 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQAScore -- An Unsupervised Unreferenced Metric for the Question Generation Evaluation
Paper and Code
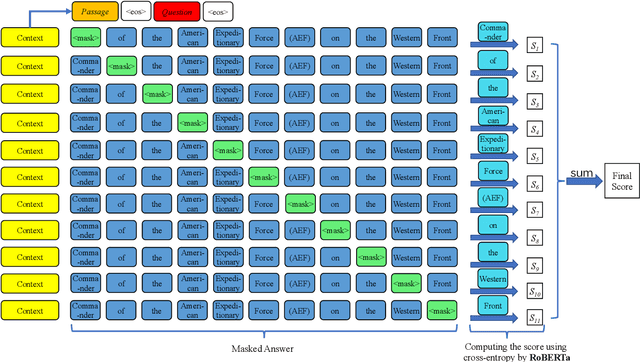
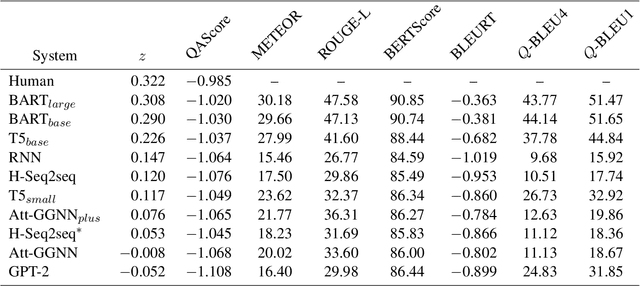
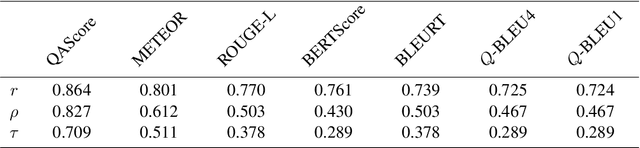

Question Generation (QG) aims to automate the task of composing questions for a passage with a set of chosen answers found within the passage. In recent years, the introduction of neural generation models has resulted in substantial improvements of automatically generated questions in terms of quality, especially compared to traditional approaches that employ manually crafted heuristics. However, the metrics commonly applied in QG evaluations have been criticized for their low agreement with human judgement. We therefore propose a new reference-free evaluation metric that has the potential to provide a better mechanism for evaluating QG systems, called QAScore. Instead of fine-tuning a language model to maximize its correlation with human judgements, QAScore evaluates a question by computing the cross entropy according to the probability that the language model can correctly generate the masked words in the answer to that question. Furthermore, we conduct a new crowd-sourcing human evaluation experiment for the QG evaluation to investigate how QAScore and other metrics can correlate with human judgements. Experiments show that QAScore obtains a stronger correlation with the results of our proposed human evaluation method compared to existing traditional word-overlap-based metrics such as BLEU and ROUGE, as well as the existing pretrained-model-based metric BERTScore.