 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding of volumetric content with MIV using VVC subpictures
Jun 06, 2022
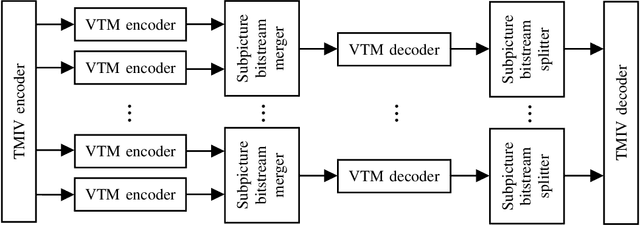


Storage and transport of six degrees of freedom (6DoF) dynamic volumetric visual content for immersive applications requires efficient compression. ISO/IEC MPEG has recently been working on a standard that aims to efficiently code and deliver 6DoF immersive visual experiences. This standard is called the MIV. MIV uses regular 2D video codecs to code the visual data. MPEG jointly with ITU-T VCEG, has also specified the VVC standard. VVC introduced recently the concept of subpicture. This tool was specifically designed to provide independent accessibility and decodability of sub-bitstreams for omnidirectional applications. This paper shows the benefit of using subpictures in the MIV use-case. While different ways in which subpictures could be used in MIV are discussed, a particular case study is selected. Namely, subpictures are used for parallel encoding and to reduce the number of decoder instances. Experimental results show that the cost of using subpictures in terms of bitrate overhead is negligible (0.1% to 0.4%), when compared to the overall bitrate. The number of decoder instances on the other hand decreases by a factor of two.
* 6 pages, 3 figures
Towards Transparent Application of Machine Learning in Video Processing
May 27, 2021
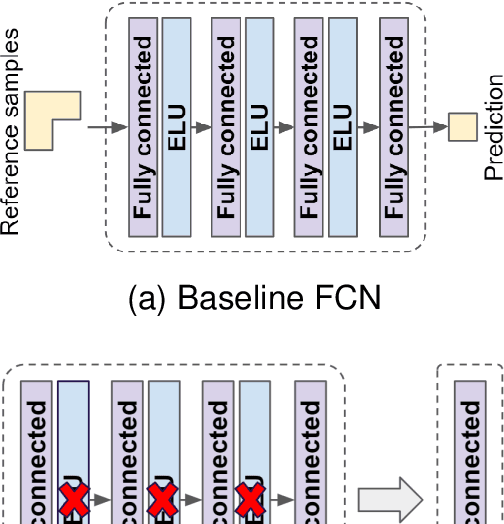
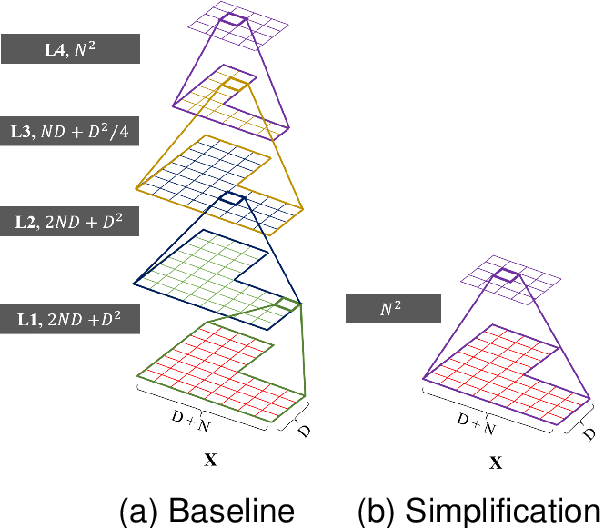
Machine learning techniques for more efficient video compression and video enhancement have been developed thanks to breakthroughs in deep learning. The new techniques, considered as an advanced form of Artificial Intelligence (AI), bring previously unforeseen capabilities. However, they typically come in the form of resource-hungry black-boxes (overly complex with little transparency regarding the inner workings). Their application can therefore be unpredictable and generally unreliable for large-scale use (e.g. in live broadcast). The aim of this work is to understand and optimise learned models in video processing applications so systems that incorporate them can be used in a more trustworthy manner. In this context, the presented work introduces principles for simplification of learned models targeting improved transparency in implementing machine learning for video production and distribution applications. These principles are demonstrated on video compression examples, showing how bitrate savings and reduced complexity can be achieved by simplifying relevant deep learning models.
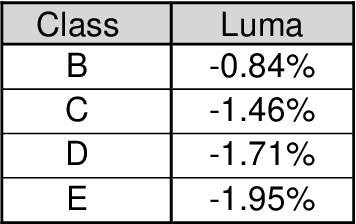
Analytic Simplification of Neural Network based Intra-Prediction Modes for Video Compression
Apr 23, 2020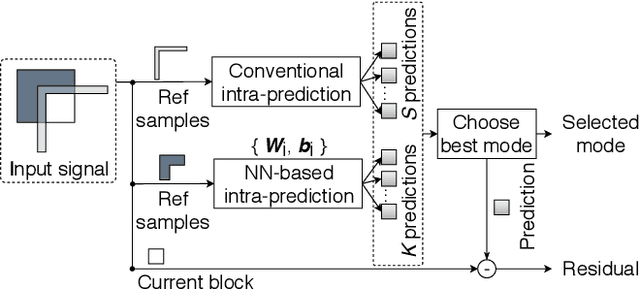
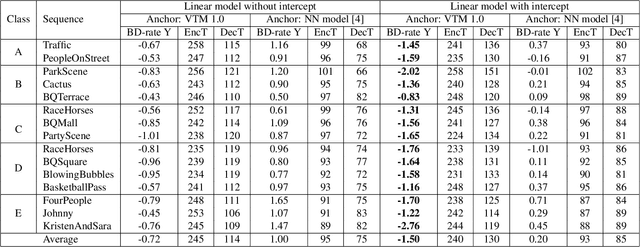
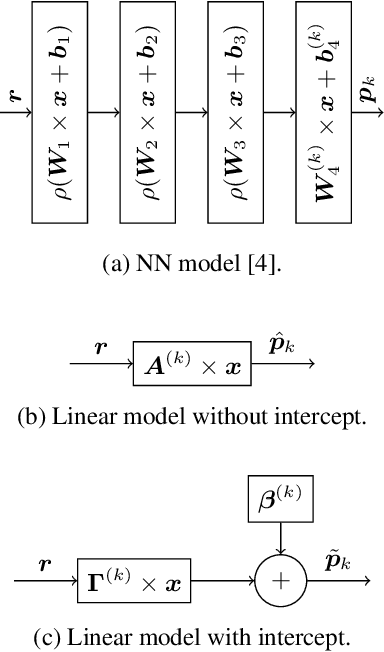
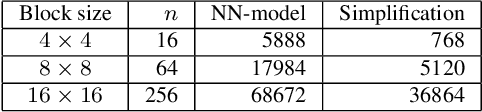
With the increasing demand for video content at higher resolutions, it is evermore critical to find ways to limit the complexity of video encoding tasks in order to reduce costs, power consumption and environmental impact of video services. In the last few years, algorithms based on Neural Networks (NN) have been shown to benefit many conventional video coding modules. But while such techniques can considerably improve the compression efficiency, they usually are very computationally intensive. It is highly beneficial to simplify models learnt by NN so that meaningful insights can be exploited with the goal of deriving less complex solutions. This paper presents two ways to derive simplified intra-prediction from learnt models, and shows that these streamlined techniques can lead to efficient compression solutions.
Estimation of Rate Control Parameters for Video Coding Using CNN
Mar 13, 2020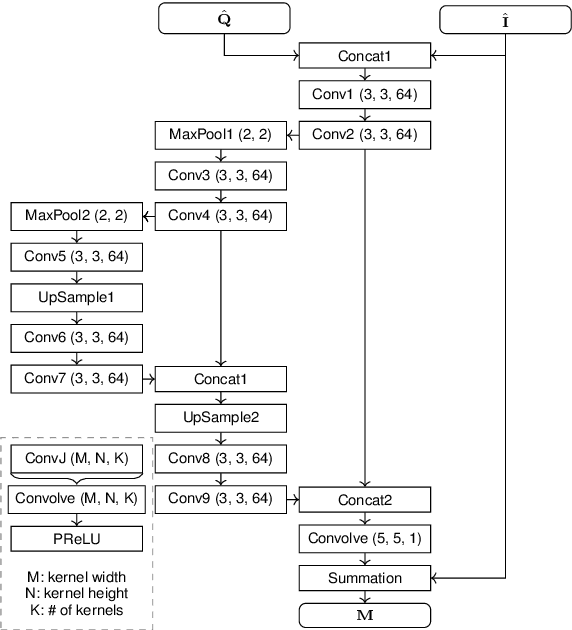
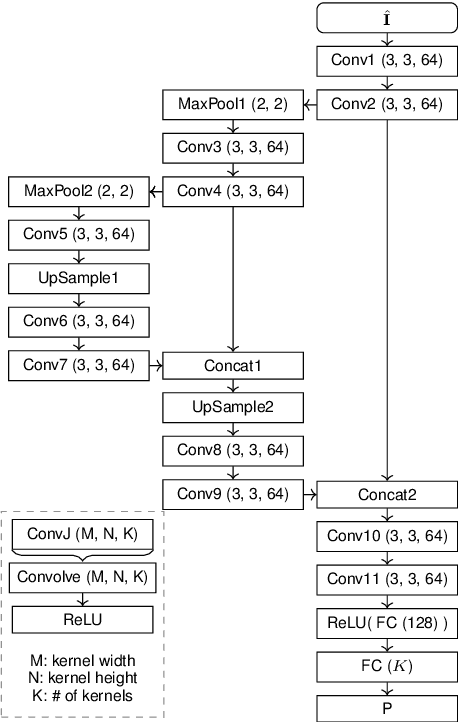
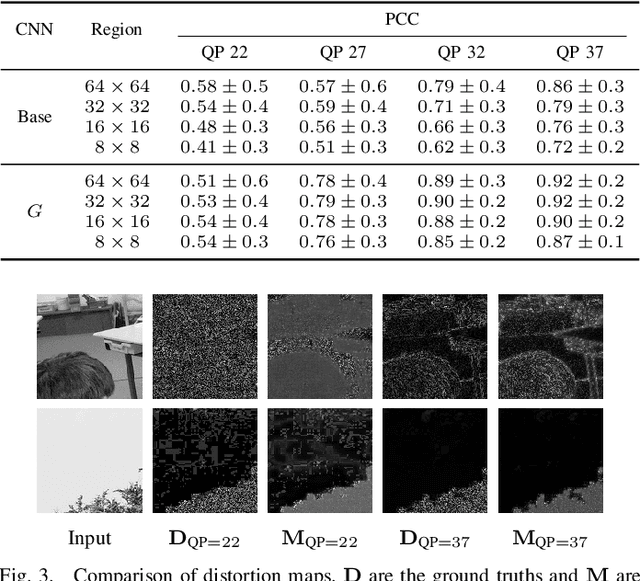
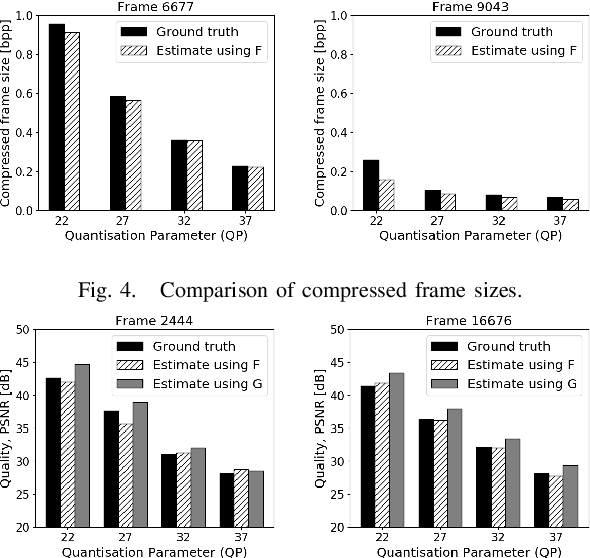
Rate-control is essential to ensure efficient video delivery. Typical rate-control algorithms rely on bit allocation strategies, to appropriately distribute bits among frames. As reference frames are essential for exploiting temporal redundancies, intra frames are usually assigned a larger portion of the available bits. In this paper, an accurate method to estimate number of bits and quality of intra frames is proposed, which can be used for bit allocation in a rate-control scheme. The algorithm is based on deep learning, where networks are trained using the original frames as inputs, while distortions and sizes of compressed frames after encoding are used as ground truths. Two approaches are proposed where either local or global distortions are predicted.
* 5 pages, 5 figures, 4 tables