 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Convolution and Transformer-Based Network for Video Frame Interpolation
Paper and Code
Jul 12, 2023
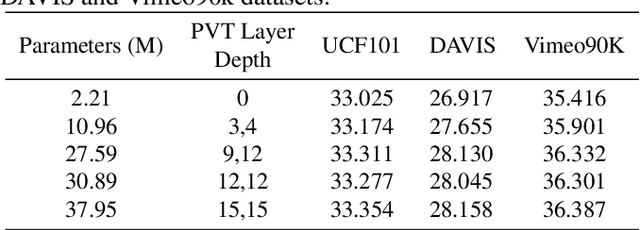
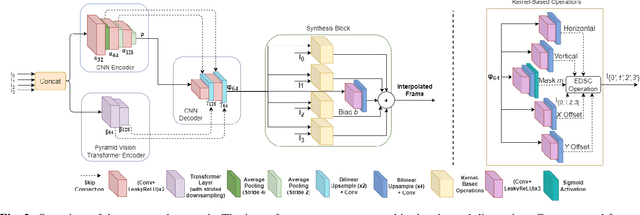

Video frame interpolation is an increasingly important research task with several key industrial applications in the video coding, broadcast and production sectors. Recently, transformers have been introduced to the field resulting in substantial performance gains. However, this comes at a cost of greatly increased memory usage, training and inference time. In this paper, a novel method integrating a transformer encoder and convolutional features is proposed. This network reduces the memory burden by close to 50% and runs up to four times faster during inference time compared to existing transformer-based interpolation methods. A dual-encoder architecture is introduced which combines the strength of convolutions in modelling local correlations with those of the transformer for long-range dependencies. Quantitative evaluations are conducted on various benchmarks with complex motion to showcase the robustness of the proposed method, achieving competitive performance compared to state-of-the-art interpolation networks.