 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the EEG Pilot Subtask at MediaEval 2021: Predicting Media Memorability
Dec 15, 2021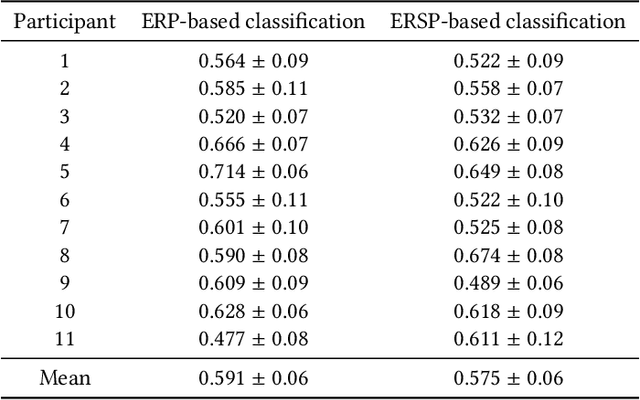
The aim of the Memorability-EEG pilot subtask at MediaEval'2021 is to promote interest in the use of neural signals -- either alone or in combination with other data sources -- in the context of predicting video memorability by highlighting the utility of EEG data. The dataset created consists of pre-extracted features from EEG recordings of subjects while watching a subset of videos from Predicting Media Memorability subtask 1. This demonstration pilot gives interested researchers a sense of how neural signals can be used without any prior domain knowledge, and enables them to do so in a future memorability task. The dataset can be used to support the exploration of novel machine learning and processing strategies for predicting video memorability, while potentially increasing interdisciplinary interest in the subject of memorability, and opening the door to new combined EEG-computer vision approaches.
Attention-based Stylisation for Exemplar Image Colourisation
May 04, 2021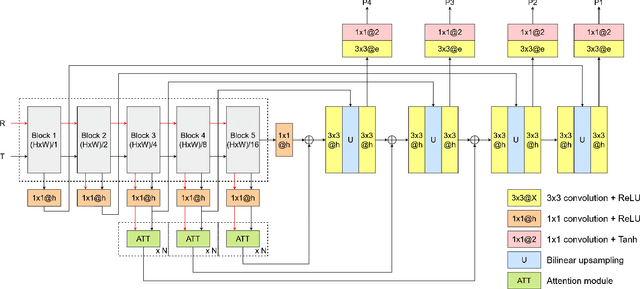
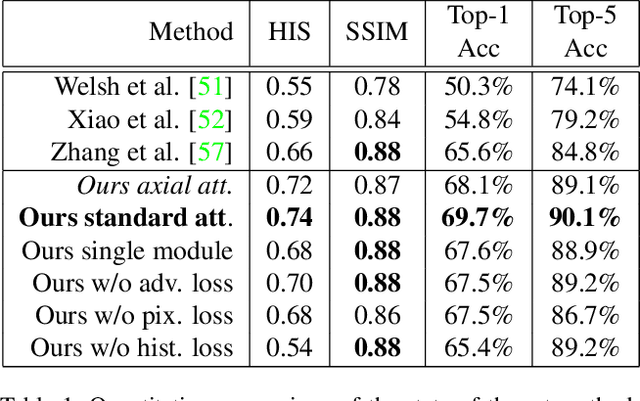
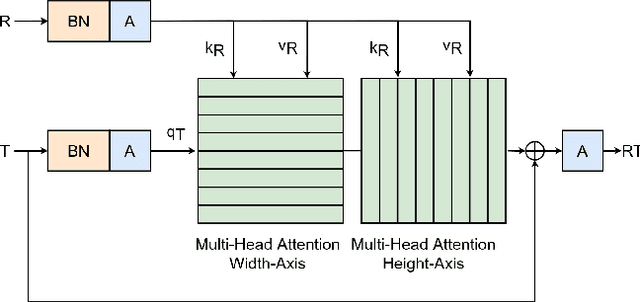
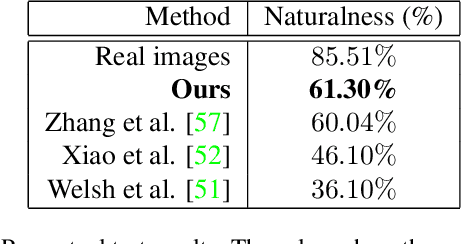
Exemplar-based colourisation aims to add plausible colours to a grayscale image using the guidance of a colour reference image. Most of the existing methods tackle the task as a style transfer problem, using a convolutional neural network (CNN) to obtain deep representations of the content of both inputs. Stylised outputs are then obtained by computing similarities between both feature representations in order to transfer the style of the reference to the content of the target input. However, in order to gain robustness towards dissimilar references, the stylised outputs need to be refined with a second colourisation network, which significantly increases the overall system complexity. This work reformulates the existing methodology introducing a novel end-to-end colourisation network that unifies the feature matching with the colourisation process. The proposed architecture integrates attention modules at different resolutions that learn how to perform the style transfer task in an unsupervised way towards decoding realistic colour predictions. Moreover, axial attention is proposed to simplify the attention operations and to obtain a fast but robust cost-effective architecture. Experimental validations demonstrate efficiency of the proposed methodology which generates high quality and visual appealing colourisation. Furthermore, the complexity of the proposed methodology is reduced compared to the state-of-the-art methods.
AlphaMWE: Construction of Multilingual Parallel Corpora with MWE Annotations
Nov 07, 2020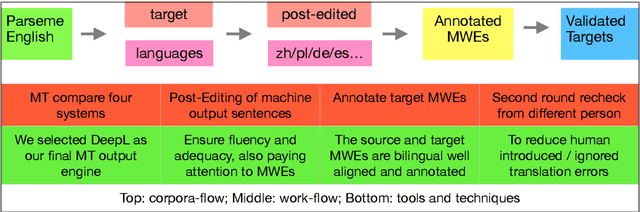



In this work, we present the construction of multilingual parallel corpora with annotation of multiword expressions (MWEs). MWEs include verbal MWEs (vMWEs) defined in the PARSEME shared task that have a verb as the head of the studied terms. The annotated vMWEs are also bilingually and multilingually aligned manually. The languages covered include English, Chinese, Polish, and German. Our original English corpus is taken from the PARSEME shared task in 2018. We performed machine translation of this source corpus followed by human post editing and annotation of target MWEs. Strict quality control was applied for error limitation, i.e., each MT output sentence received first manual post editing and annotation plus second manual quality rechecking. One of our findings during corpora preparation is that accurate translation of MWEs presents challenges to MT systems. To facilitate further MT research, we present a categorisation of the error types encountered by MT systems in performing MWE related translation. To acquire a broader view of MT issues, we selected four popular state-of-the-art MT models for comparisons namely: Microsoft Bing Translator, GoogleMT, Baidu Fanyi and DeepL MT. Because of the noise removal, translation post editing and MWE annotation by human professionals, we believe our AlphaMWE dataset will be an asset for cross-lingual and multilingual research, such as MT and information extraction. Our multilingual corpora are available as open access at github.com/poethan/AlphaMWE.
Investigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020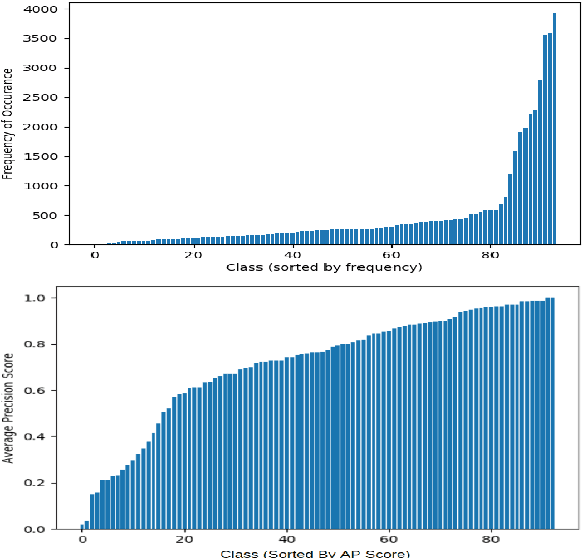

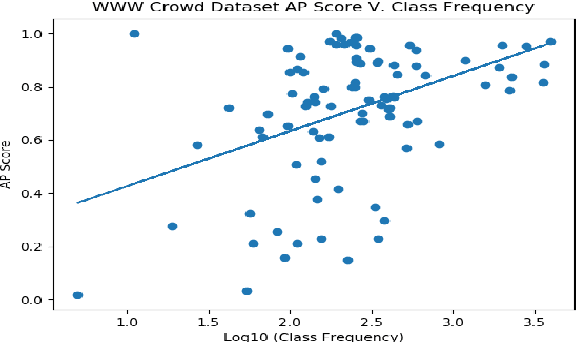

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.
Evaluation of Automatic Video Captioning Using Direct Assessment
Oct 29, 2017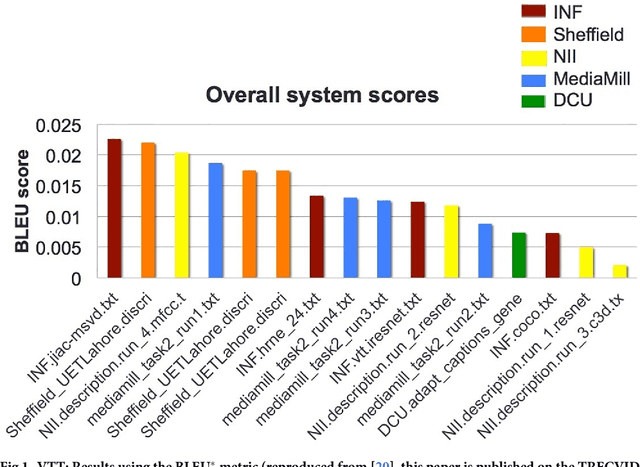

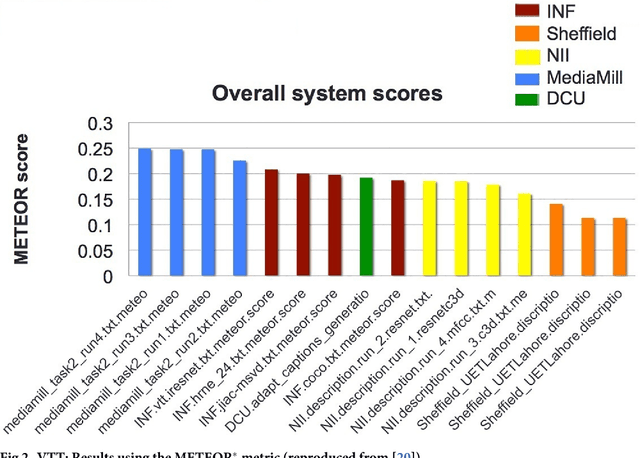
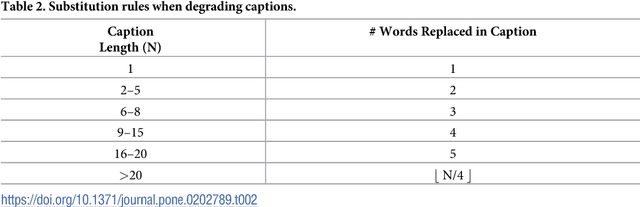
We present Direct Assessment, a method for manually assessing the quality of automatically-generated captions for video. Evaluating the accuracy of video captions is particularly difficult because for any given video clip there is no definitive ground truth or correct answer against which to measure. Automatic metrics for comparing automatic video captions against a manual caption such as BLEU and METEOR, drawn from techniques used in evaluating machine translation, were used in the TRECVid video captioning task in 2016 but these are shown to have weaknesses. The work presented here brings human assessment into the evaluation by crowdsourcing how well a caption describes a video. We automatically degrade the quality of some sample captions which are assessed manually and from this we are able to rate the quality of the human assessors, a factor we take into account in the evaluation. Using data from the TRECVid video-to-text task in 2016, we show how our direct assessment method is replicable and robust and should scale to where there many caption-generation techniques to be evaluated.