 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved CNN-based Learning of Interpolation Filters for Low-Complexity Inter Prediction in Video Coding
Jun 16, 2021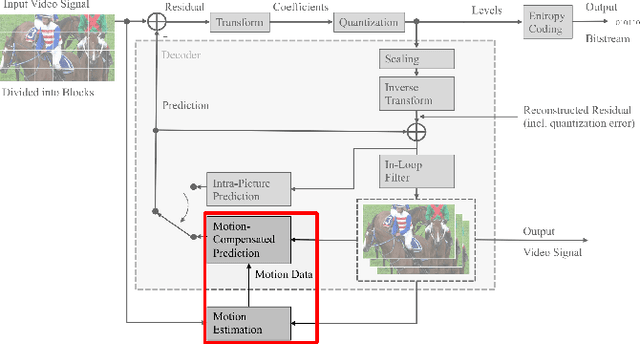
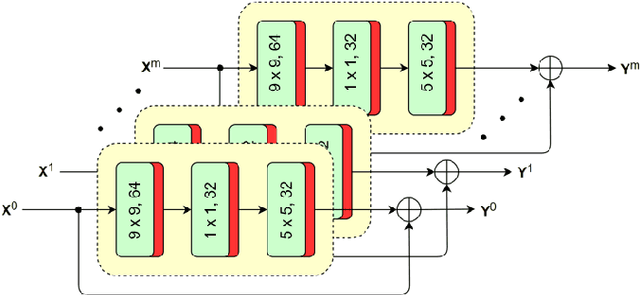
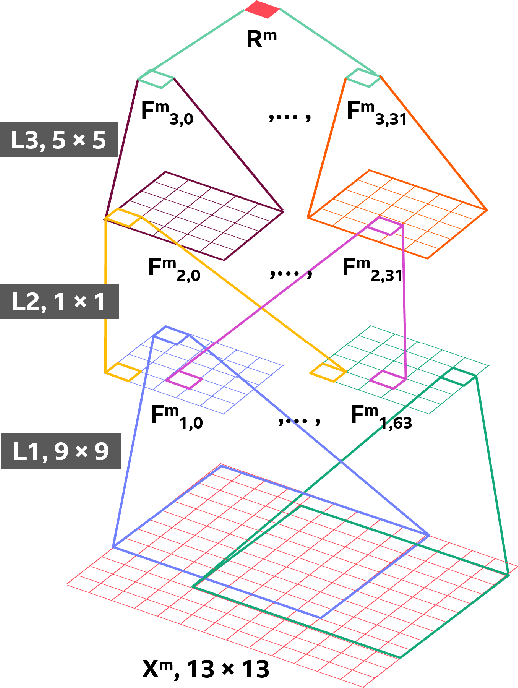
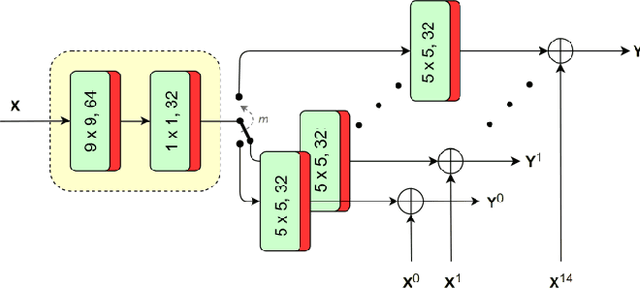
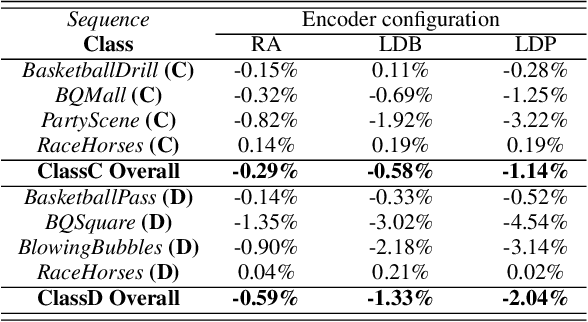
The versatility of recent machine learning approaches makes them ideal for improvement of next generation video compression solutions. Unfortunately, these approaches typically bring significant increases in computational complexity and are difficult to interpret into explainable models, affecting their potential for implementation within practical video coding applications. This paper introduces a novel explainable neural network-based inter-prediction scheme, to improve the interpolation of reference samples needed for fractional precision motion compensation. The approach requires a single neural network to be trained from which a full quarter-pixel interpolation filter set is derived, as the network is easily interpretable due to its linear structure. A novel training framework enables each network branch to resemble a specific fractional shift. This practical solution makes it very efficient to use alongside conventional video coding schemes. When implemented in the context of the state-of-the-art Versatile Video Coding (VVC) test model, 0.77%, 1.27% and 2.25% BD-rate savings can be achieved on average for lower resolution sequences under the random access, low-delay B and low-delay P configurations, respectively, while the complexity of the learned interpolation schemes is significantly reduced compared to the interpolation with full CNNs.
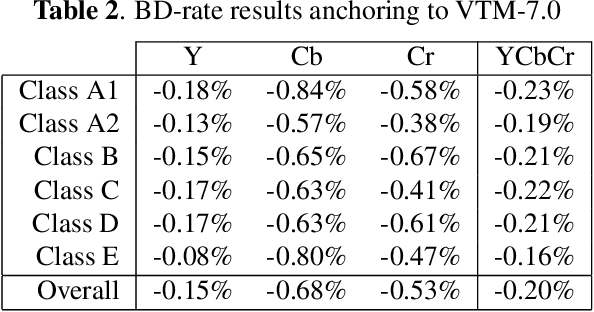
Attention-Based Neural Networks for Chroma Intra Prediction in Video Coding
Feb 09, 2021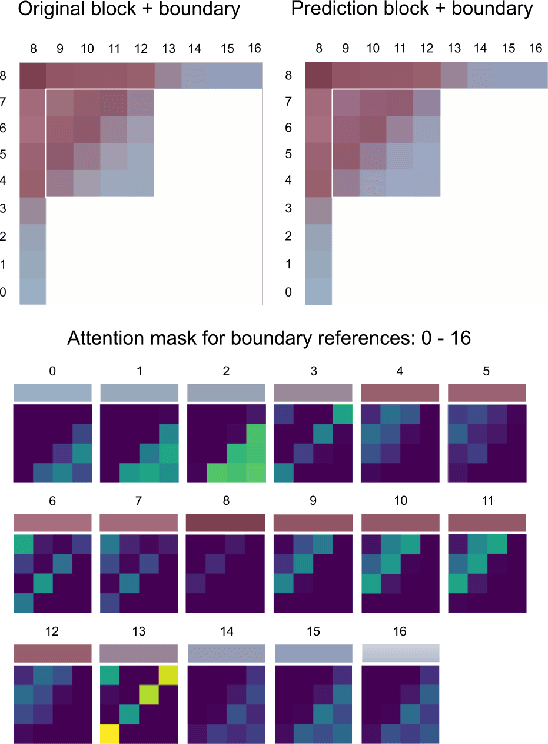
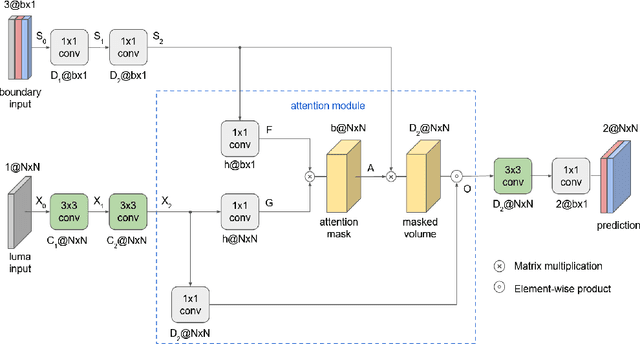
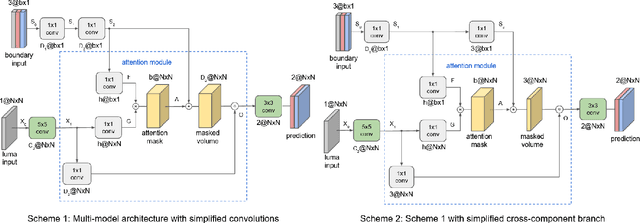
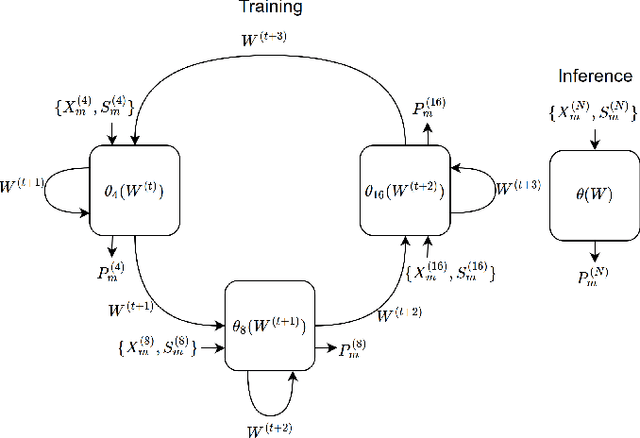
Neural networks can be successfully used to improve several modules of advanced video coding schemes. In particular, compression of colour components was shown to greatly benefit from usage of machine learning models, thanks to the design of appropriate attention-based architectures that allow the prediction to exploit specific samples in the reference region. However, such architectures tend to be complex and computationally intense, and may be difficult to deploy in a practical video coding pipeline. This work focuses on reducing the complexity of such methodologies, to design a set of simplified and cost-effective attention-based architectures for chroma intra-prediction. A novel size-agnostic multi-model approach is proposed to reduce the complexity of the inference process. The resulting simplified architecture is still capable of outperforming state-of-the-art methods. Moreover, a collection of simplifications is presented in this paper, to further reduce the complexity overhead of the proposed prediction architecture. Thanks to these simplifications, a reduction in the number of parameters of around 90% is achieved with respect to the original attention-based methodologies. Simplifications include a framework for reducing the overhead of the convolutional operations, a simplified cross-component processing model integrated into the original architecture, and a methodology to perform integer-precision approximations with the aim to obtain fast and hardware-aware implementations. The proposed schemes are integrated into the Versatile Video Coding (VVC) prediction pipeline, retaining compression efficiency of state-of-the-art chroma intra-prediction methods based on neural networks, while offering different directions for significantly reducing coding complexity.
Chroma Intra Prediction with attention-based CNN architectures
Jun 27, 2020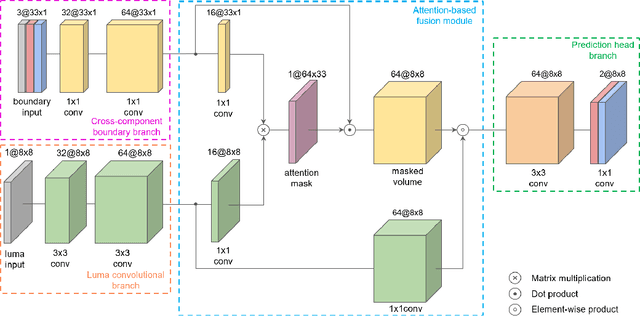

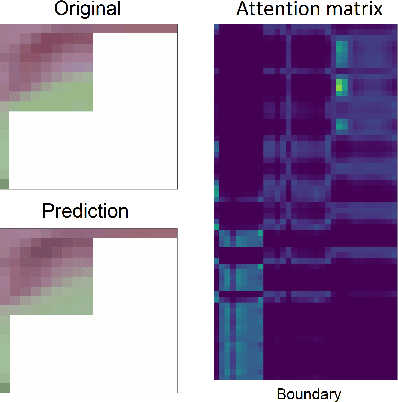
Neural networks can be used in video coding to improve chroma intra-prediction. In particular, usage of fully-connected networks has enabled better cross-component prediction with respect to traditional linear models. Nonetheless, state-of-the-art architectures tend to disregard the location of individual reference samples in the prediction process. This paper proposes a new neural network architecture for cross-component intra-prediction. The network uses a novel attention module to model spatial relations between reference and predicted samples. The proposed approach is integrated into the Versatile Video Coding (VVC) prediction pipeline. Experimental results demonstrate compression gains over the latest VVC anchor compared with state-of-the-art chroma intra-prediction methods based on neural networks.
Interpreting CNN for Low Complexity Learned Sub-pixel Motion Compensation in Video Coding
Jun 11, 2020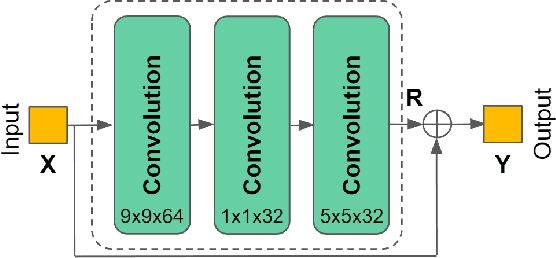
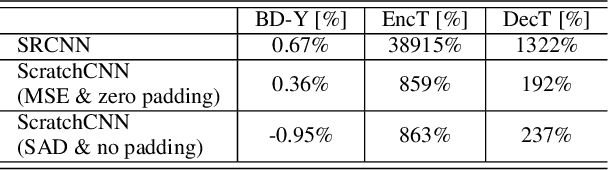
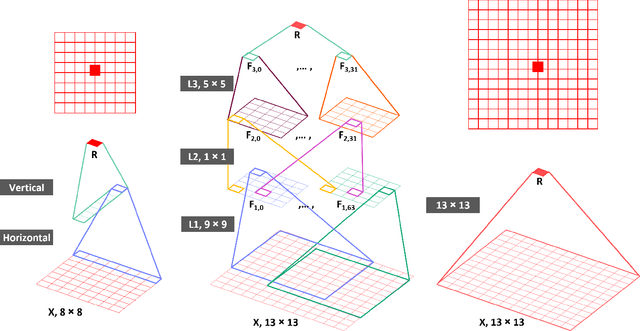
Deep learning has shown great potential in image and video compression tasks. However, it brings bit savings at the cost of significant increases in coding complexity, which limits its potential for implementation within practical applications. In this paper, a novel neural network-based tool is presented which improves the interpolation of reference samples needed for fractional precision motion compensation. Contrary to previous efforts, the proposed approach focuses on complexity reduction achieved by interpreting the interpolation filters learned by the networks. When the approach is implemented in the Versatile Video Coding (VVC) test model, up to 4.5% BD-rate saving for individual sequences is achieved compared with the baseline VVC, while the complexity of learned interpolation is significantly reduced compared to the application of full neural network.
Analytic Simplification of Neural Network based Intra-Prediction Modes for Video Compression
Apr 23, 2020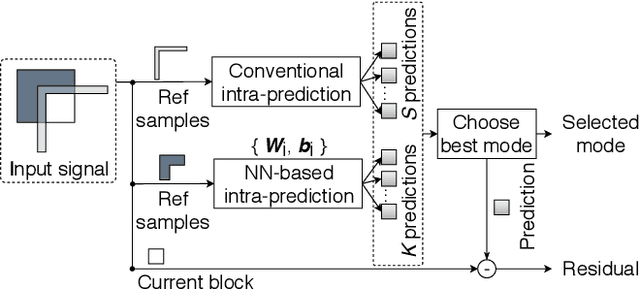
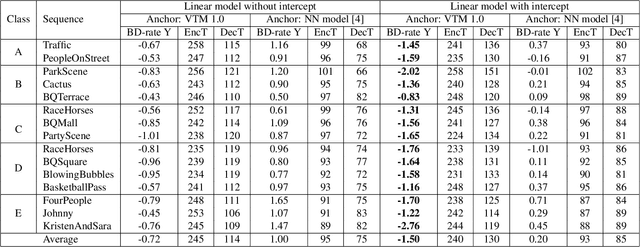
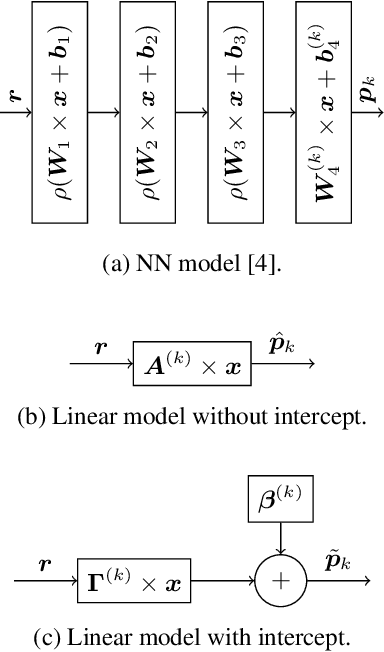
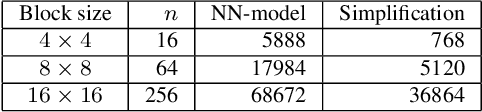
With the increasing demand for video content at higher resolutions, it is evermore critical to find ways to limit the complexity of video encoding tasks in order to reduce costs, power consumption and environmental impact of video services. In the last few years, algorithms based on Neural Networks (NN) have been shown to benefit many conventional video coding modules. But while such techniques can considerably improve the compression efficiency, they usually are very computationally intensive. It is highly beneficial to simplify models learnt by NN so that meaningful insights can be exploited with the goal of deriving less complex solutions. This paper presents two ways to derive simplified intra-prediction from learnt models, and shows that these streamlined techniques can lead to efficient compression solutions.
Estimation of Rate Control Parameters for Video Coding Using CNN
Mar 13, 2020
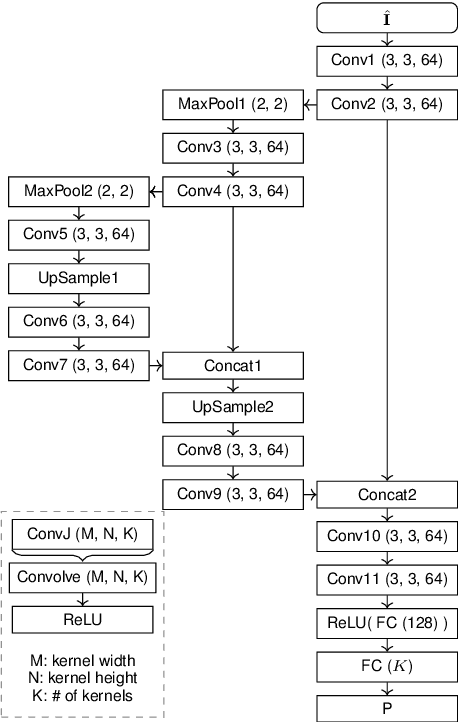
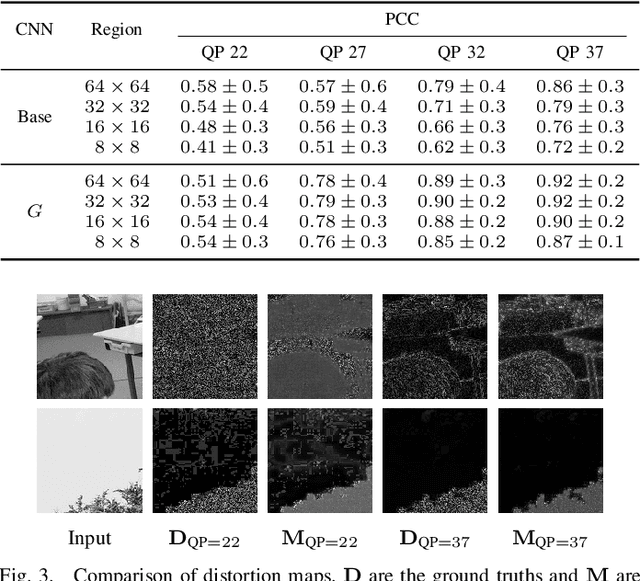
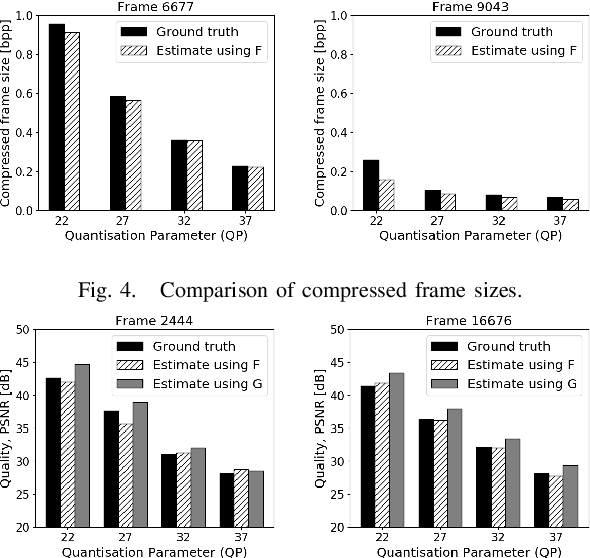
Rate-control is essential to ensure efficient video delivery. Typical rate-control algorithms rely on bit allocation strategies, to appropriately distribute bits among frames. As reference frames are essential for exploiting temporal redundancies, intra frames are usually assigned a larger portion of the available bits. In this paper, an accurate method to estimate number of bits and quality of intra frames is proposed, which can be used for bit allocation in a rate-control scheme. The algorithm is based on deep learning, where networks are trained using the original frames as inputs, while distortions and sizes of compressed frames after encoding are used as ground truths. Two approaches are proposed where either local or global distortions are predicted.
* 5 pages, 5 figures, 4 tables
Convolutional Neural Networks for Video Quality Assessment
Sep 26, 2018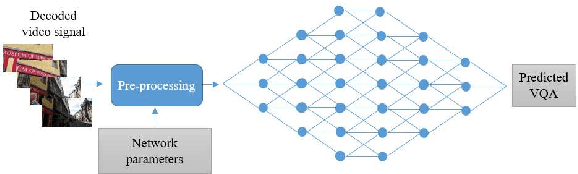
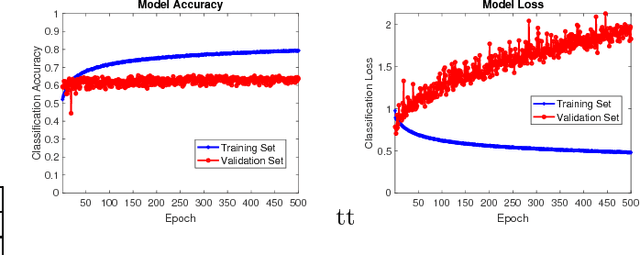


Video Quality Assessment (VQA) is a very challenging task due to its highly subjective nature. Moreover, many factors influence VQA. Compression of video content, while necessary for minimising transmission and storage requirements, introduces distortions which can have detrimental effects on the perceived quality. Especially when dealing with modern video coding standards, it is extremely difficult to model the effects of compression due to the unpredictability of encoding on different content types. Moreover, transmission also introduces delays and other distortion types which affect the perceived quality. Therefore, it would be highly beneficial to accurately predict the perceived quality of video to be distributed over modern content distribution platforms, so that specific actions could be undertaken to maximise the Quality of Experience (QoE) of the users. Traditional VQA techniques based on feature extraction and modelling may not be sufficiently accurate. In this paper, a novel Deep Learning (DL) framework is introduced for effectively predicting VQA of video content delivery mechanisms based on end-to-end feature learning. The proposed framework is based on Convolutional Neural Networks, taking into account compression distortion as well as transmission delays. Training and evaluation of the proposed framework are performed on a user annotated VQA dataset specifically created to undertake this work. The experiments show that the proposed methods can lead to high accuracy of the quality estimation, showcasing the potential of using DL in complex VQA scenarios.