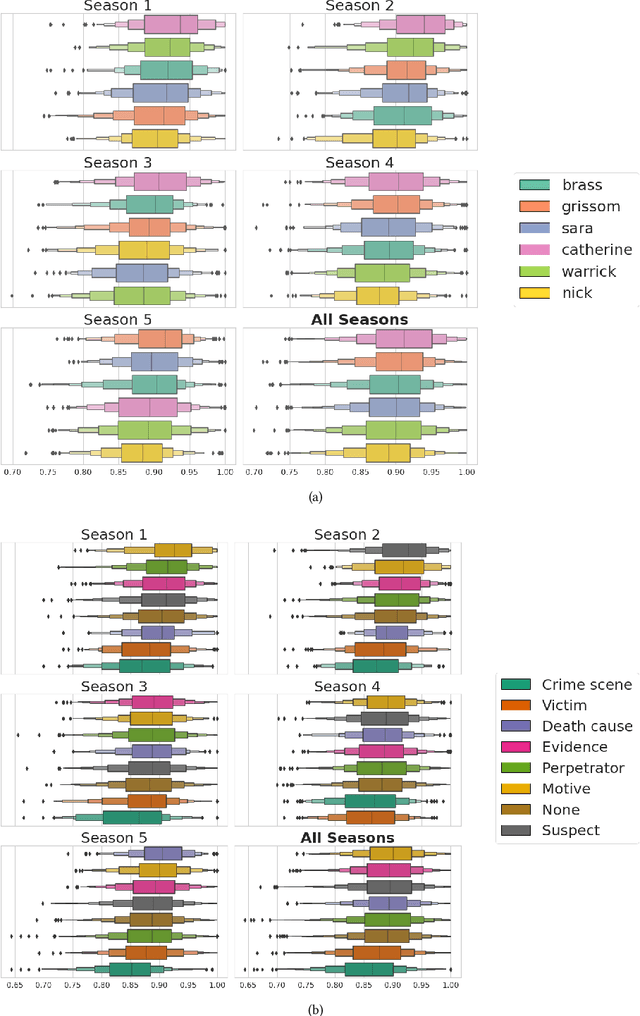
We investigate the memorability of a 5-season span of a popular crime-drama TV series, CSI, through the application of a vision transformer fine-tuned on the task of predicting video memorability. By investigating the popular genre of crime-drama TV through the use of a detailed annotated corpus combined with video memorability scores, we show how to extrapolate meaning from the memorability scores generated on video shots. We perform a quantitative analysis to relate video shot memorability to a variety of aspects of the show. The insights we present in this paper illustrate the importance of video memorability in applications which use multimedia in areas like education, marketing, indexing, as well as in the case here namely TV and film production.
Overview of the EEG Pilot Subtask at MediaEval 2021: Predicting Media Memorability
Dec 15, 2021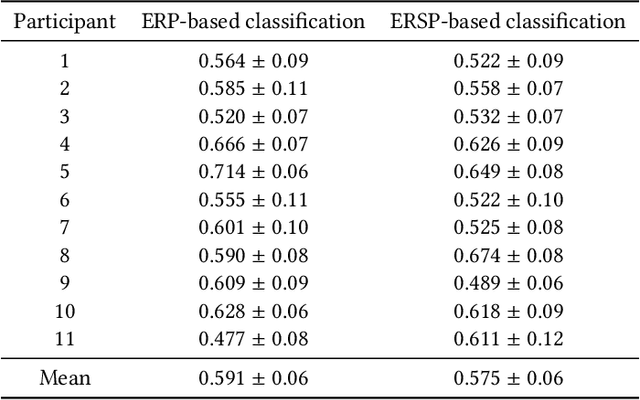
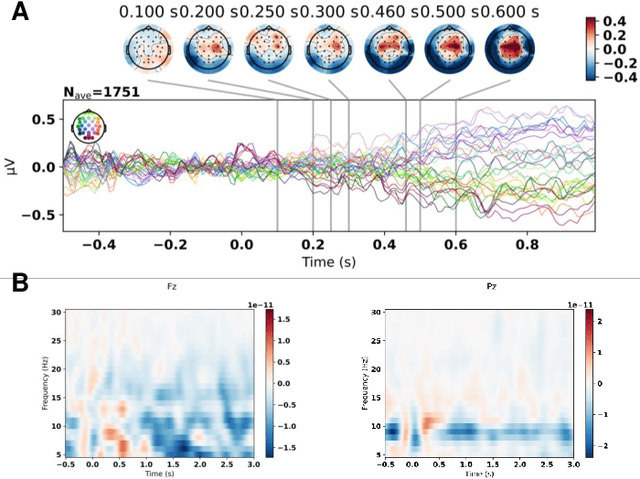
The aim of the Memorability-EEG pilot subtask at MediaEval'2021 is to promote interest in the use of neural signals -- either alone or in combination with other data sources -- in the context of predicting video memorability by highlighting the utility of EEG data. The dataset created consists of pre-extracted features from EEG recordings of subjects while watching a subset of videos from Predicting Media Memorability subtask 1. This demonstration pilot gives interested researchers a sense of how neural signals can be used without any prior domain knowledge, and enables them to do so in a future memorability task. The dataset can be used to support the exploration of novel machine learning and processing strategies for predicting video memorability, while potentially increasing interdisciplinary interest in the subject of memorability, and opening the door to new combined EEG-computer vision approaches.
Predicting Media Memorability: Comparing Visual, Textual and Auditory Features
Dec 15, 2021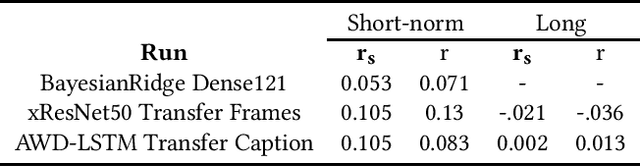
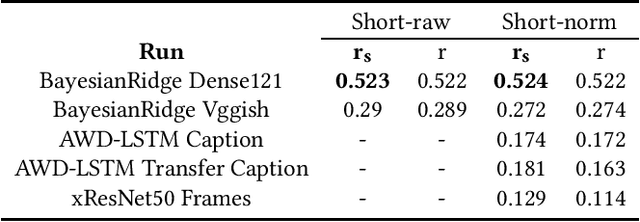
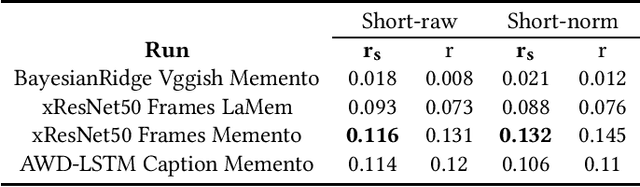
This paper describes our approach to the Predicting Media Memorability task in MediaEval 2021, which aims to address the question of media memorability by setting the task of automatically predicting video memorability. This year we tackle the task from a comparative standpoint, looking to gain deeper insights into each of three explored modalities, and using our results from last year's submission (2020) as a point of reference. Our best performing short-term memorability model (0.132) tested on the TRECVid2019 dataset -- just like last year -- was a frame based CNN that was not trained on any TRECVid data, and our best short-term memorability model (0.524) tested on the Memento10k dataset, was a Bayesian Ride Regressor fit with DenseNet121 visual features.
Overview of The MediaEval 2021 Predicting Media Memorability Task
Dec 11, 2021This paper describes the MediaEval 2021 Predicting Media Memorability}task, which is in its 4th edition this year, as the prediction of short-term and long-term video memorability remains a challenging task. In 2021, two datasets of videos are used: first, a subset of the TRECVid 2019 Video-to-Text dataset; second, the Memento10K dataset in order to provide opportunities to explore cross-dataset generalisation. In addition, an Electroencephalography (EEG)-based prediction pilot subtask is introduced. In this paper, we outline the main aspects of the task and describe the datasets, evaluation metrics, and requirements for participants' submissions.
An Annotated Video Dataset for Computing Video Memorability
Dec 04, 2021
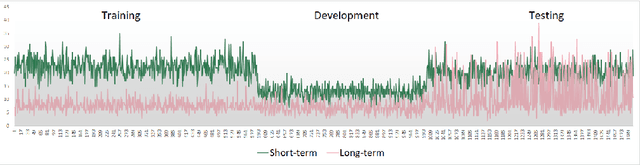
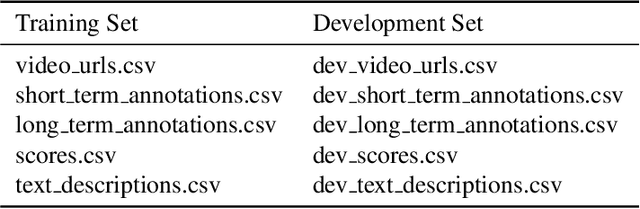
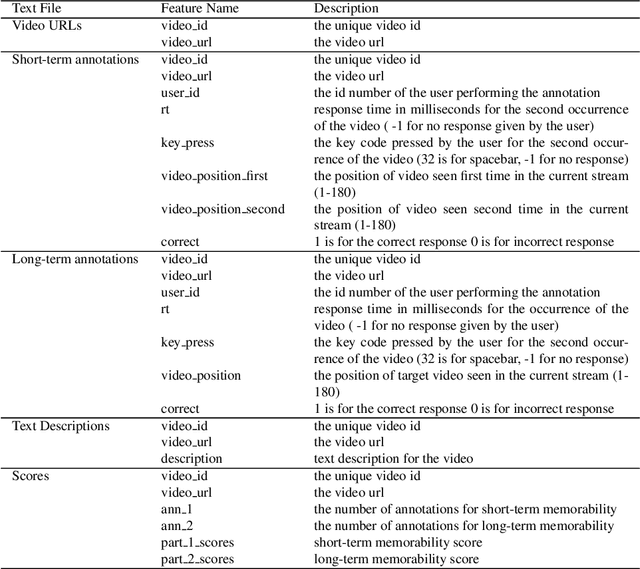
Using a collection of publicly available links to short form video clips of an average of 6 seconds duration each, 1,275 users manually annotated each video multiple times to indicate both long-term and short-term memorability of the videos. The annotations were gathered as part of an online memory game and measured a participant's ability to recall having seen the video previously when shown a collection of videos. The recognition tasks were performed on videos seen within the previous few minutes for short-term memorability and within the previous 24 to 72 hours for long-term memorability. Data includes the reaction times for each recognition of each video. Associated with each video are text descriptions (captions) as well as a collection of image-level features applied to 3 frames extracted from each video (start, middle and end). Video-level features are also provided. The dataset was used in the Video Memorability task as part of the MediaEval benchmark in 2020.
* 11 pages