 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAScore -- An Unsupervised Unreferenced Metric for the Question Generation Evaluation
Oct 09, 2022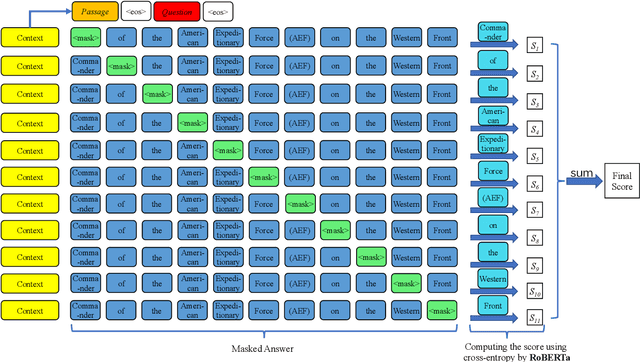
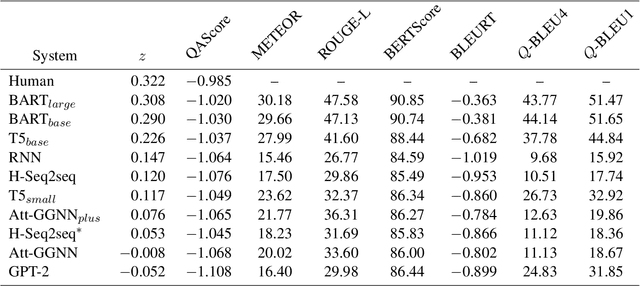
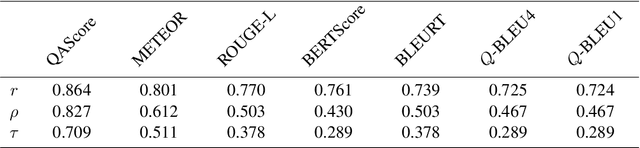

Question Generation (QG) aims to automate the task of composing questions for a passage with a set of chosen answers found within the passage. In recent years, the introduction of neural generation models has resulted in substantial improvements of automatically generated questions in terms of quality, especially compared to traditional approaches that employ manually crafted heuristics. However, the metrics commonly applied in QG evaluations have been criticized for their low agreement with human judgement. We therefore propose a new reference-free evaluation metric that has the potential to provide a better mechanism for evaluating QG systems, called QAScore. Instead of fine-tuning a language model to maximize its correlation with human judgements, QAScore evaluates a question by computing the cross entropy according to the probability that the language model can correctly generate the masked words in the answer to that question. Furthermore, we conduct a new crowd-sourcing human evaluation experiment for the QG evaluation to investigate how QAScore and other metrics can correlate with human judgements. Experiments show that QAScore obtains a stronger correlation with the results of our proposed human evaluation method compared to existing traditional word-overlap-based metrics such as BLEU and ROUGE, as well as the existing pretrained-model-based metric BERTScore.
Machine learning for detection of stenoses and aneurysms: application in a physiologically realistic virtual patient database
Mar 11, 2021
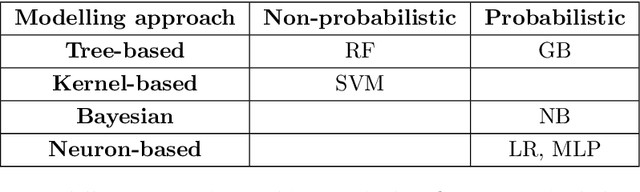

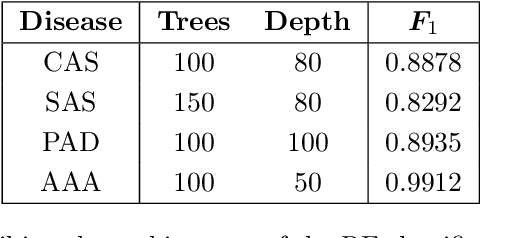
This study presents an application of machine learning (ML) methods for detecting the presence of stenoses and aneurysms in the human arterial system. Four major forms of arterial disease -- carotid artery stenosis (CAS), subclavian artery stenosis (SAC), peripheral arterial disease (PAD), and abdominal aortic aneurysms (AAA) -- are considered. The ML methods are trained and tested on a physiologically realistic virtual patient database (VPD) containing 28,868 healthy subjects, which is adapted from the authors previous work and augmented to include the four disease forms. Six ML methods -- Naive Bayes, Logistic Regression, Support Vector Machine, Multi-layer Perceptron, Random Forests, and Gradient Boosting -- are compared with respect to classification accuracies and it is found that the tree-based methods of Random Forest and Gradient Boosting outperform other approaches. The performance of ML methods is quantified through the F1 score and computation of sensitivities and specificities. When using all the six measurements, it is found that maximum F1 scores larger than 0.9 are achieved for CAS and PAD, larger than 0.85 for SAS, and larger than 0.98 for both low- and high-severity AAAs. Corresponding sensitivities and specificities are larger than 90% for CAS and PAD, larger than 85% for SAS, and larger than 98% for both low- and high-severity AAAs. When reducing the number of measurements, it is found that the performance is degraded by less than 5% when three measurements are used, and less than 10% when only two measurements are used for classification. For AAA, it is shown that F1 scores larger than 0.85 and corresponding sensitivities and specificities larger than 85% are achievable when using only a single measurement. The results are encouraging to pursue AAA monitoring and screening through wearable devices which can reliably measure pressure or flow-rates
A proof of concept study for machine learning application to stenosis detection
Feb 11, 2021



This proof of concept (PoC) assesses the ability of machine learning (ML) classifiers to predict the presence of a stenosis in a three vessel arterial system consisting of the abdominal aorta bifurcating into the two common iliacs. A virtual patient database (VPD) is created using one-dimensional pulse wave propagation model of haemodynamics. Four different machine learning (ML) methods are used to train and test a series of classifiers -- both binary and multiclass -- to distinguish between healthy and unhealthy virtual patients (VPs) using different combinations of pressure and flow-rate measurements. It is found that the ML classifiers achieve specificities larger than 80% and sensitivities ranging from 50-75%. The most balanced classifier also achieves an area under the receiver operative characteristic curve of 0.75, outperforming approximately 20 methods used in clinical practice, and thus placing the method as moderately accurate. Other important observations from this study are that: i) few measurements can provide similar classification accuracies compared to the case when more/all the measurements are used; ii) some measurements are more informative than others for classification; and iii) a modification of standard methods can result in detection of not only the presence of stenosis, but also the stenosed vessel.
AlphaMWE: Construction of Multilingual Parallel Corpora with MWE Annotations
Nov 07, 2020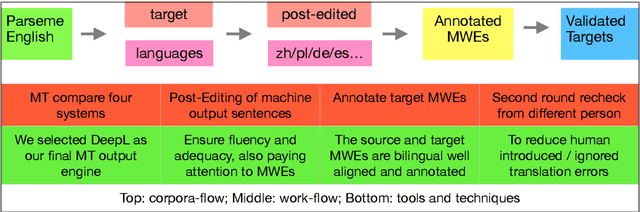



In this work, we present the construction of multilingual parallel corpora with annotation of multiword expressions (MWEs). MWEs include verbal MWEs (vMWEs) defined in the PARSEME shared task that have a verb as the head of the studied terms. The annotated vMWEs are also bilingually and multilingually aligned manually. The languages covered include English, Chinese, Polish, and German. Our original English corpus is taken from the PARSEME shared task in 2018. We performed machine translation of this source corpus followed by human post editing and annotation of target MWEs. Strict quality control was applied for error limitation, i.e., each MT output sentence received first manual post editing and annotation plus second manual quality rechecking. One of our findings during corpora preparation is that accurate translation of MWEs presents challenges to MT systems. To facilitate further MT research, we present a categorisation of the error types encountered by MT systems in performing MWE related translation. To acquire a broader view of MT issues, we selected four popular state-of-the-art MT models for comparisons namely: Microsoft Bing Translator, GoogleMT, Baidu Fanyi and DeepL MT. Because of the noise removal, translation post editing and MWE annotation by human professionals, we believe our AlphaMWE dataset will be an asset for cross-lingual and multilingual research, such as MT and information extraction. Our multilingual corpora are available as open access at github.com/poethan/AlphaMWE.