 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Adaptive Sketch Portrait Generation by Decompositional Representation Learning
Oct 04, 2017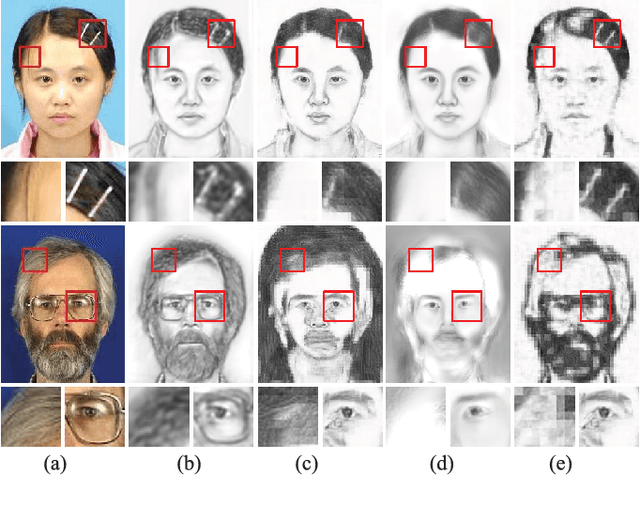



Sketch portrait generation benefits a wide range of applications such as digital entertainment and law enforcement. Although plenty of efforts have been dedicated to this task, several issues still remain unsolved for generating vivid and detail-preserving personal sketch portraits. For example, quite a few artifacts may exist in synthesizing hairpins and glasses, and textural details may be lost in the regions of hair or mustache. Moreover, the generalization ability of current systems is somewhat limited since they usually require elaborately collecting a dictionary of examples or carefully tuning features/components. In this paper, we present a novel representation learning framework that generates an end-to-end photo-sketch mapping through structure and texture decomposition. In the training stage, we first decompose the input face photo into different components according to their representational contents (i.e., structural and textural parts) by using a pre-trained Convolutional Neural Network (CNN). Then, we utilize a Branched Fully Convolutional Neural Network (BFCN) for learning structural and textural representations, respectively. In addition, we design a Sorted Matching Mean Square Error (SM-MSE) metric to measure texture patterns in the loss function. In the stage of sketch rendering, our approach automatically generates structural and textural representations for the input photo and produces the final result via a probabilistic fusion scheme. Extensive experiments on several challenging benchmarks suggest that our approach outperforms example-based synthesis algorithms in terms of both perceptual and objective metrics. In addition, the proposed method also has better generalization ability across dataset without additional training.