 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of The MediaEval 2021 Predicting Media Memorability Task
Dec 11, 2021This paper describes the MediaEval 2021 Predicting Media Memorability}task, which is in its 4th edition this year, as the prediction of short-term and long-term video memorability remains a challenging task. In 2021, two datasets of videos are used: first, a subset of the TRECVid 2019 Video-to-Text dataset; second, the Memento10K dataset in order to provide opportunities to explore cross-dataset generalisation. In addition, an Electroencephalography (EEG)-based prediction pilot subtask is introduced. In this paper, we outline the main aspects of the task and describe the datasets, evaluation metrics, and requirements for participants' submissions.
An Annotated Video Dataset for Computing Video Memorability
Dec 04, 2021
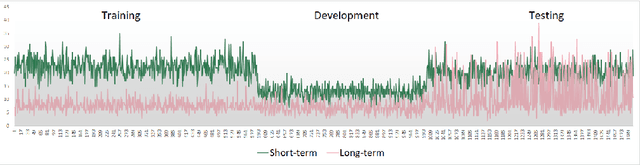
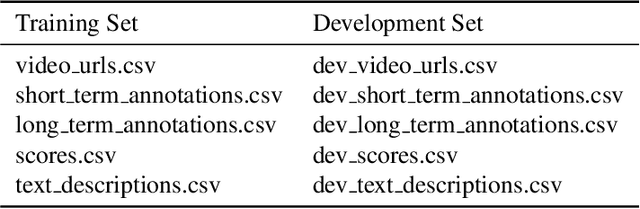
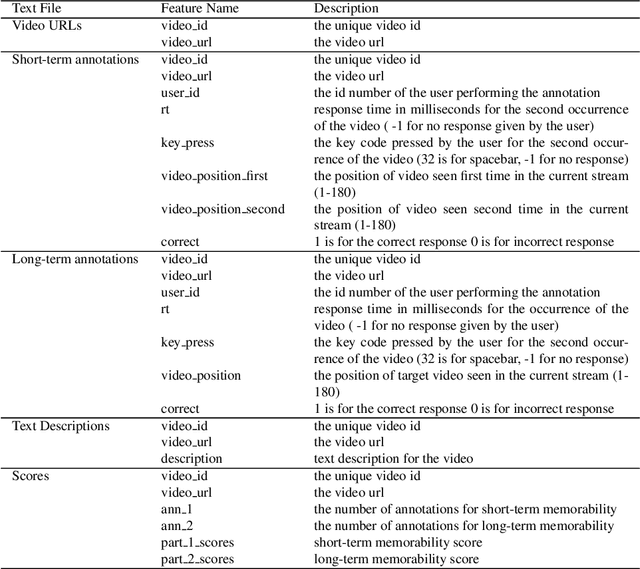
Using a collection of publicly available links to short form video clips of an average of 6 seconds duration each, 1,275 users manually annotated each video multiple times to indicate both long-term and short-term memorability of the videos. The annotations were gathered as part of an online memory game and measured a participant's ability to recall having seen the video previously when shown a collection of videos. The recognition tasks were performed on videos seen within the previous few minutes for short-term memorability and within the previous 24 to 72 hours for long-term memorability. Data includes the reaction times for each recognition of each video. Associated with each video are text descriptions (captions) as well as a collection of image-level features applied to 3 frames extracted from each video (start, middle and end). Video-level features are also provided. The dataset was used in the Video Memorability task as part of the MediaEval benchmark in 2020.
* 11 pages
Overview of MediaEval 2020 Predicting Media Memorability Task: What Makes a Video Memorable?
Dec 31, 2020
This paper describes the MediaEval 2020 \textit{Predicting Media Memorability} task. After first being proposed at MediaEval 2018, the Predicting Media Memorability task is in its 3rd edition this year, as the prediction of short-term and long-term video memorability (VM) remains a challenging task. In 2020, the format remained the same as in previous editions. This year the videos are a subset of the TRECVid 2019 Video-to-Text dataset, containing more action rich video content as compared with the 2019 task. In this paper a description of some aspects of this task is provided, including its main characteristics, a description of the collection, the ground truth dataset, evaluation metrics and the requirements for participants' run submissions.
* 3 pages, 1 Figure