 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Neural Networks for One-shot Object Recognition and Detection
Aug 01, 2024



This paper presents a novel joint neural networks approach to address the challenging one-shot object recognition and detection tasks. Inspired by Siamese neural networks and state-of-art multi-box detection approaches, the joint neural networks are able to perform object recognition and detection for categories that remain unseen during the training process. Following the one-shot object recognition/detection constraints, the training and testing datasets do not contain overlapped classes, in other words, all the test classes remain unseen during training. The joint networks architecture is able to effectively compare pairs of images via stacked convolutional layers of the query and target inputs, recognising patterns of the same input query category without relying on previous training around this category. The proposed approach achieves 61.41% accuracy for one-shot object recognition on the MiniImageNet dataset and 47.1% mAP for one-shot object detection when trained on the COCO dataset and tested using the Pascal VOC dataset. Code available at https://github.com/cjvargasc/JNN recog and https://github.com/cjvargasc/JNN detection/
Efficient Convolution and Transformer-Based Network for Video Frame Interpolation
Jul 12, 2023
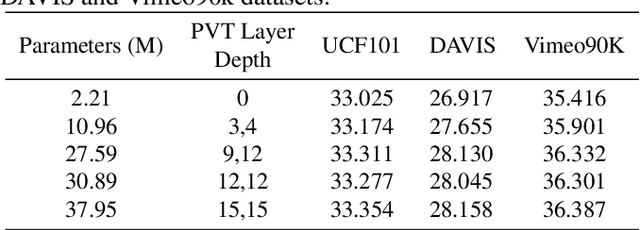
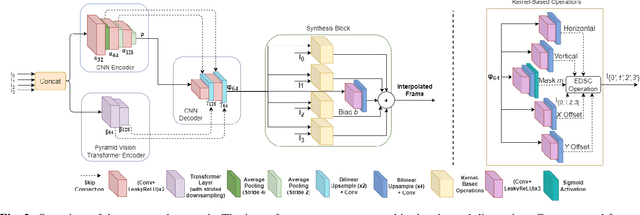

Video frame interpolation is an increasingly important research task with several key industrial applications in the video coding, broadcast and production sectors. Recently, transformers have been introduced to the field resulting in substantial performance gains. However, this comes at a cost of greatly increased memory usage, training and inference time. In this paper, a novel method integrating a transformer encoder and convolutional features is proposed. This network reduces the memory burden by close to 50% and runs up to four times faster during inference time compared to existing transformer-based interpolation methods. A dual-encoder architecture is introduced which combines the strength of convolutions in modelling local correlations with those of the transformer for long-range dependencies. Quantitative evaluations are conducted on various benchmarks with complex motion to showcase the robustness of the proposed method, achieving competitive performance compared to state-of-the-art interpolation networks.
Multi-encoder Network for Parameter Reduction of a Kernel-based Interpolation Architecture
May 13, 2022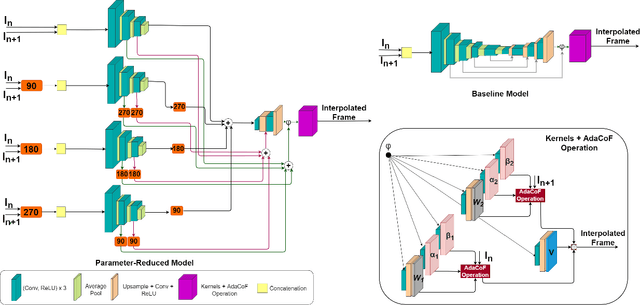
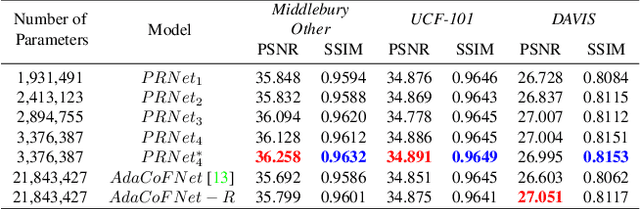


Video frame interpolation involves the synthesis of new frames from existing ones. Convolutional neural networks (CNNs) have been at the forefront of the recent advances in this field. One popular CNN-based approach involves the application of generated kernels to the input frames to obtain an interpolated frame. Despite all the benefits interpolation methods offer, many of these networks require a lot of parameters, with more parameters meaning a heavier computational burden. Reducing the size of the model typically impacts performance negatively. This paper presents a method for parameter reduction for a popular flow-less kernel-based network (Adaptive Collaboration of Flows). Through our technique of removing the layers that require the most parameters and replacing them with smaller encoders, we reduce the number of parameters of the network and even achieve better performance compared to the original method. This is achieved by deploying rotation to force each individual encoder to learn different features from the input images. Ablations are conducted to justify design choices and an evaluation on how our method performs on full-length videos is presented.
Complexity Reduction of Learned In-Loop Filtering in Video Coding
Mar 17, 2022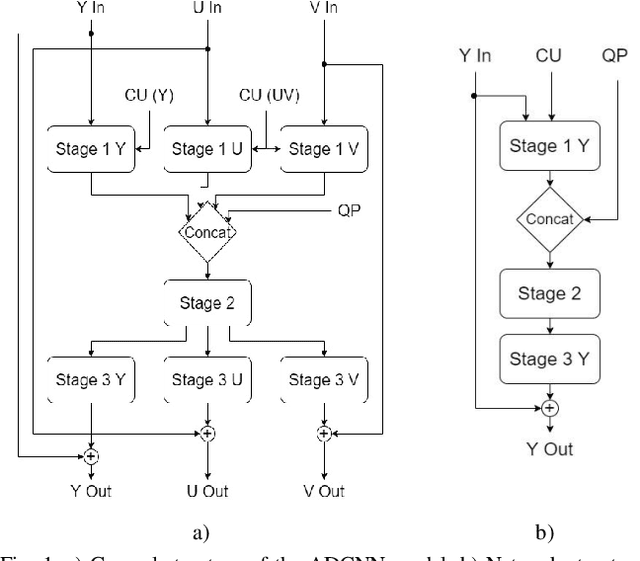
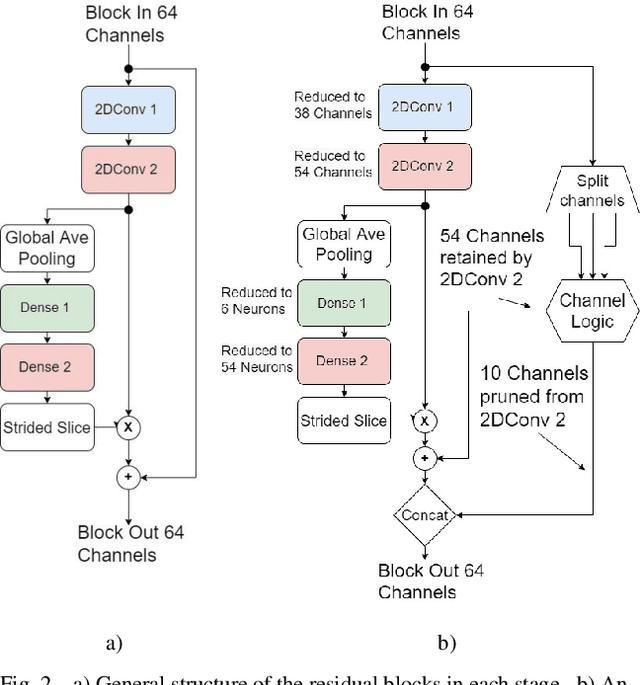
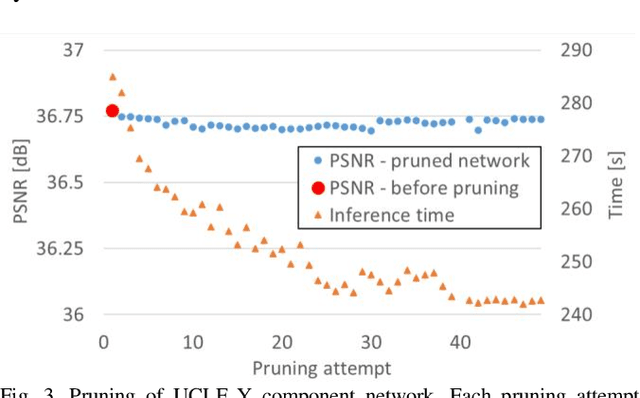
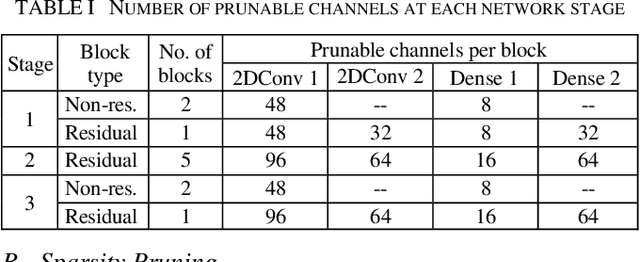
In video coding, in-loop filters are applied on reconstructed video frames to enhance their perceptual quality, before storing the frames for output. Conventional in-loop filters are obtained by hand-crafted methods. Recently, learned filters based on convolutional neural networks that utilize attention mechanisms have been shown to improve upon traditional techniques. However, these solutions are typically significantly more computationally expensive, limiting their potential for practical applications. The proposed method uses a novel combination of sparsity and structured pruning for complexity reduction of learned in-loop filters. This is done through a three-step training process of magnitude-guidedweight pruning, insignificant neuron identification and removal, and fine-tuning. Through initial tests we find that network parameters can be significantly reduced with a minimal impact on network performance.
Analytic Simplification of Neural Network based Intra-Prediction Modes for Video Compression
Apr 23, 2020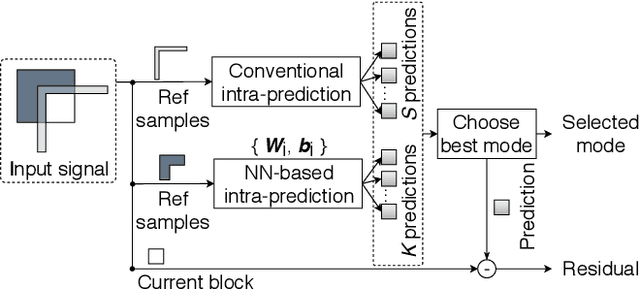
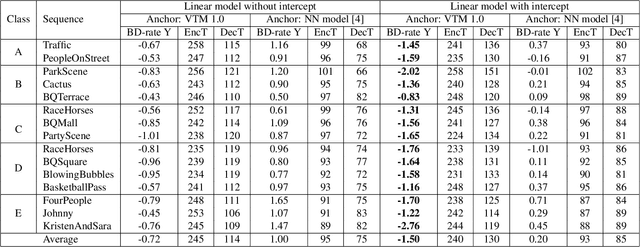
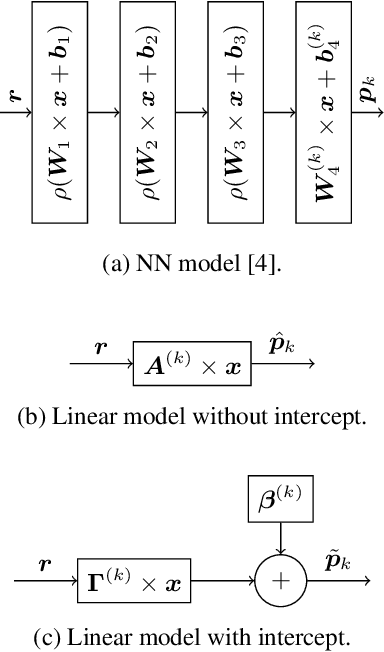
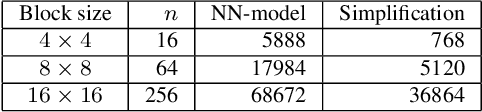
With the increasing demand for video content at higher resolutions, it is evermore critical to find ways to limit the complexity of video encoding tasks in order to reduce costs, power consumption and environmental impact of video services. In the last few years, algorithms based on Neural Networks (NN) have been shown to benefit many conventional video coding modules. But while such techniques can considerably improve the compression efficiency, they usually are very computationally intensive. It is highly beneficial to simplify models learnt by NN so that meaningful insights can be exploited with the goal of deriving less complex solutions. This paper presents two ways to derive simplified intra-prediction from learnt models, and shows that these streamlined techniques can lead to efficient compression solutions.
Estimation of Rate Control Parameters for Video Coding Using CNN
Mar 13, 2020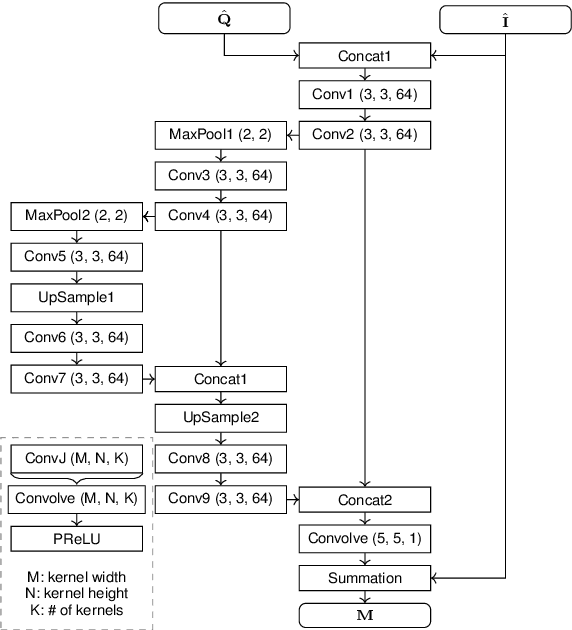
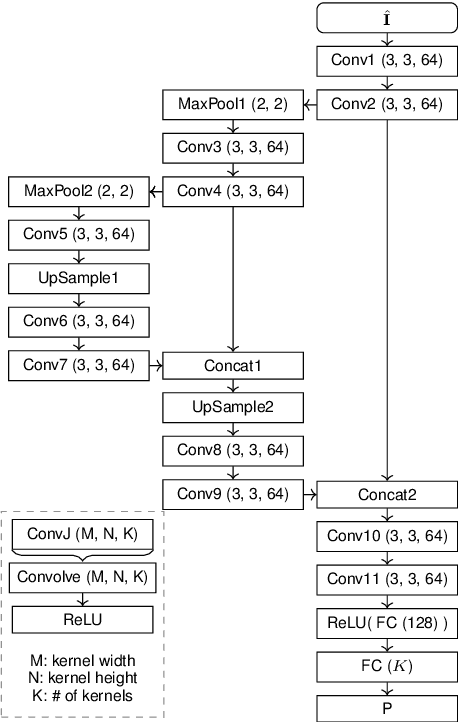
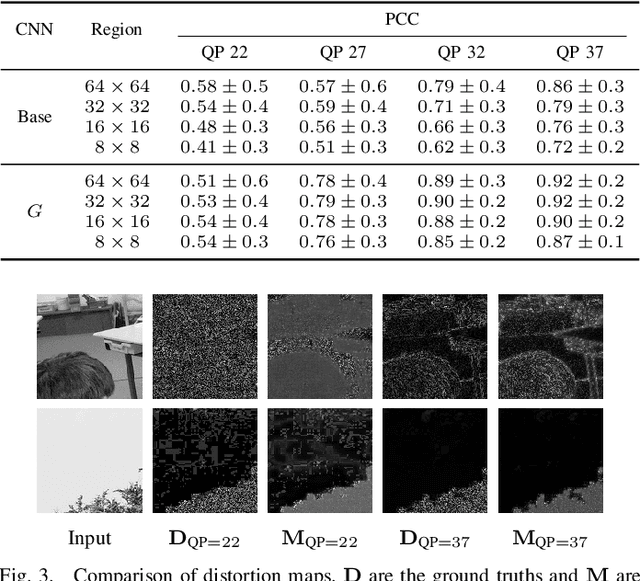
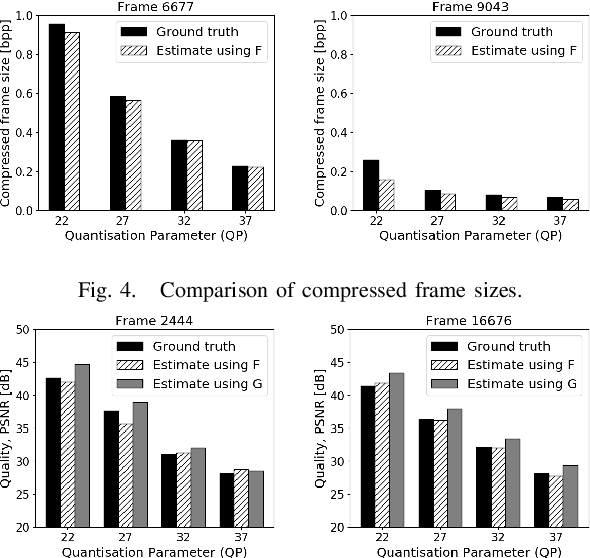
Rate-control is essential to ensure efficient video delivery. Typical rate-control algorithms rely on bit allocation strategies, to appropriately distribute bits among frames. As reference frames are essential for exploiting temporal redundancies, intra frames are usually assigned a larger portion of the available bits. In this paper, an accurate method to estimate number of bits and quality of intra frames is proposed, which can be used for bit allocation in a rate-control scheme. The algorithm is based on deep learning, where networks are trained using the original frames as inputs, while distortions and sizes of compressed frames after encoding are used as ground truths. Two approaches are proposed where either local or global distortions are predicted.
* 5 pages, 5 figures, 4 tables
Advanced Super-Resolution using Lossless Pooling Convolutional Networks
Dec 14, 2018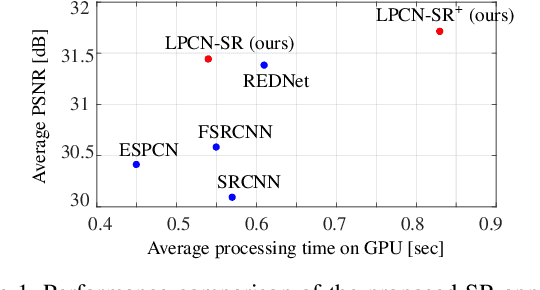
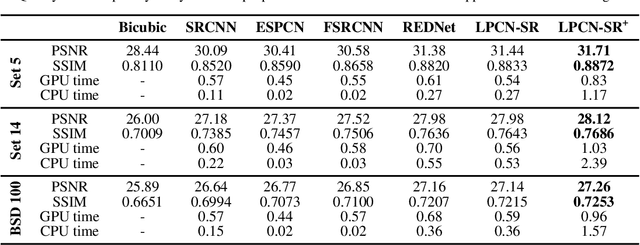
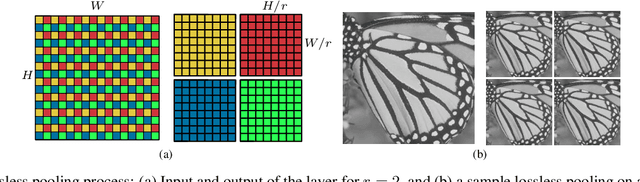
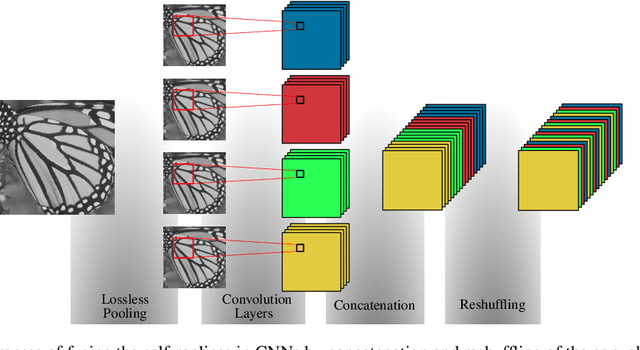
In this paper, we present a novel deep learning-based approach for still image super-resolution, that unlike the mainstream models does not rely solely on the input low resolution image for high quality upsampling, and takes advantage of a set of artificially created auxiliary self-replicas of the input image that are incorporated in the neural network to create an enhanced and accurate upscaling scheme. Inclusion of the proposed lossless pooling layers, and the fusion of the input self-replicas enable the model to exploit the high correlation between multiple instances of the same content, and eventually result in significant improvements in the quality of the super-resolution, which is confirmed by extensive evaluations.
Convolutional Neural Networks for Video Quality Assessment
Sep 26, 2018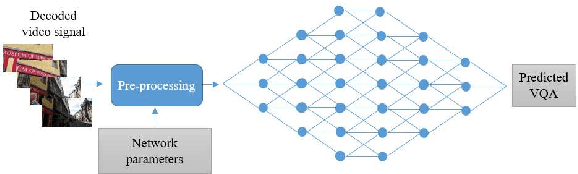


Video Quality Assessment (VQA) is a very challenging task due to its highly subjective nature. Moreover, many factors influence VQA. Compression of video content, while necessary for minimising transmission and storage requirements, introduces distortions which can have detrimental effects on the perceived quality. Especially when dealing with modern video coding standards, it is extremely difficult to model the effects of compression due to the unpredictability of encoding on different content types. Moreover, transmission also introduces delays and other distortion types which affect the perceived quality. Therefore, it would be highly beneficial to accurately predict the perceived quality of video to be distributed over modern content distribution platforms, so that specific actions could be undertaken to maximise the Quality of Experience (QoE) of the users. Traditional VQA techniques based on feature extraction and modelling may not be sufficiently accurate. In this paper, a novel Deep Learning (DL) framework is introduced for effectively predicting VQA of video content delivery mechanisms based on end-to-end feature learning. The proposed framework is based on Convolutional Neural Networks, taking into account compression distortion as well as transmission delays. Training and evaluation of the proposed framework are performed on a user annotated VQA dataset specifically created to undertake this work. The experiments show that the proposed methods can lead to high accuracy of the quality estimation, showcasing the potential of using DL in complex VQA scenarios.
Content-Adaptive Sketch Portrait Generation by Decompositional Representation Learning
Oct 04, 2017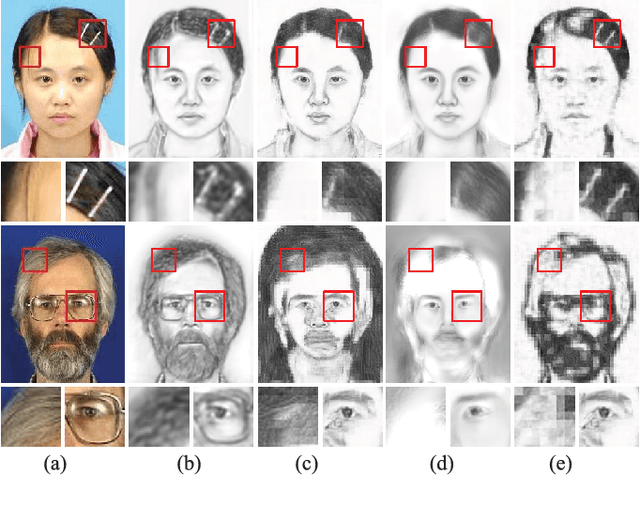



Sketch portrait generation benefits a wide range of applications such as digital entertainment and law enforcement. Although plenty of efforts have been dedicated to this task, several issues still remain unsolved for generating vivid and detail-preserving personal sketch portraits. For example, quite a few artifacts may exist in synthesizing hairpins and glasses, and textural details may be lost in the regions of hair or mustache. Moreover, the generalization ability of current systems is somewhat limited since they usually require elaborately collecting a dictionary of examples or carefully tuning features/components. In this paper, we present a novel representation learning framework that generates an end-to-end photo-sketch mapping through structure and texture decomposition. In the training stage, we first decompose the input face photo into different components according to their representational contents (i.e., structural and textural parts) by using a pre-trained Convolutional Neural Network (CNN). Then, we utilize a Branched Fully Convolutional Neural Network (BFCN) for learning structural and textural representations, respectively. In addition, we design a Sorted Matching Mean Square Error (SM-MSE) metric to measure texture patterns in the loss function. In the stage of sketch rendering, our approach automatically generates structural and textural representations for the input photo and produces the final result via a probabilistic fusion scheme. Extensive experiments on several challenging benchmarks suggest that our approach outperforms example-based synthesis algorithms in terms of both perceptual and objective metrics. In addition, the proposed method also has better generalization ability across dataset without additional training.
Deep Co-Space: Sample Mining Across Feature Transformation for Semi-Supervised Learning
Jul 28, 2017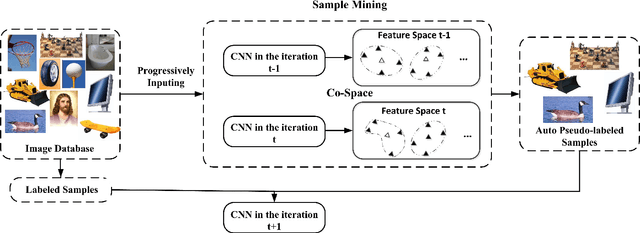
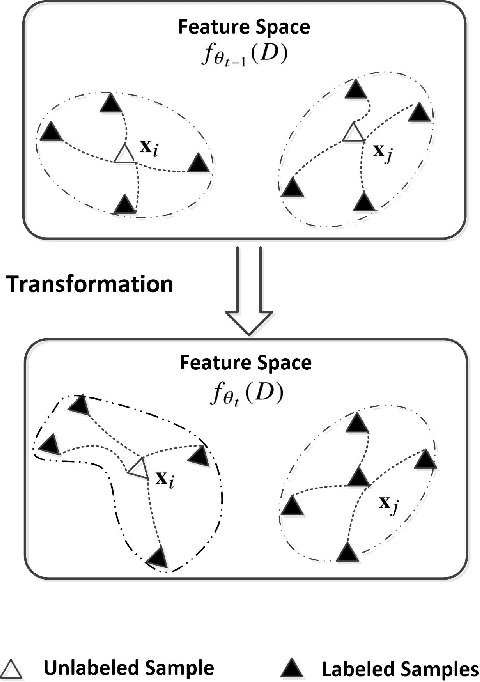


Aiming at improving performance of visual classification in a cost-effective manner, this paper proposes an incremental semi-supervised learning paradigm called Deep Co-Space (DCS). Unlike many conventional semi-supervised learning methods usually performing within a fixed feature space, our DCS gradually propagates information from labeled samples to unlabeled ones along with deep feature learning. We regard deep feature learning as a series of steps pursuing feature transformation, i.e., projecting the samples from a previous space into a new one, which tends to select the reliable unlabeled samples with respect to this setting. Specifically, for each unlabeled image instance, we measure its reliability by calculating the category variations of feature transformation from two different neighborhood variation perspectives, and merged them into an unified sample mining criterion deriving from Hellinger distance. Then, those samples keeping stable correlation to their neighboring samples (i.e., having small category variation in distribution) across the successive feature space transformation, are automatically received labels and incorporated into the model for incrementally training in terms of classification. Our extensive experiments on standard image classification benchmarks (e.g., Caltech-256 and SUN-397) demonstrate that the proposed framework is capable of effectively mining from large-scale unlabeled images, which boosts image classification performance and achieves promising results compared to other semi-supervised learning methods.