 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Convolution and Transformer-Based Network for Video Frame Interpolation
Jul 12, 2023
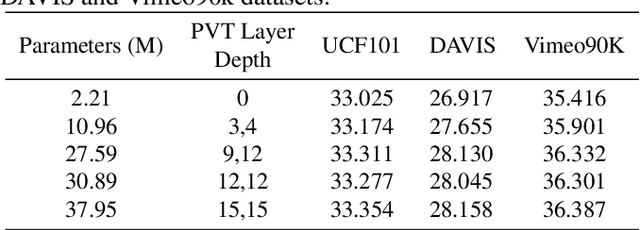
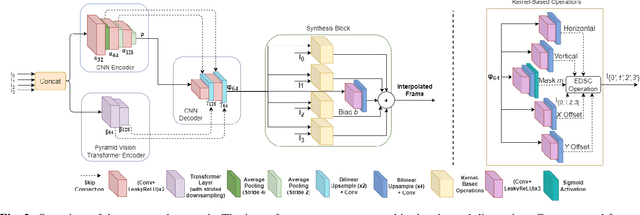

Video frame interpolation is an increasingly important research task with several key industrial applications in the video coding, broadcast and production sectors. Recently, transformers have been introduced to the field resulting in substantial performance gains. However, this comes at a cost of greatly increased memory usage, training and inference time. In this paper, a novel method integrating a transformer encoder and convolutional features is proposed. This network reduces the memory burden by close to 50% and runs up to four times faster during inference time compared to existing transformer-based interpolation methods. A dual-encoder architecture is introduced which combines the strength of convolutions in modelling local correlations with those of the transformer for long-range dependencies. Quantitative evaluations are conducted on various benchmarks with complex motion to showcase the robustness of the proposed method, achieving competitive performance compared to state-of-the-art interpolation networks.
Multi-encoder Network for Parameter Reduction of a Kernel-based Interpolation Architecture
May 13, 2022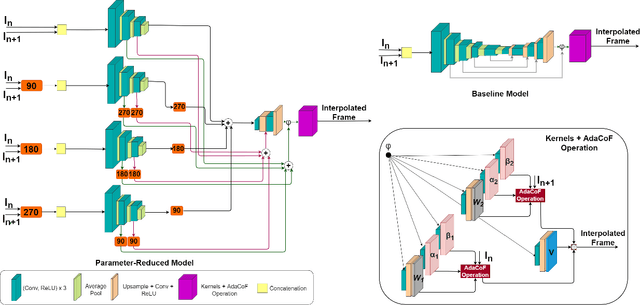
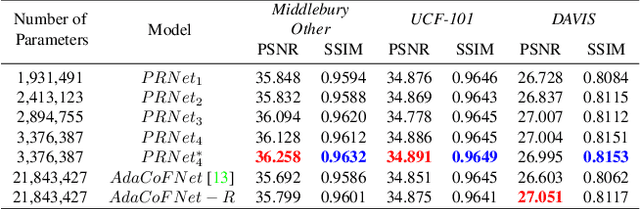


Video frame interpolation involves the synthesis of new frames from existing ones. Convolutional neural networks (CNNs) have been at the forefront of the recent advances in this field. One popular CNN-based approach involves the application of generated kernels to the input frames to obtain an interpolated frame. Despite all the benefits interpolation methods offer, many of these networks require a lot of parameters, with more parameters meaning a heavier computational burden. Reducing the size of the model typically impacts performance negatively. This paper presents a method for parameter reduction for a popular flow-less kernel-based network (Adaptive Collaboration of Flows). Through our technique of removing the layers that require the most parameters and replacing them with smaller encoders, we reduce the number of parameters of the network and even achieve better performance compared to the original method. This is achieved by deploying rotation to force each individual encoder to learn different features from the input images. Ablations are conducted to justify design choices and an evaluation on how our method performs on full-length videos is presented.
Attention-based Stylisation for Exemplar Image Colourisation
May 04, 2021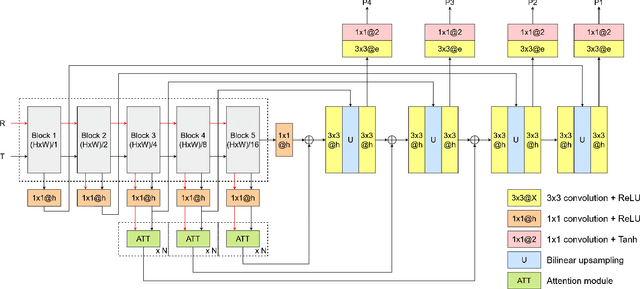
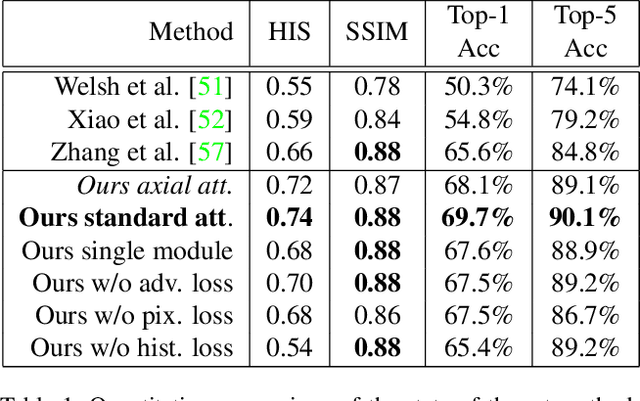
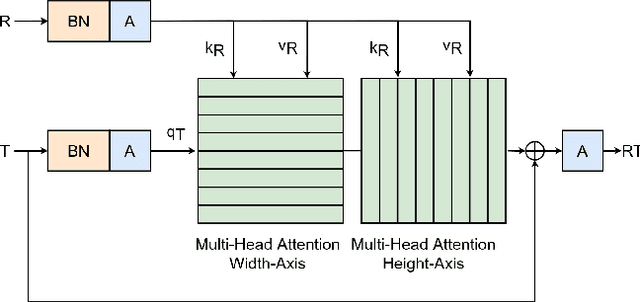
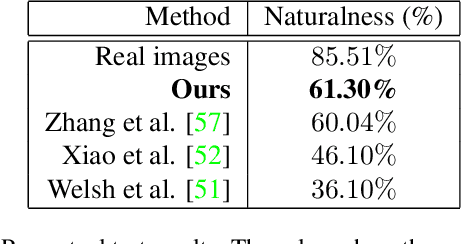
Exemplar-based colourisation aims to add plausible colours to a grayscale image using the guidance of a colour reference image. Most of the existing methods tackle the task as a style transfer problem, using a convolutional neural network (CNN) to obtain deep representations of the content of both inputs. Stylised outputs are then obtained by computing similarities between both feature representations in order to transfer the style of the reference to the content of the target input. However, in order to gain robustness towards dissimilar references, the stylised outputs need to be refined with a second colourisation network, which significantly increases the overall system complexity. This work reformulates the existing methodology introducing a novel end-to-end colourisation network that unifies the feature matching with the colourisation process. The proposed architecture integrates attention modules at different resolutions that learn how to perform the style transfer task in an unsupervised way towards decoding realistic colour predictions. Moreover, axial attention is proposed to simplify the attention operations and to obtain a fast but robust cost-effective architecture. Experimental validations demonstrate efficiency of the proposed methodology which generates high quality and visual appealing colourisation. Furthermore, the complexity of the proposed methodology is reduced compared to the state-of-the-art methods.