 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter Bubbles in Recommender Systems: Fact or Fallacy -- A Systematic Review
Jul 02, 2023A filter bubble refers to the phenomenon where Internet customization effectively isolates individuals from diverse opinions or materials, resulting in their exposure to only a select set of content. This can lead to the reinforcement of existing attitudes, beliefs, or conditions. In this study, our primary focus is to investigate the impact of filter bubbles in recommender systems. This pioneering research aims to uncover the reasons behind this problem, explore potential solutions, and propose an integrated tool to help users avoid filter bubbles in recommender systems. To achieve this objective, we conduct a systematic literature review on the topic of filter bubbles in recommender systems. The reviewed articles are carefully analyzed and classified, providing valuable insights that inform the development of an integrated approach. Notably, our review reveals evidence of filter bubbles in recommendation systems, highlighting several biases that contribute to their existence. Moreover, we propose mechanisms to mitigate the impact of filter bubbles and demonstrate that incorporating diversity into recommendations can potentially help alleviate this issue. The findings of this timely review will serve as a benchmark for researchers working in interdisciplinary fields such as privacy, artificial intelligence ethics, and recommendation systems. Furthermore, it will open new avenues for future research in related domains, prompting further exploration and advancement in this critical area.
An Annotated Video Dataset for Computing Video Memorability
Dec 04, 2021
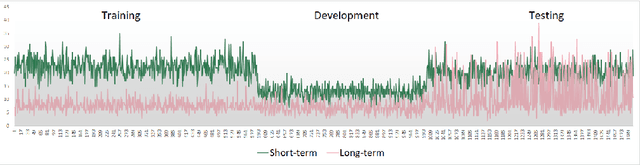
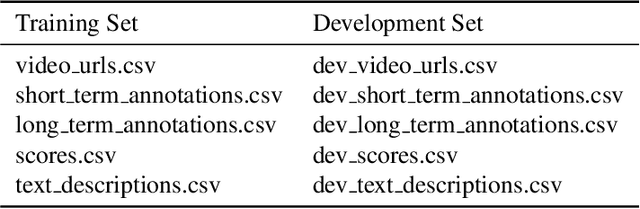
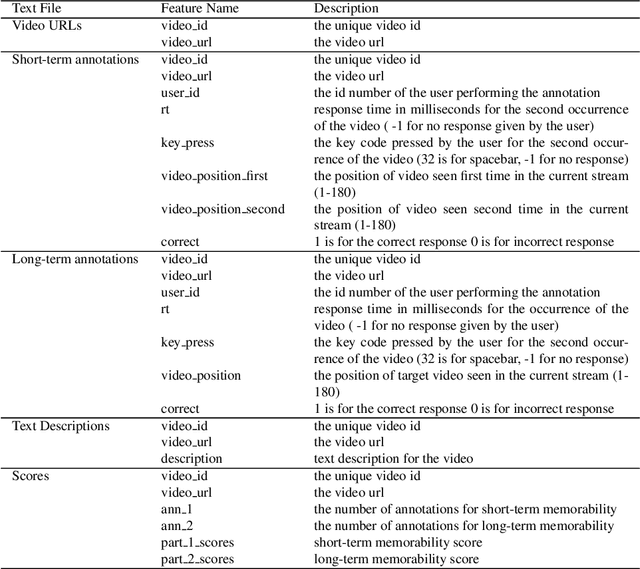
Using a collection of publicly available links to short form video clips of an average of 6 seconds duration each, 1,275 users manually annotated each video multiple times to indicate both long-term and short-term memorability of the videos. The annotations were gathered as part of an online memory game and measured a participant's ability to recall having seen the video previously when shown a collection of videos. The recognition tasks were performed on videos seen within the previous few minutes for short-term memorability and within the previous 24 to 72 hours for long-term memorability. Data includes the reaction times for each recognition of each video. Associated with each video are text descriptions (captions) as well as a collection of image-level features applied to 3 frames extracted from each video (start, middle and end). Video-level features are also provided. The dataset was used in the Video Memorability task as part of the MediaEval benchmark in 2020.
* 11 pages
Overview of MediaEval 2020 Predicting Media Memorability Task: What Makes a Video Memorable?
Dec 31, 2020
This paper describes the MediaEval 2020 \textit{Predicting Media Memorability} task. After first being proposed at MediaEval 2018, the Predicting Media Memorability task is in its 3rd edition this year, as the prediction of short-term and long-term video memorability (VM) remains a challenging task. In 2020, the format remained the same as in previous editions. This year the videos are a subset of the TRECVid 2019 Video-to-Text dataset, containing more action rich video content as compared with the 2019 task. In this paper a description of some aspects of this task is provided, including its main characteristics, a description of the collection, the ground truth dataset, evaluation metrics and the requirements for participants' run submissions.
* 3 pages, 1 Figure